I would like to Contribute to this Effort #51
Comments
|
Seconding this. I too learned a lot of invaluable information from this wiki -- stuff I would never have learned about otherwise, and a lot of perspectives I don't see very much these days that were fascinating to look through. Something I noticed today is that currently, the wiki is down. Trying to link someone to a specific page was hellish, since the Web Archive has only a partial mirror of it, with many things missing and hyperlinks between pages utterly broken. Given the lack of status on this project (just going off the github, as the actual wiki pages regarding remodelling are down too) for a few years, would it be too much to ask if the full site pre-remodelling (or maybe just pre-read-only) was made available on the Web Archive? At least then, even if it is tedious to remodel it, someone else might be able to finish the effort, or at least view it as it was in the past. That too would take a lot of effort, but this is a significant piece of computing history (over 25 years of discussion!) that at best, should get to live on, but at least, deserves to be preserved for the future. I am almost certain the kind folks at ArchiveTeam would be willing to help you with this, or help archive it on your behalf, given access to the files. Regardless, thanks for your time in reading this, and the considerable effort you've put into this website! |
|
@ssimontis @AlexandriaOL @DaveEveritt I have made a crude transformation of the pages to Markdown, of which ~90% is good, with work left to do. They are hosted at https://wiki.kluv.in---and the repo is at https://gitlab.com/kluvin/wiiki. The current efforts is to make it writable with git-style versioning. With many paths to choose, and lots too much to do, I would appreciate any input on the what-to-do and things-to-do. |
|
I discourage clones of this content and would appreciate you taking down these sites. |
|
That seems like rather a weird response given that this repository seems to have no commits or work done on it for 7 months. Especially since the current intent seems to be that the content be federated -- surely the entire point of federation is that clones of the content remain accessible on other people's nodes? I haven't seen a complaint raised against the Chinese c2 wiki node, which appears to host a complete clone of the content and at the moment is the only updated source of this wiki. (You can correct me if that's wrong, and personally I can't find a reference to it now, as I'm on another computer -- I do remember you recommending it or linking to it, but I can't find that either at the present time so you'll have to take my word for it 😅). I can understand you feeling protective of this project! But as-is many static wiki pages are both not properly archived by archive.is or archive.org, and many of them are missing from the current deployment of the site -- which means that if there is no further work on the website planned, those pages will remain inaccessible to readers. Would you not rather that the site remain readable and archivable? With regards to user concerns and accessibility of the federated version of the wiki, it seems several orders of magnitude more difficult to browse -- for example, your personal federated wiki has these pages, the bottom bar of which list 750 pages as available -- but there's no clear way to access or view them. The coloured squares for each wiki node is confusing, as it requires one to mouseover a square to see where it leads, unlike the old format where one simply read the link. Probably a separate concern, and I'm willing to split it into a new issue, but, what is the best way to interact and view the wiki content as-is? |
|
Understand, c2 wiki is an accident in time, a collision of new technology and authors of good will. Both have passed. We ran a project with the computer science department at Portland State University last year looking to provide a fresh index to the now archival work. Many parameters of this work were negotiated, mostly to protect the interests of the original authors. The pandemic interfered with the completion of this work but the parameters remain. |
|
Perhaps I should explain why wiki worked. I wrote a program in a weekend and then spent two hours a day for the next five years curating the content it held. For another five years a collection of people did the same work with love for what was there. But that was the end. A third cohort of curators did not appear. Content suffered. I had visualizations. I could see it decay. That is what I mean when I say that the those of good will have passed. A security engineer has compared the open internet to the summer of love. It was neat while it was happening but it is over. Software Patterns, Object Design and Agile Methods were pioneered in c2 wiki. We daily use words that were coined there. But it is no longer the goto reference for any of these things. If anyone thinks another weekend of work will breath new life into these topics they are fooling themselves. But then, how would they know? The real work was invisible. I now spend six hours a week in video calls with folks seriously tackling world problems where federated wiki plays a supporting role. Federated wiki did not work for c2 wiki content in any meaningful way. It could be a design mismatch but more likely patterns, objects and agile are just old news. |
|
Ward,
I was recently typing a proposal and listing the various things that I
thought supported the notion that I was qualified in terms of experience,
skill, and record of accomplishment. I have done so much that I stopped
last night to regroup. It was somewhat embarrassing how much is there, and
how long it goes back with footprints on the web more than twenty years
old. When you are busy accumulating work for so long, you don't realize
just how much there is. Similarly, C2 is an enormous work with an
incredible amount of value. I don't think I was a major contributor there,
and I put a lot of text up there. Having been so close to it for so long,
you probably don't actually appreciate the totality of the work there. It's
not just volume; it's also its quality. I disagreed with many people there,
and over the years, my conviction in various matters increased. History has
proved me right in many things. However, even though I was correct, and had
my reasons from experience, articulating them on C2 helped me to form
coherent arguments to support my point of view. I discovered the issues
with C2 that led to the current effort when I went to look up some old
stuff I had written there.
