原创公众号:
bigsai,码字不易,如有帮助,记得三联!
在个人的专栏中,其他排序陆陆续续都已经写了,而堆排序迟迟没有写,在国庆假期的尾声,把堆排序也写一写。
插入类排序—(折半)插入排序、希尔排序 交换类排序—冒泡排序、快速排序手撕图解 归并类排序—归并排序(逆序数问题) 计数排序引发的围观风波——一种O(n)的排序 两分钟搞懂桶排序
对于常见的快排、归并这些O(nlogn)的排序算法,我想大部分人可能很容易搞懂,但是堆排序大部分人可能比较陌生,或许在Java的comparator接口中可能了解一点。但堆排序在应用中比如优先队列此类维护动态数据效率比较高,有着非常广泛的应用。
而堆排序可以拆分成堆和排序,其中你可能对堆比较陌生,对排序比较熟悉,下面就带你彻底了解相关内容。

什么是堆?
谈起堆,很多人第一联想到的是土堆,而在数据结构中这种土堆与完全二叉树更像,而堆就是一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树(完全)的数组对象。且总是满足以下规则:
- 堆总是一棵完全二叉树
- 每个节点总是大于(或小于)它的孩子节点。
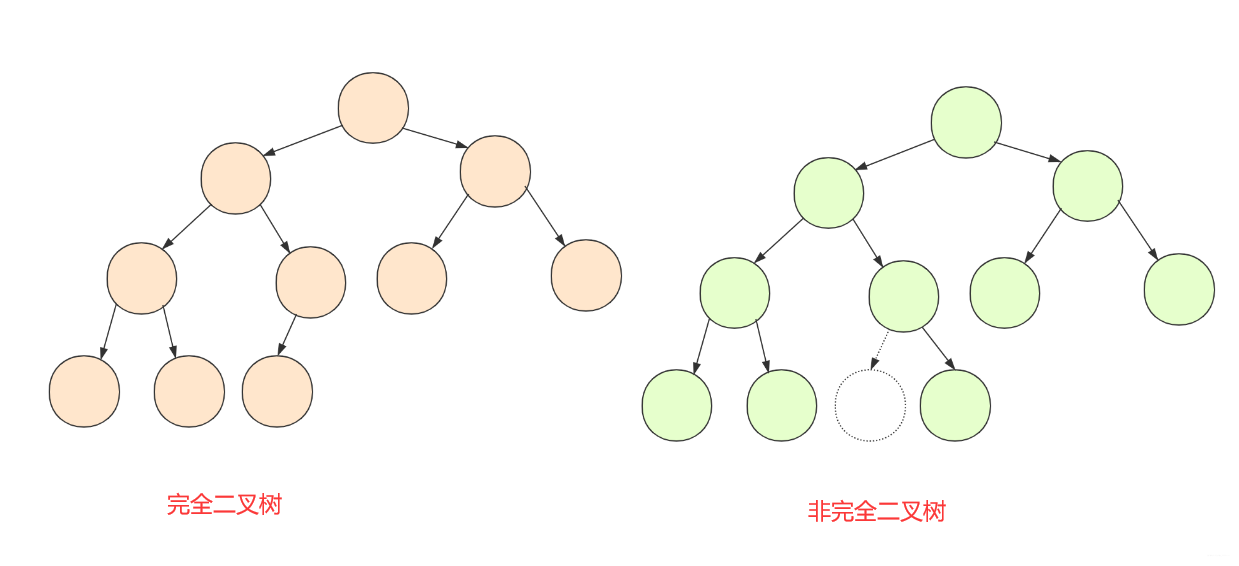
完全二叉树
我想什么是完全二叉树大部分人也是知道:最后一层以上都是满的,最后一层节点从左到右可以排列(有任何空缺即不满足完全二叉树)。
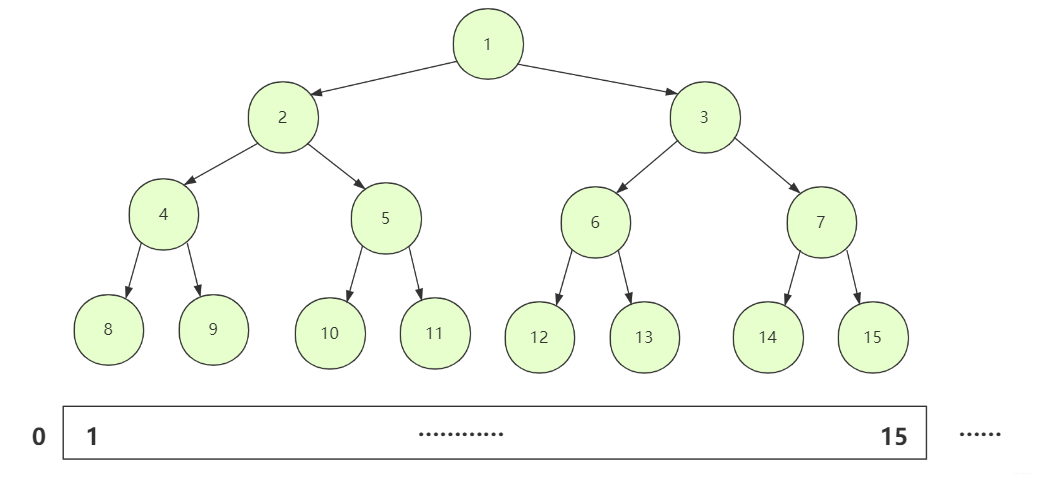
我们正常在构造一棵二叉树的时候通常采用链式left,right节点,但其实二叉树的表示方式用数组也可以实现,只不过普通的二叉树如果用数组储存可能空间利用 效率会很低而很少采用,但我们的堆是一颗完全二叉树。使用数组储存空间使用效率也比较高,所以在形式上我们把这个数组看成对应的完全二叉树,而操作上可以直接操作数组也比较方便。
大根堆 VS 小根堆 上面还有一点就是在这个完全二叉树中所有节点均大于(或小于)它的孩子节点,所以这里就分为两种情况
- 如果所有节点大于孩子节点值,那么这个堆叫做大根堆,堆的最大值在根节点。
- 如果所有节点小于孩子节点值,那么这个堆叫做小根堆,堆的最小值在根节点。

通过上面的介绍,我想你对堆应该有了一定的认识,堆排序肯定是借助堆实现的某种排序,其实堆排序的整体思路也很简单,就是
