Qbeast-spark is built on top of Delta Lake to enable multidimensional indexing and efficient sampling.
We extend the Delta Lake format by storing additional index metadata such as Revision, CubeId, and Blocks in the /_delta_log. They are created during the write operation and are consulted during the read operation to reconstruct the latest state of the index.
To address many issues with a two-tier data lake + warehouse architecture, open table formats such as Delta Lake use transaction logs on top of object stores for metadata management and to achieve primarily ACID properties and table versioning.
A transaction log (_delta_log/) in Delta Lake contains information about what objects comprise a table and are stored in the same object store.
Actions such as Add and Remove are stored in JSON or parquet files in chronological order and are accessed before any I/O operation to a snapshot of the table.
The actual data objects are stored in parquet format.
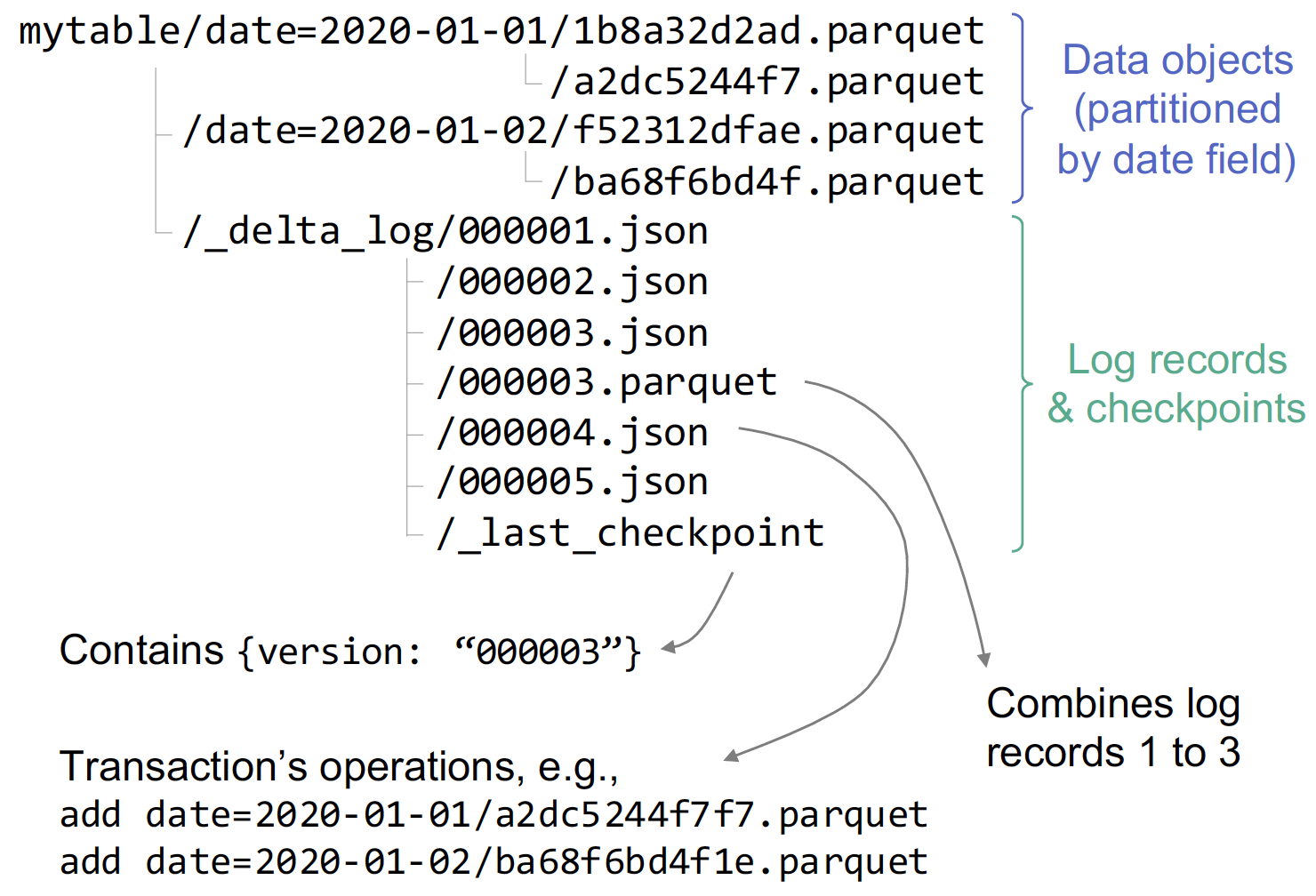
Following each write transaction, a new log file is created. Table-level transaction atomicity is achieved by following the put-if-absent protocol for log file naming—only one client can create a log file with a particular name when multiple users attempt it.