There is a saying apropos of the promotion of new things, "the first one in
the door gets shot". I knew that the web was going to explode long before
it did, and I started a pilot business to put up websites for people. I had
no problem selling, because I could demonstrate they earned more than they
cost. I also had no problem making enough on the initial sale to pay for
the vanilla development. What I had never experienced was the wear and
tear, stress, and costs of continuing to maintain everything when it all
rested on my shoulders and the web was a constantly moving target.
Not many can really appreciate how exhausted and wrung out by this you can
get. It is particularly difficult when surrounded by stuff like this, where
you have a legacy system with all its warts and obsolete assumptions
containing enormous amounts of interlinked data. One of the things that
made me smile from time to time on C2 was journeymen programmers declaring
their simple solutions to problems that reflected little experience with
genuinely large, critical production systems.
Another thing that made me smile, and made me surprised the current effort
happened at all: I had a complaint about C2 (a privacy thing). One of the
old-timers there said "...keep in mind that the code base is frozen and
unlikely to change before the heat-death of the universe, thus precluding
any technical means of..."
C2 is an ancient tree from which the seeds of things like Wikipedia came.
If nothing else, it is important historically to give an idea of the ethos
of a community that informed much of the world we live in. I really want to
keep it. It would be valuable as a static artifact, but I think it would be
much, much more valuable as a living tree.
I know how absolutely soul destroying it is to maintain something like
this. One of the many things that are maddening about stuff like this is
that you know you can do better, but the task is so enormous due to legacy
issues and sheer size. In addition, you get to a point where exhaustion
takes all the joy out of it, and just turns it to drudgery -- a software
death march where you cannot die, and just carry on like a zombie. Like me,
I expect a lot of the people who could really help are occupied with their
responsibilities, and let's face it, us older folk with experience herding
cats are not too keen on ... herding cats.
I have an aging mother who I am trying to move, and several overdue tasks
that I must attend to, but I will make you this pledge: Within eight weeks,
I will set aside ten days or more to roll up my sleeves and pitch in to
make this a recovery that makes you proud.
I don't want to give you permission to give up, but if you do, rest assured
that you have already long since acquitted yourself and then some. You can
be more than proud of what you have accomplished, and whatever you do going
forward is not going to change that.
Whew! That was a long note. I probably was a large contributor to C2 in
terms of walls of text. Hang in there, and whatever you do, the world owes
you a huge debt of gratitude for the contribution you have made, freely,
with an open hand.
Cheers!
Bob
P.S. It occurs to me that some of the people who see this may not know who
Ward Cunningham is:
https://en.wikipedia.org/wiki/History_of_wikis
Show some respect :)
[Paragraph breaks added -- Ward]
|
|
I have set a reminder on my calendar for seven weeks from now to prepare
for a week or two of work on this project. Until at least then, I hope
everybody can keep it together.
I sent a long note about this, so will not belabor it here, but being the
principal on a thing like this is exhausting. It is exhausting in a way
that people who have not been there cannot appreciate. It makes one weary
in the soul.
Ward has freely contributed to the community at large for more than a
quarter of a century. Standing back for seven months may seem like a long
time to some, but to older people like me it's not a big deal. I still owe
an email to rms from seven years ago. He'll answer as he does when I reply
and not mention the time at all.
Delay is a thing in our world.
I'm sure that there are plenty of hands that can be brought to bear on this
-- enough to make the mythical man month a concern. What is really needed
is for someone to create a workable plan and break work out into doable
pieces.
I, for instance, can write tools like this:
http://base64.sourceforge.net/b64.c
That code is in use in hundreds of millions of devices now, so...
If a purpose built utility like that will help, I can produce one in a few
days and will make a pledge to do so shortly after I have a request.
I peek in on this from time to time, but will pay more attention going
forward. If someone has general development questions that I can answer, I
will pipe up. I've done just about everything related to software
development, and might be able to quickly answer questions that puzzle
people with less experience. Example: Tabs or Spaces? I am genuinely
mystified why anybody would think this is a reasonable debate. The answer
is 'Spaces'. Tabs break stuff and Murphy's law rules. If you can't
understand that and need another reason: Developers who use spaces make
more money than developers who use tabs. Eventually, natural selection will
kill off debates like this. Meantime, experienced developers may be able to
easily answer questions like that.
Everybody needs to go easy on Ward. He has been carrying the standard for a
very, very long time. If it gets too heavy he should be able to put it down
for a while without getting a lot of flak. A lesser person than Ward would
have walked long ago.
B.