- 构建堆,取堆顶为最小(最大)。
- 将剩下的元素重新构建一个堆,取堆顶,一直到元素取完为止。
如果给一个无序的序列,首先要给它建成一个堆,我们如何实现这个操作呢?以下拿一个小根堆为例进行分析。
对于二叉树(数组表示),我们从下往上进行调整,从第一个非叶子节点开始向前调整,对于调整的规则如下:
①对于小根堆,当前节点与左右孩子比较,如果均小于左右孩子节点,那么它本身就是一个小根堆,它不需要做任何改变,如果左右有孩子节点比它还小,那么就要和最小的那个进行替换。
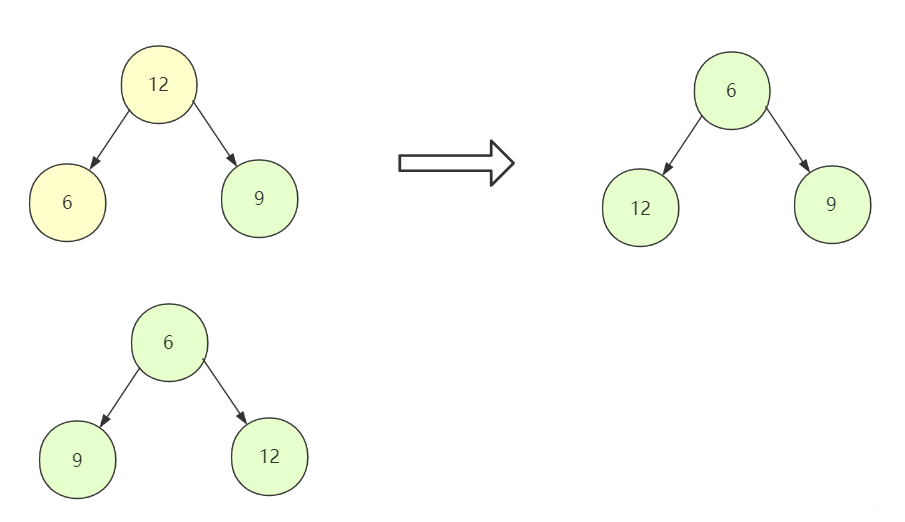

一个大根堆建立过程也是一样的:

上面的一个堆建造完毕之后,我们怎么去利用这个堆实现排序呢?答案也是很简单的,我们知道堆有一个特性就是堆顶是最小(或最大),而我们建造这个如果去除第一个元素,剩余左右孩子依然满足堆的性质。
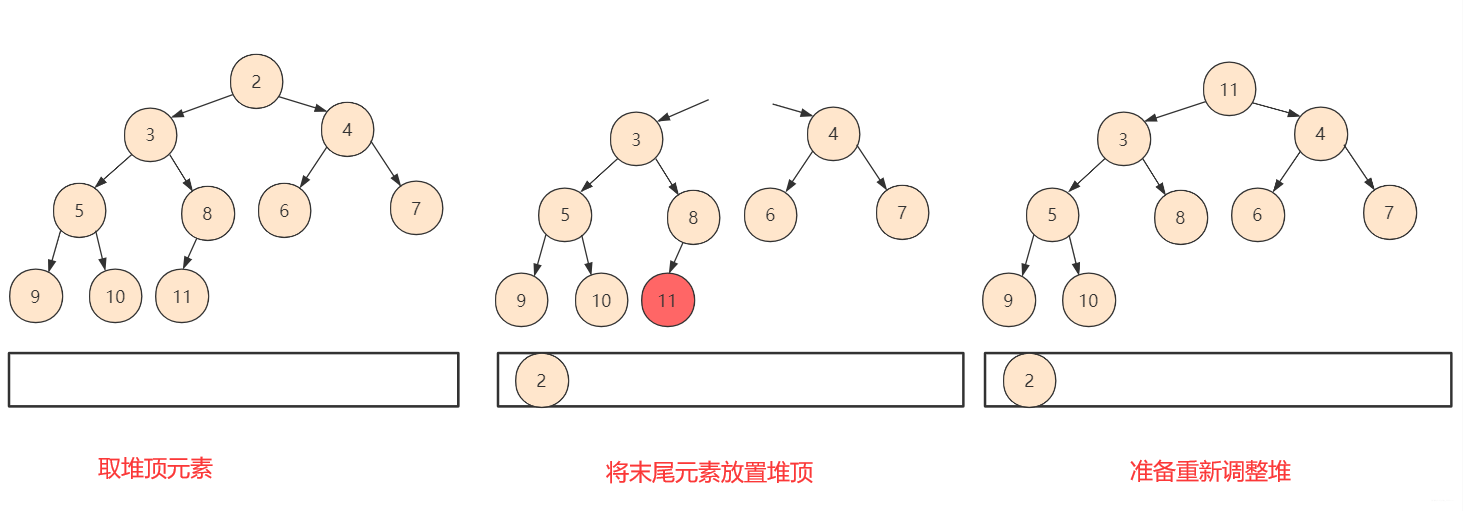
- 判断左右孩子,如果需要交换则交换,交换后再次考虑交换子节点是否需要交换。一直到不需要考虑。
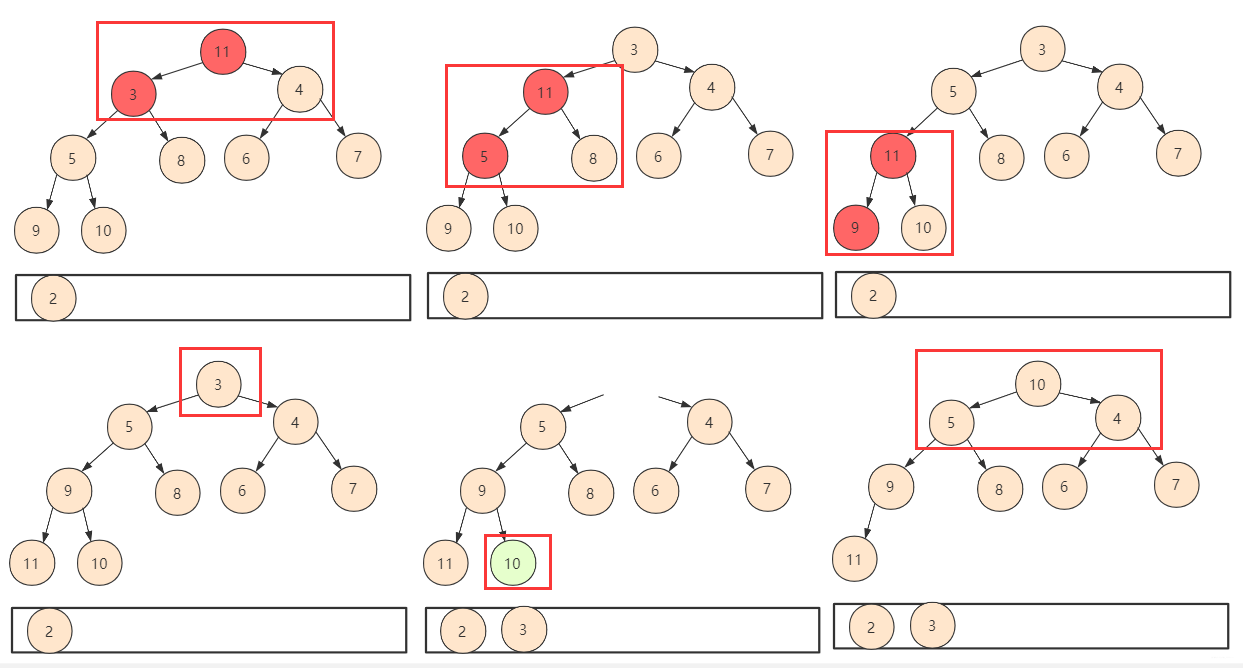
一个大根堆的排序过程如下:

有了上述的思想之后,如何具体的实现这个堆排序的代码呢? 从细致的流程来看,大概流程是如下的:
给定数组建堆(creatHeap)
- 从第一个非叶子节点开始判断交换下移(shiftDown),使得当前节点和子孩子能够保持堆的性值
- 如果交换打破子孩子堆结构性质,那么就要重新下移(shiftDown)被交换的节点一直到停止。
堆构造完成,取第一个堆顶元素为最小(最大),剩下左右孩子依然满足堆的性值,但是缺个堆顶元素,如果给孩子调上来,可能会调动太多并且可能破坏堆结构。
- 所以索性把最后一个元素放到第一位。这样只需要判断交换下移(shiftDown),不过需要注意此时整个堆的大小已经发生了变化,我们在逻辑上不会使用被抛弃的位置,所以在设计函数的时候需要附带一个堆大小的参数。
- 重复以上操作,一直堆中所有元素都被取得停止。
而堆算法复杂度的分析上,之前建堆时间复杂度是O(n)。而每次删除堆顶然后需要向下交换,每个个数最坏为logn个。这样复杂度就为O(nlogn).总的时间复杂度为O(n)+O(nlogn)=O(nlogn).