Each action record in the log has a field modificationTime as timestamp, which forms the basis for snapshot isolation for read transactions. Check here for more details about Delta Lake logs.
The Qbeast format extends the Delta Lake Format by adding Index Metadata to the delta log.
Qbeast organizes the table data into different Revisions (OTrees, an enhanced version of QuadTrees) that are characterized by various parameters:
| Term | Description | Example Value |
|---|---|---|
indexing columns |
the columns that are indexed | price, product_name |
column stats |
the min-max values, quantiles of the indexed columns | (price_min, price_max) |
column transformers |
the transformation applied to the indexed columns | linear, hash |
desired cube size |
the capacity of tree nodes | 5000 |
Here, the data is indexed by the columns price and product_name with a desired cube size of 5000.
We map the indexed columns to a multidimensional space, where each dimension is normalized to the range [0, 1].
The price column is transformed linearly using a min/max scaler, and the product_name column is hashed.
The data is organized into different tree nodes (cubes) according to their position within the space, as well as their weight.
The coordinates of a record determine the space partition to which it belongs, and the record's weight is randomly assigned and dictates its position within the same tree branch.
The transformers and transformations determine how records are indexed:
| Type | Transformer | Transformation | Description | Example Input Column Stats |
|---|---|---|---|---|
| linear | LinearTransformer | LinearTransformation | Applies a min/max scaler to the column values | Optional: {"col_1_min":0, "col_1_max":1} |
| linear | LinearTransformer | IdentityTransformation | Maps column values to 0 | None |
| quantile(string) | CDFStringQuantilesTransformer | CDFStringQuantilesTransformation | Maps column values to their relative, sorted positions | Required: {"col_1_quantiles": ["a", "b", "c"]} |
| quantile(numeric) | CDFNumericQuantilesTransformer | CDFNumericQuantilesTransformation | Maps column values to their relative, sorted positions | Required: {"col_1_quantiles": [1,2,3,4,5]} |
| hash | HashTransformer | HashTransformation | Maps column values to their Murmur hash | None |
Example:
df
.write
.mode("overwrite")
.format("qbeast")
.option("cubeSize", 5000)
.option("columnsToIndex", "price:linear,product_name:quantile,user_id:hash")
.option("columnStats", """{"price_min":0, "price_max":1000, "product_name_quantiles":["product_1","product_100","product_3223"]""")
.save("/tmp/qb-testing")Here, we are writing a DataFrame to a Qbeast table with the columns price, product_name, and user_id indexed.
The price column is linearly transformed with a min/max range of [0, 1000].
The product_name column is transformed using the following quantiles: ["product_1", "product_100", "product_3223"].
The values from the user_id column are hashed.
If we don't provide the price min/max here, the system will calculate the min/max values from the input data.
IdentityTransformation will be used if the price column has only one value.
If appending a new DataFrame df2 to the same table, and its values for any indexed column exceed the range of their corresponding existing transformations, the system will create a new revision with the extended Transformations.
For example, adding a new batch of data with price values ranging from [1000, 2000] will create a new revision with a price min/max range of [0, 2000].
Revision information are stored in the _delta_log in the forms of metadata.configuration:
{
"metaData": {
"id": "aa43874a-9688-4d14-8168-e16088641fdb",
...
"configuration": {
"qbeast.lastRevisionID": "1",
"qbeast.revision.1": "{\"revisionID\":1,\"timestamp\":1637851757680,\"tableID\":\"/tmp/example-table\",\"desiredCubeSize\":5000,\"columnTransformers\":..}",
...
},
...