[Paragraph breaks added -- Ward]
|
|
@btrower is kind to me. Thank you. This repo would benefit from a "how to contribute" page. Without it the repo is a bit of an attractive nuisance that traps unsuspecting volunteers. I'm sorry. Progress on the remodel has been much slower and is more complicated than expected. They are issues not easily summarized in a todo page. |
|
In speaking of experience I was not yet born when the Ward's Wiki appeared, and I only heard about it a year after it went read-only. I started working on my piece shortly thereafter. Never having been there for the golden age, I got to look at the remnants of something that was, and I can only imagine the vast work that went into creating and curating it. I am saddened that you discourage clones and derivative work, seeing that the intrinsic value of Wiki is namely that of sharing. It seems to me that, whatever the future of Wiki is, the artifact that is today remains the first massively collaborative piece of writing; by all means a contemporary work of art, a work that will influence any bypassers far after its disappearance. However, as @btrower says, it is much more valuable kept alive. As Ward says Wiki does not have much value anymore as a reference, its value is ultimately as a historical artifact of not just what used to be, but also as a first of many greats. Nevertheless, it can be so much more. The work I wanted to do is preservation. Transforming the markup which not standardized, and the output which is also not standardized, to standard forms. The raw markup was rendered to HTML by the JS source at wiki.c2 and piped into pandoc to create Markdown. Providing the opportunity to interface with anything that can work with anything in the pandoc ecosystem. Regular expressions was liberally used to fix structural differences between my output and the target. The website, or clone, was primarily a debugging tool and a proof-of-concept. Finding an audience would be a useful side effect. It may have been part of landing me my first job. It has provided tons of value to me, and it has been fulfilling to work on something that I feel may help someone. Perhaps it has more than served its purpose? At least for me, it has done well. That said, I will take down the pages if that is your say, although I would like to appreciate the reason why. However, I would like to leave the code up, in hope that it may be useful to someone, and I will continue to work on the federated editing aspects of it---which is inspired by the promise of the Federated Wiki that I have tried many times to figure but always come out short-handed from. I would like to learn, if you have any advice. It always seemed tempting to pop in to one of your Zoom discussions. The recent developments here leaves me greatly encouraged. Any work done well deserves a second chance.
By said definition---and prior context which I did not include for brevity---I would argue we seem to be sitting upon a gold mine ourselves. This one far greater. Most of all it is a staple of building the airplane while it's flying, that idea had such a profound significance it coined a word---a feat not to be underestimated. While the idea was that of a weekends work, the later maintenance efforts that you have done is the defining achievement and it no doubt was a large factor of the Wiki's success. We are all indebted to you, your efforts, and your ideas. I wish you all the best in your future endeavors. PS. Please write a book sometime, I would love to read it. |
Yes, that's true. I hope you will see my impatience as one out of concern
Of course! But that static artifact is also valuable, in case the living tree I'm that at work on this will continue, but I disagree with this:
Personally, c2 is and has been my personal reference for these concepts for Most of the 'content' that you can learn about design patterns from these For me, personally, and for the people I have linked to c2wiki, it has been None of this even mentions, how absolutely and incredibly humbling it is to Recently I tried to link someone to some concepts they had never heard of, I'm indebted to you, Ward, for your continued work on maintaining this wiki. |
|
AlexandriaOL is correct about the value of C2. People are taught in school
as if things are cast in stone and everything is all figured out. I
liked the Design Patterns book, and it is fine for people like me with lots
of experience, but it can't show the story of how we got there. In the
case, for instance, of the Singleton pattern, there was a lively discussion
in which adherents of the book attempted to defend it when people like me
(maybe only me) articulated the criticism that it was bad practice --
essentially formalization of global variable -- which, unbelievably, there
are actually people supporting global variables. The discussions involved
people with all sorts of different backgrounds, and even when people are
off the mark with one thing or another, it's useful to see their rationale
even from mistaken notions.
Bottom line, C2 is something that should not be left to die. We have to
save it. For my money it is vastly preferable if we can revive not just the
site, but the community as well. I don't know if this will make sense to
people, but I like to reread these discussions even when they resolve and I
agree, or even especially when they resolve and I agree. For an old
programmer like me, they are like cozy bedtime stories. :)
I have another note in progress about next steps that I will finish up and
send along shortly .
Cheers!
…On Sat, May 8, 2021 at 7:05 AM AlexandriaOL ***@***.***> wrote:
Ward has freely contributed to the community at large for more than a
quarter of a century. Standing back for seven months may seem like a long
time to some, but to older people like me it's not a big deal. I still owe
an email to rms from seven years ago. He'll answer as he does when I reply
and not mention the time at all.
Delay is a thing in our world.
Yes, that's true. I hope you will see my impatience as one out of concern
and love for the wiki, rather than as a nuisance!
C2 is an ancient tree from which the seeds of things like Wikipedia came.
If nothing else, it is important historically to give an idea of the ethos
of a community that informed much of the world we live in. I really want to
keep it. It would be valuable as a static artifact, but I think it would be
much, much more valuable as a living tree.
Of course! But that static artifact is also valuable, in case the living
tree
dies in some way, we still have that artifact. Likewise, at the moment
there
are a lot of missing pages in the static wiki (and federated wiki, as far
as
I can tell? It's difficult for me to navigate), and I believe that those
pages
deserve to be preserved in some way.
I'm that at work on this will continue, but I disagree with this:
Software Patterns, Object Design and Agile Methods were pioneered in c2
wiki. We daily use words that were coined there. But it is no longer the
goto
reference for any of these things. If anyone thinks another weekend of work
will breath new life into these topics they are fooling themselves.
Personally, c2 is and has been my personal reference for these concepts for
over a decade, it's one of the ways I learned on them as a much younger,
and immature programmer -- and it's one of the ways I recommend *other*
people learn of them.
Most of the 'content' that you can learn about design patterns from these
days, are nowhere *near* as rich in content. Oftentimes I would hear the
name of a pattern and while I would learn about that pattern, and maybe a
smattering of usecases, it was always inside a structured learning format.
