Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick. Segment Anything.
- Overview
- Performance
- Try it by yourself with one line of code
We implemente the segment anything with the PaddlePaddle framework. Segment Anything Model (SAM) is a new task, model, and dataset for image segmentation. It can produce high quality object masks from different types of prompts including points, boxes, masks and text. Further, SAM can generate masks for all objects in whole image. It built a largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. SAM has impressive zero-shot performance on a variety of tasks, even often competitive with or even superior to prior fully supervised results.
We provide the pretrained model parameters of PaddlePaddle format, including vit_b, vit_l and vit_h.

-
Install PaddlePaddle and relative environments based on the installation guide.
-
Install PaddleSeg based on the reference.
-
Clone the PaddleSeg reporitory:
git clone https://github.com/PaddlePaddle/PaddleSeg.git cd PaddleSeg pip install -r requirements.txt -
Download the example image to
contrib/SegmentAnything/examples, and the file structure is as following:wget https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
PaddleSeg/contrib ├── SegmentAnything │ ├── examples │ │ └── cityscapes_demo.png │ ├── segment_anything │ └── scripts
In this step, we start a gradio service with the following scrip on local machine and you can try out our project with your own images.
-
Run the following script:
python scripts/amg_paddle.py --model-type [vit_l/vit_b/vit_h] # default is vit_hNote:
- There are three model options for you, vit_b, vit_l and vit_h, represent vit_base, vit_large and vit_huge. Large model is more accurate and also slower. You can choose the model size based on your device.
- The test result shows that vit_h needs 16G video memory and needs around 10s to infer an image on V100.
-
Open the webpage on your localhost:
http://0.0.0.0:8017 -
Try it out by clear and upload the test image! Our example looks like:
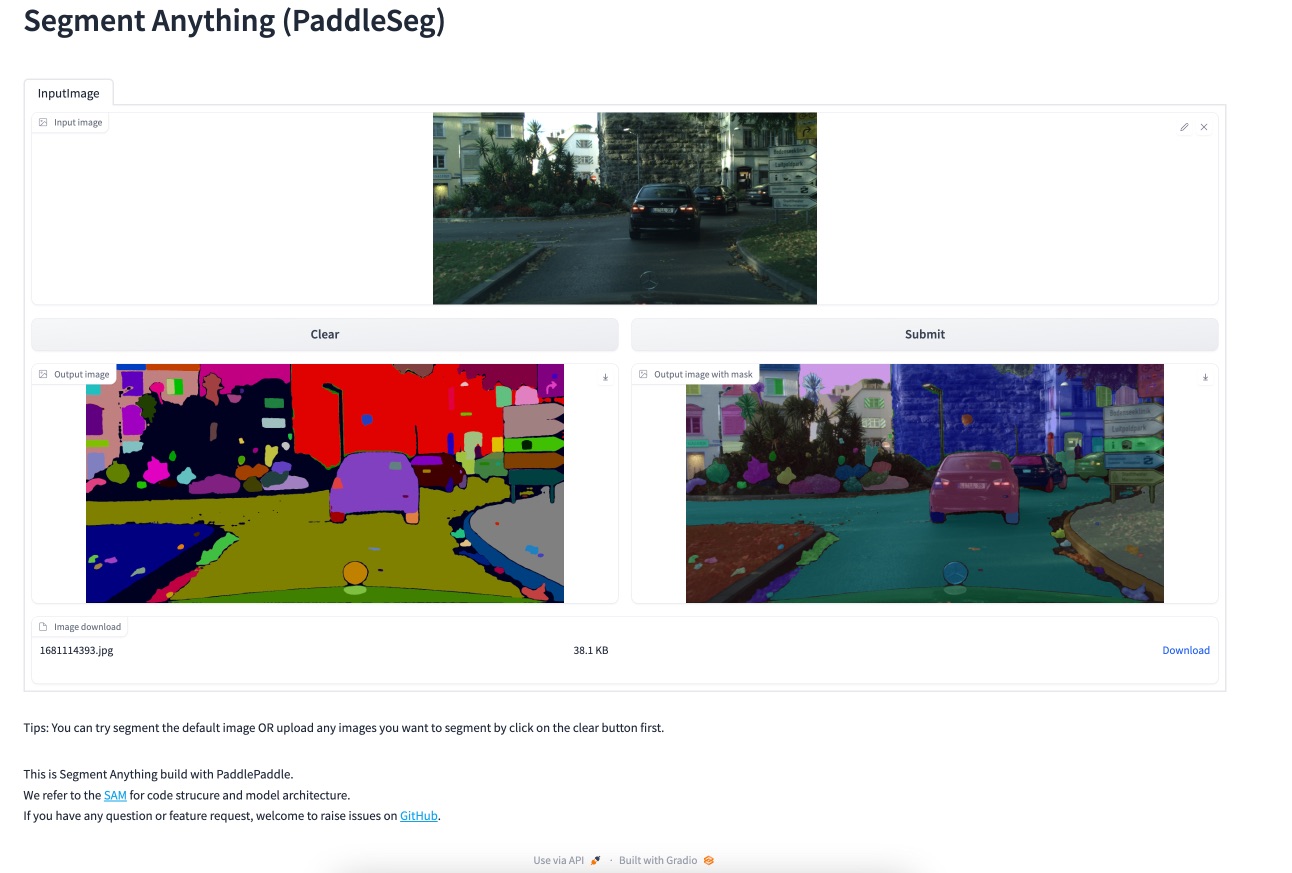
You can run the following commands to produce masks from different types of prompts including points, boxes, and masks, as follow:
- Box prompt
python scripts/promt_predict.py --input_path xxx.png --box_prompt 1050 370 1500 700 --model-type [vit_l/vit_b/vit_h] # default is vit_h- Point prompt
python scripts/promt_predict.py --input_path xxx.png --point_prompt 1200 450 --model-type [vit_l/vit_b/vit_h] # default is vit_h- Mask prompt
python scripts/promt_predict.py --input_path xxx.png --mask_prompt xxx.png --model-type [vit_l/vit_b/vit_h] # default is vit_hNote:
- mask_prompt is the path of a binary image.