具体实现的代码如下:
import java.util.Arrays;
public class 堆排序 {
static void swap(int arr[],int m,int n)
{
int team=arr[m];
arr[m]=arr[n];
arr[n]=team;
}
//下移交换 把当前节点有效变换成一个堆(小根)
static void shiftDown(int arr[],int index,int len)//0 号位置不用
{
int leftchild=index*2+1;//左孩子
int rightchild=index*2+2;//右孩子
if(leftchild>=len)
return;
else if(rightchild<len&&arr[rightchild]<arr[index]&&arr[rightchild]<arr[leftchild])//右孩子在范围内并且应该交换
{
swap(arr, index, rightchild);//交换节点值
shiftDown(arr, rightchild, len);//可能会对孩子节点的堆有影响,向下重构
}
else if(arr[leftchild]<arr[index])//交换左孩子
{
swap(arr, index, leftchild);
shiftDown(arr, leftchild, len);
}
}
//将数组创建成堆
static void creatHeap(int arr[])
{
for(int i=arr.length/2;i>=0;i--)
{
shiftDown(arr, i,arr.length);
}
}
static void heapSort(int arr[])
{
System.out.println("原始数组为 :"+Arrays.toString(arr));
int val[]=new int[arr.length]; //临时储存结果
//step1建堆
creatHeap(arr);
System.out.println("建堆后的序列为 :"+Arrays.toString(arr));
//step2 进行n次取值建堆,每次取堆顶元素放到val数组中,最终结果即为一个递增排序的序列
for(int i=0;i<arr.length;i++)
{
val[i]=arr[0];//将堆顶放入结果中
arr[0]=arr[arr.length-1-i];//删除堆顶元素,将末尾元素放到堆顶
shiftDown(arr, 0, arr.length-i);//将这个堆调整为合法的小根堆,注意(逻辑上的)长度有变化
}
//数值克隆复制
for(int i=0;i<arr.length;i++)
{
arr[i]=val[i];
}
System.out.println("堆排序后的序列为:"+Arrays.toString(arr));
}
public static void main(String[] args) {
int arr[]= {14,12,16,8,9,1,14,9,6 };
heapSort(arr);
}
}执行结果:
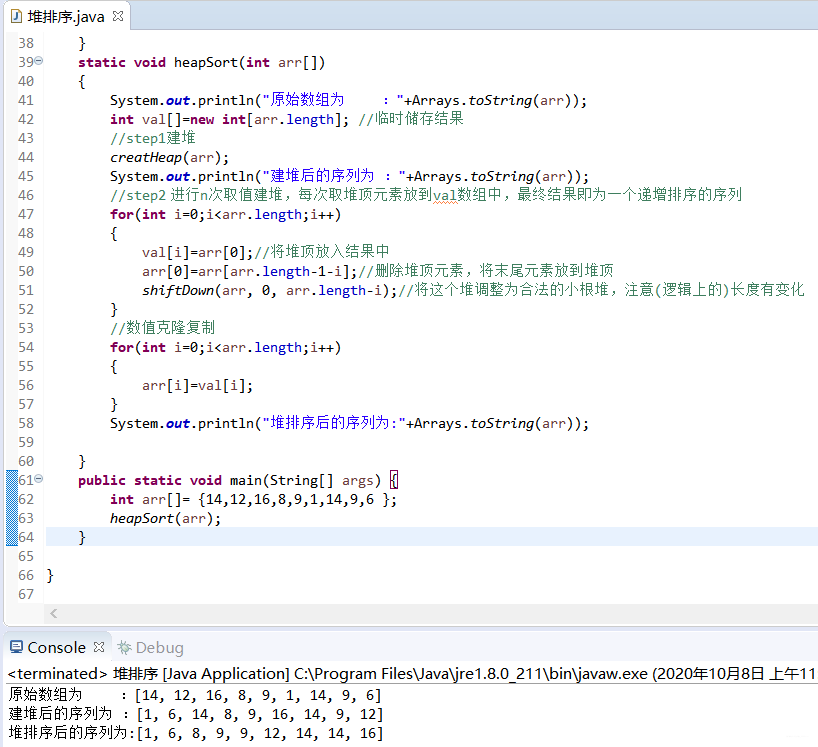
当然,代码为了成章节我把它命名为中文,还有些不规范的地方请注意甄别。
对于堆排序就先介绍到这里了,当然堆的强大之处不止这么一点,优先队列同样也是用到堆但是这里就不详细介绍了,我相信优秀的你肯定又掌握了一门O(nlogn)级别的排序算法啦。如果写的有啥不确切地方还请指正。
原创不易,最后我请你帮两件事帮忙一下:
-
star支持一下, 您的肯定是我在csdn平台创作的源源动力。
-
微信搜索「bigsai」,关注我的公众号,不仅免费送你电子书,我还会第一时间在公众号分享知识技术。加我还可拉你进力扣打卡群一起打卡LeetCode。
记得关注、咱们下次再见!