Then I found this wiki and not only did the hyperlink system introduce me
to *new* less-widely known things, but here were people from years ago,
talking about their /personal experience/ with those patterns, having
debates about the merit of them and comparing their notes -- sometimes
aggressively! You can see many different approaches to why this or that has
been favoured (some of which have fallen out of use, but are no less
valuable), short little histories of how these things came about from the
people that were there. While it is of historical value, it is possibly one
of the richest resources to date, because unlike a lot of contemporary ways
to learn about these concepts, it doesn't come with any framing. What
better way to learn about concepts than from the people that were there?
What better way to learn about something than by learning, also, about the
history of it? Than by understanding the context in which it was created
and forged.
For me, personally, and for the people I have linked to c2wiki, it has been
of immense value to read these discussions. There is a huge, massive gap of
knowledge in computer science, and programming. Unlike other fields, we
rarely remember our roots -- we are so, so concerned with pushing forward,
that we often forget to look back, and learn from the experiences of those
before us. It has become so bad now, that most of the new projects I see
posted on programming-specific link aggregators, are just versions of
things done in the past, except often they are worse, because the authors
frequently have no *idea* the old exists, and so they have no opportunity
to learn of the mistakes of those who came before, and avoid them.
None of this even mentions, how absolutely and incredibly humbling it is to
see exactly the same debates, repeated almost *verbatim*, except decades
before. It is difficult to express how much of an impact this wiki has had
on my personal knowledge, and the opportunities that reading it gave me to
grow.
I'm actually not very sure how to end this, so I'll just leave it here.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV7777CZSJ7F3RUKQU3TMULINANCNFSM4WGCFYKQ>
.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
Martin's work to date may be very helpful. I will send a link to a
development methodology diagram in my next note. One of the things that is
not explicit in it is a treatment of data, which in this case is a
significant part of the project. Whatever it is that we do needs to capture
back as much of the data as possible.
In a situation like this, everybody has to be sympathetic to one another's
point of view. I get what everybody is saying. It has been a long time in
the works. Ward is right, I think to try to stop a proliferation of
projects essentially forking this thing out of existence. Martin is right
to just get on with the business of getting something done. AlexandriaOL is
not out of line to be impatient so see progress. There are, I expect, a lot
of hidden stakeholders that will come out of the woodwork, once something
new goes live on C2.
I promise to make time in about eight weeks to pitch in, but meantime,
since people are impatient to see action, I will talk about first steps.
Cheers!
B.
…On Fri, May 7, 2021 at 6:29 PM Martin Kleiven ***@***.***> wrote:
In speaking of experience I was not yet born when the Ward's Wiki
appeared, and I only heard about it a year after it went read-only. I
started working on my piece shortly thereafter. Never having been there for
the golden age, I got to look at the remnants of something that was, and I
can only imagine the vast work that went into creating and curating it.
I am saddened that you discourage clones and derivative work, seeing that
the intrinsic value of Wiki is namely that of sharing. It seems to me that,
whatever the future of Wiki is, the artifact that is today remains the
first massively collaborative piece of writing; by all means a contemporary
work of art, a work that will influence any bypassers far after its
disappearance. However, as @btrower <https://github.com/btrower> says, it
is much more valuable kept alive. As Ward says Wiki does not have much
value anymore as a reference, its value is ultimately as a historical
artifact of not just what used to be, but also as a first of many greats.
Nevertheless, it can be so much more.
The work I wanted to do is preservation. Transforming the markup which not
standardized, and the output which is also not standardized, to standard
forms. The raw markup was rendered to HTML by the JS source at wiki.c2 and
piped into pandoc to create Markdown. Providing the opportunity to
interface with anything that can work with anything in the pandoc
ecosystem. Regular expressions was liberally used to fix structural
differences between my output and the target. The website, or clone, was
primarily a debugging tool and a proof-of-concept. Finding an audience
would be a useful side effect. It may have been part of landing me my first
job. It has provided tons of value to me, and it has been fulfilling to
work on something that I feel may help someone. Perhaps it has more than
served its purpose? At least for me, it has done well.
That said, I will take down the pages if that is your say, although I
would like to appreciate the reason why. However, I would like to leave the
code up, in hope that it may be useful to someone, and I will continue to
work on the federated editing aspects of it---which is inspired by the
promise of the Federated Wiki that I have tried many times to figure but
always come out short-handed from. I would like to learn, if you have any
advice. It always seemed tempting to pop in to one of your Zoom discussions.
------------------------------
The recent developments here leaves me greatly encouraged. Any work done
well deserves a second chance.
So imagine that these guys are thinking this way for a few years. Pretty
soon they would have a collection of solutions. Now imagine them using
their solutions in their work for a few more years, and discarding the ones
that are too hard or don't always produce results. Well, that approach just
about defines *pragmatic*. Now imagine them taking a year or two more to
write their solutions down. You might think, *That information would be a
gold mine*. And you would be right.
- Ward Cunningham, foreword to The Pragmatic Programmer
By said definition---and prior context which I did not include for
brevity---I would argue we seem to be sitting upon a gold mine ourselves.
This one far greater. Most of all it is a staple of building the airplane
while it's flying, that idea had such a profound significance it coined a
word---a feat not to be underestimated.