}Details of the first Revision:
{
"revisionID": 1,
"timestamp": 1637851757680,
"tableID": "/tmp/example-table/",
"desiredCubeSize": 5000,
"columnTransformers": [
{
"className": "io.qbeast.core.transform.LinearTransformer",
"columnName": "price",
"dataType": "DoubleDataType"
},
{
"className": "io.qbeast.core.transform.CDFStringQuantilesTransformer",
"columnName": "product_name"
},
{
"className": "io.qbeast.core.transform.HashTransformer",
"columnName": "user_id",
"dataType": "IntegerDataType"
}
],
"transformations": [
{
"className": "io.qbeast.core.transform.LinearTransformation",
"minNumber": 0,
"maxNumber": 100,
"nullValue": 43,
"orderedDataType": "DoubleDataType"
},
{
"className": "io.qbeast.core.transform.CDFStringQuantilesTransformation",
"quantiles": [
"product_1",
"product_100",
"product_3223"
]
},
{
"className": "io.qbeast.core.transform.HashTransformation",
"nullValue": -1809672334
}
]
}
Each Revision corresponds to an OTree index with a space partition defined by its column transformations.
The data from each Revision are organized by cubes - nodes of the OTree index.
Each cube contains blocks of data written in different instances.
Blocks from different cubes can be written in the same file.
The list of Blocks contained in a file can be found in the tags attribute of their AddFiles action.
AddFiles in Delta Lake marks the addition of new files to the table. We use its tags attribute to store the metadata of the data Blocks written in the files.
{"tags": {
"revision": "1",
"blocks": [
{
"cube": "w",
"minWeight": 2,
"maxWeight": 3,
"elementCount": 4,
"replicated": false
},
{
"cube": "wg",
"minWeight": 5,
"maxWeight": 6,
"elementCount": 7,
"replicated": false
}
]
}}Here, we have two blocks of data(w and wg) written in the file, each with a different weight range and number of elements.
The introduction of the Staging Revision enables reading and writing tables in a hybrid qbeast + delta state.
The non-qbeast AddFiles are considered part of this staging revision, and all belong to the root.
Its RevisionID is fixed to stagingID = 0, and it has EmptyTransformers and EmptyTransformations.
It is automatically created during the first write or overwriting a table using qbeast.
For a table that is entirely written in delta or parquet, we can use the ConvertToQbeastCommand to create this Revision:
import io.qbeast.spark.internal.commands.ConvertToQbeastCommand
val path = "/pathToTable/"
val tableIdentifier = s"parquet.`$path`"
val columnsToIndex = Seq("col1", "col2", "col3")
val desiredCubeSize = 50000
ConvertToQbeastCommand(tableIdentifier, columnsToIndex, desiredCubeSize).run(spark)
val qTable = spark.read.format("qbeast").load(path)By doing so, we also enable subsequent appends using either delta or qbeast.
Conversion on a partitioned table is not supported.
The Optimize operation rearranges the data according to the index structure, improving the data layout and query performance. It regroups the data according to their cube, reducing the number of files read when a particular cube space is queried. The user can specify the Revision to optimize, or the files to optimize.
It can be helpful to optimize by specific RevisionIDs when we have an incremental appends scenario.
As an example, imagine you have a table called city_taxi that contains data about the location of taxi stations in one or more countries.
An initial commit C1 is inserting data about taxis in France into the table, assuming a column called city_name is indexed with Qbeast.
With this first commit, C1, we add F1, F2, and F3 files.
The first commit C1 creates a revision R1. The space contained on revision R1 is
[city_name_min = France, city_name_max = France]
A second commit,, C2,, adds data about German cities, expanding the cardinality of the city_name column.
This commit adds four files: F4, F5, F6, and F7.
Now, C2 creates revision R2. The space of the revision R2 is
[city_name_min = France, city_name_max = Germany]
Revision R2 is necessary because it expands the cardinality of the city name dimension, which impacts the index as the range of values changes.
Consequently, optimization can be performed over either Revision.
Running optimize over R1 would rewrite (only rearranging data) files F1, F2 and F3.
These are the 3 ways of executing the optimize operation:
qbeastTable.optimize() // Optimizes the last Revision Available.
// This does NOT include the previous Revision optimizations.
qbeastTable.optimize(2L) // Optimizes the Revision number 2.
qbeastTable.optimize(Seq("file1", "file2")) // Optimizes the specific filesIf you want to optimize the entire table, you must loop through revisions:
val revisionIDs = qbeastTable.allRevisionIDs() // Get all the RevisionIDs available in the table.
revisionIDs.foreach(id =>
qbeastTable.optimize(id)
)Note that Revision ID number 0 is reserved for Staging Area (non-indexed files). This ensures compatibility with underlying table formats.
Analyze and Replication operations are NOT available from version 0.6.0. Read all the reasoning and changes on the Qbeast Format 0.6.0 document.