While the idea was that of a weekends work, the later maintenance efforts
that you have done is the defining achievement and it no doubt was a large
factor of the Wiki's success. We are all indebted to you, your efforts, and
your ideas.
I wish you all the best in your future endeavors.
Martin
PS. Please write a book sometime, I would love to read it.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAVYW7JZJV4KRVZNYWHLTMRSVVANCNFSM4WGCFYKQ>
.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
My reference to 'herding cats' is basically about this type of stumbling
block. Somebody has to steer the ship. I can help train a
captain/crew, do grunt work, etc., but coordinating is exhausting. I am too
old. This is a young man's game. Anyway, when I come to work on this, I
will sort out what I can. I am familiar with the rodeo. I should be able to
help wherever needed.
Real software development is still a messy, labor intensive business. You
need goals and a plan, but you also need to recognize that plans are
imperfect, things change, and people make mistakes.
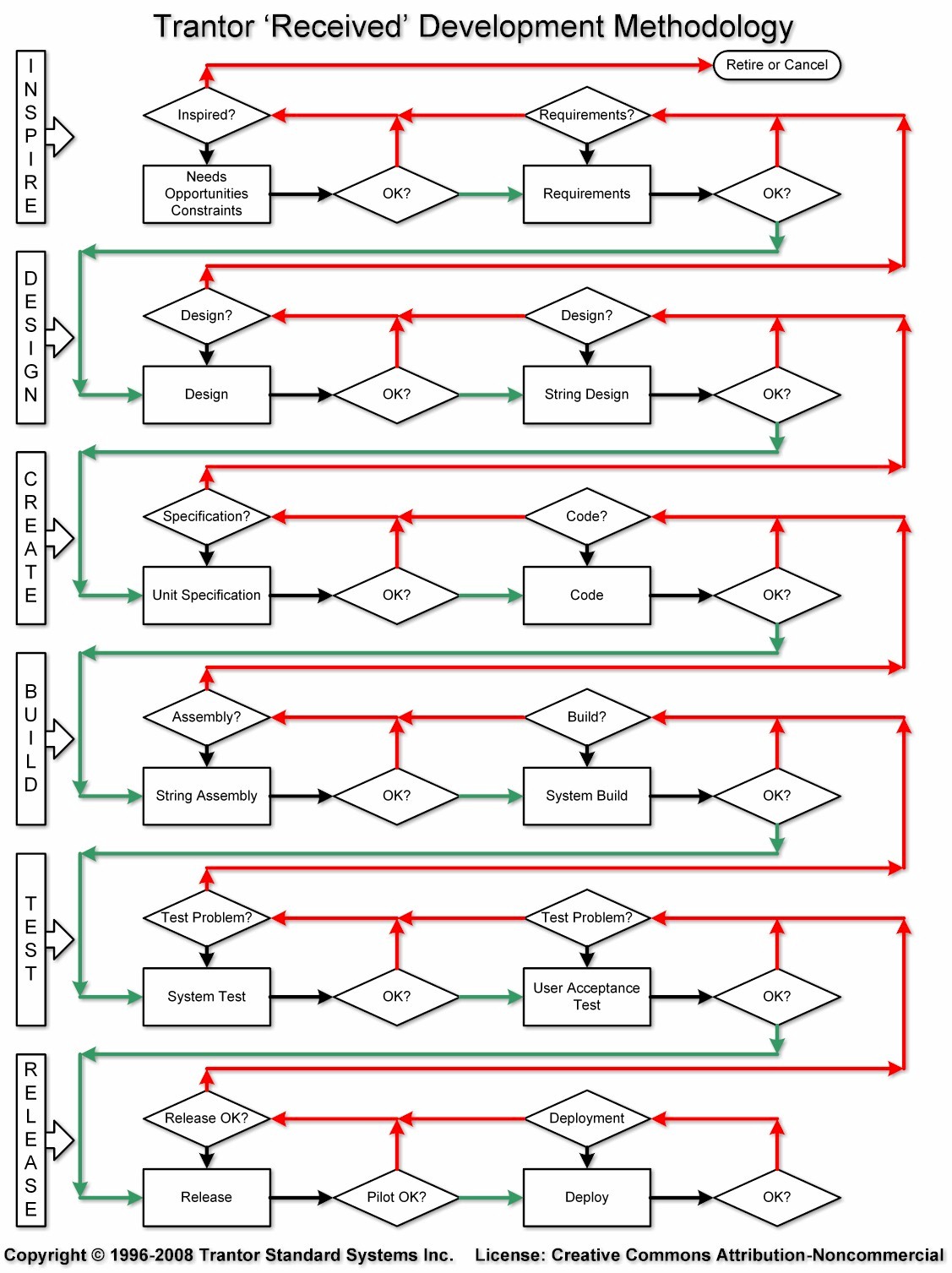
This is a graphic on development methodology that breaks various tasks into
a logical flow, and iterations.
https://upload.wikimedia.org/wikipedia/commons/8/8e/Received_Development_Methodology.jpg
I would suggest that things be framed from the beginning, so start at
'inspire'.
Inspire is the original impetus for the system that will be built. Many
things are just a programmer scratching an itch, an executive wanting
one-up others in the C-suite, something to demonstrate technology,
whatever. There is a reason it is being done.
We are actually struggling a bit already at this stage. There is not a 100
percent aggressive buy-in to even moving forward from the first diamond. It
has to have enough of a drive behind it to get going properly or it just
ends up retired.
I'll go first:
Need:I would like to see a new version of C2.com that restores all of the
material I have read and written there.
Opportunity: There was an existing system, that although long in the tooth,
was good enough to attract programmers to discuss development issues. The
data is valuable.
Problem/Opportunity:I believe there are some legacy issues that make the
system too difficult to maintain. This is the problem with the old system
that needs to be addressed. The opportunity is that we can both recover the
material and have a new system that has wiki's advantages without issues.
Constraint:It needs to run somewhere. C2.com is the obvious choice, but it
may not be feasible. Need to clarify this.
Need:This time it has to be maintainable with minimum effort. That means
backup, maintenance, updates, and rollbacks, system rollover, etc all need
to be addressed with a protocol and automated.
If you look at the diagram, one of the destinations is to cancel or retire
a system. Ward has been leaning toward that direction, and I don't blame
him. This type of thing is a heavy weight to carry alone. People need to be
gentle...
Test driven development is painful, but it is the only way to ensure
reasonable coverage and working code. Below is a link to a program that I
built later than the base64 code and automates the manual testing. It is a
simple(ish) utility that does everything I like to see in a utility like
that. It is probably a good sign that code derived from it is in production
elsewhere. It was released as version 0.00.00B(eta) in 2005, and that is
the last release because it worked for the purposes it was built
http://toogles.sourceforge.net/md5.php?myname=md5
The specific thing that Ward mentions about "how to contribute" should
involve a Build Manager who supervises the 'Build' portion of things. That
person should co-ordinate how people pull down from GitHub, and push back.
The same people can do multiple things, but we need 'roles':
Stakeholders - Ward is one. I am another. The broader community needs a rep.
Project Manager -- Ugh. This requires somebody with the energy to start
things up, keep everything moving, manage the rules, manage disagreement,
etc. It's exhausting just thinking about it. I will help somebody skill up
if necessary, though it would be nice if we had somebody experienced at the
start.
Inspiration Manager -- on an ongoing basis we need to refine
rationale/justification, and be prepared to pull the plug to cancel/retire.
Design Manager/Designers -- I think everybody should be involved in design
to some extent, but the process needs to be managed by somebody. Designs
cannot ever be perfect. We need somebody to shepherd a preliminary design
forward so the rest of the pipeline is filled.
Creation Manager, Manager of development -- somebody needs to understand
the design well enough to create units, subsystems, and an overall system
architecture, and supervise building and Unit test.
Build Manager -- this is one of the thankless tasks that is crucial, and
like being a DBA difficult enough to demand high intelligence, but boring
and repetitive day to day. Somebody needs to co-ordinate building the
system form sources on an ongoing basis, and prepping releases.
Test Manager -- even perfect code that snaps together at Unit and String
will not be perfect at the system build level. Somebody needs to design and
manage system test, UAT, and signing off on a package for release.
Release Manager -- If all goes well, this goes from test to pilot to
deployment. Typically, all does not go well. Every aspect of the system is
likely to revert all the way back to the beginning at some point. The
release manager has to see a working pilot through the fine tuning
necessary to deploy into production.
The aim of this type of protocol is to see all the way through to
deployment of an imperfect beast that will feed back into the system for
subsequent releases to correct error, add (absolutely necessary) features,
and to vet the system for viability. It is, sadly, more often than not on
big systems, that this immediately goes all the way back to cancellation.
Hopefully that will not be the case here.
I have a lot of experience managing teams through processes like this, so I
can help get somebody up to speed. I have done or supervised all of the
tasks here, but I am weak on build management, which is a vital part of a
system that involves a lot of people. However, although I am not well
versed in the details of managing integration of code like Linus Torvalds,
I am familiar with the overall process and what it needs to do. I have set
up revision control (svn) for teams in the past, but I'm beyond rusty. I
can help somebody come up to speed, but it would be a blessing if I could
duck this...
If people are keen to get moving, I suggest they just get on with it.
Coordinate over the mailing list to determine who will take
responsibility for what, and get going.
The protocol in that drawing is designed by me, and that is the protocol
that matches development efforts that I have seen succeed. Even when it was
just a couple of us, the build system was automated so that it built from
sources and ran its system test on its own. I have a nice small working
example of something that manages a database and builds ground up from
sources with two keystrokes. I can provide some info on that if people need
it.
I will pitch in when I can and will roll up my sleeves for real in about
eight weeks. I will monitor the mailing list and answer questions as I am
able.
When called upon to manage new teams, I used to give a little 'lunch and
learn' session on "Bob's 30 minute guide to management". One of the
important take-aways from this is that everybody manages up, down,
sideways, and internally. Everybody on a team needs to put their manager
hat on, and everybody needs to have the skill to dovetail into a team as
needed. We are all in this together, and success is success however we get
it, and the corollary is, for me, not acceptable.
I will respond to requests as I am able in the coming weeks, and I will
take whatever role I can to help when I come on board full time for a bit.
This is work, and it's not always going to be fun. However I think it can
be an excellent learning experience for everyone, me included, and if we
can get the right people we can produce something of which we can be proud.
Be kind to one another.
Cheers!
Bob
…On Fri, May 7, 2021 at 2:16 PM Ward Cunningham ***@***.***> wrote:
@btrower <https://github.com/btrower> is kind to me. Thank you.
This repo would benefit from a "how to contribute" page. Without it the
repo is a bit of an attractive nuisance that traps unsuspecting volunteers.
I'm sorry. Progress on the remodel has been much slower and is more
complicated than expected. They are not easily summarized in a todo page.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV6SOKWNQ2TQLW227ZDTMQVBJANCNFSM4WGCFYKQ>
.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
Hi @btrower, just wondering what the status is on your end these days? Hope all is going well! Cheers, |
|
Sorry! Meant to get back on this. We had an emergency here at my house and
digging out has been taxing. It happened while my office was being redone
so I was offline. Just getting back online.
All is well, so not to worry. I have just been sidelined.
Have been corresponding with a couple of people who might be able to help.
TBH, I'm a little fuzzy about action items here. I am hoping that someone
else more acquainted with the status of things can help me ramp up.
I am concerned that Ward will not be too taxed by whatever is done.
I am back online now, so will be attending to messages a bit more. We have
gone from emergency status here to cleanup which is better, but I'm not
quite free yet.
Cheers!
Bob
…On Sat, Aug 28, 2021 at 12:29 PM Martin Kleiven ***@***.***> wrote:
Hi @btrower <https://github.com/btrower>, just wondering what the status
is on your end these days?
Hope all is going well!
Cheers,
Martin
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV4PRERGX7AZ2JYXUQ3T7EFGHANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
Here is what would help me. There are about 1000 pages out of 36,000 pages that have character set problems making them difficult to encode as json. If someone with some character set skills were to volunteer to convert one page then I could construct a tgz file with all available versions of that page from which, with care, a good clean version could be constructed. If your skills are with react or maybe blockchain then it is probably better to wait until this work is done. |
|
I wrote this: http://base64.sourceforge.net/b64.c
Somewhat different problem, but I might be able to help.
Where's a representative page?
Cheers!
…On Thu, Sep 9, 2021 at 10:22 PM Ward Cunningham ***@***.***> wrote:
Here is what would help me.
There are about 1000 pages out of 36,000 pages that have character set
problems making them difficult to encode as json. If someone with some
character set skills were to volunteer to convert one page then I could
construct a tgz file with all available versions of that page from which,
with care, a good clean version could be constructed. If your skills are
with react or maybe blockchain then it is probably better to wait until
this work is done.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV7R26564BWF7NWUPL3UBFTW5ANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
Here is one that didn't convert: |
|
Here is the best source I can find in the original key/value format. This is a text file with alternating key and value separated by an ASCII GS (group separator) character. Old format: http://c2.com/wiki/todo/ProjectGalacticGuide Is it clear what needs to be done? |
|
I’m just on my phone now, but this looks like what I was asking for.
Thanks.
Bob Trower -- from mobile phone
… On Sep 9, 2021, at 11:54 PM, Ward Cunningham ***@***.***> wrote:
Here is the best source I can find in the original key/value format.
http://c2.com/wiki/todo/SmalltalkBestPracticePatterns
This is a text file with alternating key and value separated by an ASCII GS (group separator) character.
Here as an example is a file that has been converted without problem to json encoded in utf-8.
Old format: http://c2.com/wiki/todo/ProjectGalacticGuide
New format: https://proxy.c2.com/wiki/remodel/pages/ProjectGalacticGuide
New wiki page rendered from new format: http://wiki.c2.com/?ProjectGalacticGuide
Is it clear what needs to be done?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
Triage notifications on the go with GitHub Mobile for iOS or Android.
|
|
Ward, I used curl to download the references you gave me, however I am not
certain between your server and my browser whether changes were made to the
file on the way.
Can you email me directly ***@***.***) an archive of enough assorted
sample raw documents as they reside in binary on your file system?
There is a two byte code 0xB3 (dec 179) that is a superscript '3' in
extended ASCII, but with the default old IBM PC code page 437, using the
Alt key to enter the character causes it to be re-interpreted as a pipe
('|') character and translated to extended ASCII 166 as some artifact of
the cut and paste function at the command line.
I can write a small program to rip through the files translating them into
whatever binary representation is needed, but I need enough input samples
to determine what translation is needed. If it is just old-school 256 bit
coding, it's just a simple table substitution. I don't mind building it.
Cheers!
B.
…On Thu, Sep 9, 2021 at 11:54 PM Ward Cunningham ***@***.***> wrote:
Here is the best source I can find in the original key/value format.
http://c2.com/wiki/todo/SmalltalkBestPracticePatterns
This is a text file with alternating key and value separated by an ASCII
GS (group separator) character.
Here as an example is a file that has been converted without problem to
json encoded in utf-8.
Old format: http://c2.com/wiki/todo/ProjectGalacticGuide
New format: https://proxy.c2.com/wiki/remodel/pages/ProjectGalacticGuide
New wiki page rendered from new format:
http://wiki.c2.com/?ProjectGalacticGuide
Is it clear what needs to be done?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAVY564NYQAXYPFZ5S5DUBF6P3ANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
Does a superscript '3' make sense in the context where it was found? |
|
I believe a converter will require advanced heuristics as there are probably multiple character sets in a single file. There also needs to be some review of substitutions. |
|
Here is a tgz of the sample files I have already posted. I'd be interested to know if you are seeing some distortion of the files when served as plain text without further encoding. |
|
Ward,
As far as I can tell, they are the same with respect to the
superscript/pipe character. I am going to spend the day writing code to
examine it better as a binary file to ensure that it is just the one
character, and the file is as it appears to be.
I could really use a lot more sample files to ensure that I am seeing the
whole picture.
I will have further questions about this. It would appear that the
superscript 3 is actually supposed to be a pipe character acting as a field
separator. The pipe character ('|') is what we typically used in raw text
data files when loading into Sybase databases.
This below:
date³June 19, 2010³ip³87.232.40.53³host³dsl-040-053.cust.imagine.ie³copy³Project
Galactic Guide [text]
Parses to this:
"date","June 19, 2010","ip","87.232.40.53","host","
dsl-040-053.cust.imagine.ie","copy","Project Galactic Guide [text]"
That looks to me to be name value pairs:
"date","June 19, 2010",
"ip","87.232.40.53",
"host","dsl-040-053.cust.imagine.ie",
"copy","Project Galactic Guide [text]"
If the above is all there is, the 'syntax' of the ('|') is easy enough to
parse. The semantics of the resulting file are not clear to me. I need more
samples and context.
The bottom of the file /SmalltalkBestPracticePatterns/ has this after
interpreting:
CategorySmalltalk, CategoryGroupsOfPatterns",
"agent","",
"rev","50",
"code","567",
"r1","http://www.prenhall.com/allbooks/ptr_013476904X.html"
Writing a parser for this could be relatively trivial.
Can somebody supply or point me to a source for more info/raw files?
Bob
…On Wed, Sep 15, 2021 at 8:08 PM Ward Cunningham ***@***.***> wrote:
Here is a tgz of the sample files I have already posted. I'd be interested
to know if you are seeing some distortion of the files when served as plain
text without further encoding.
http://c2.com/wiki/todo/todo.tgz
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV6C6MFVYGPW373E453UCEYO3ANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
The original wiki was written in perl which supported a key-value datatype that could be initialized from an array of alternating keys and values. Wiki serialized these objects to a single text file by writing keys and values separated by a character internally referred to as The serialized page was parsed into keys and values with the perl My ingest logic was careful to be sure there were no |
|
Looking back through this repo I found some of the programs I wrote to make my initial conversion. This program converted This program was compiled to produce the executable, The import logic that begins on line 9 would choke on some files. I ignored these and carried on. Today, five years later, we are considering how to make one of these files go through this conversion. |
|
Oops. Must have pushed the wrong button. I did not mean to close this issue. |
|
Line 7 in json.c looks for octal 0263 as the separator character. That is
ASC(179) (263)8 = (179)10, which on the de\fault old IBM OEM (code page
437) is the pipe character ('|')
if (ch==0263) {
If there is a match, it outputs the output separator string ("<<<<g$>>>>"),
otherwise it outputs the character (ch here).
If the files were converted to plain ASCII (which only goes from 0-127),
the pipe character is 124 decimal.
I can rewrite the c file properly so we can see what causes ruby to choke
and line 9. If I'm going to do that, maybe it makes sense to dispense with
the ruby file and just do it all in C. I don't mind coding it.
The only oddball thing I see in the files I have been given is the extended
ascii pipe character from code page 437. It's easy enough for me to detect
or alter that.
If the only issue here is to get everything into json, and I can get
enough of the source data files to build and test, I can do the code to
make it so it doesn't choke even if I have to do some hacks to detect and
fix other errors.
To be honest, I am not even 100% clear what is wrong and what 'right' looks
like. If it's just targeting json files I think it would be easiest if I
just hand code a translator.
Let me know. I am at my desk and can spend time on this on Saturday. I am
out of town Sunday, but can resume Monday/Tuesday.
Cheers!
Bob
…On Fri, Sep 17, 2021 at 12:57 PM Ward Cunningham ***@***.***> wrote:
Looking back through this repo I found some of the programs I wrote to
make my initial conversion.
This program converted $SEP characters to an equally unlikely sequence,
<<<<gs>>>>, that would be allowed by ruby.
https://github.com/WardCunningham/remodeling/blob/master/json.c
This program was compiled to produce the executable, a.out, which was
invoked in a pipeline by the ruby program that did the bulk conversion.
https://github.com/WardCunningham/remodeling/blob/master/json.rb
The import logic that begins on line 9 would choke on some files. I
ignored these and carried on. Today, five years later, we are considering
how to make one of these files go through this conversion.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAVYMDKKIWZPSVY7GBHTUCNXQDANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
I see Wiki's FindPage sees two versions of this page. The incorrectly capitalized version does exist. This might explain why the "correct" version appears to be defective.
|

{kind=link}
|
What do the two sources look like?
…On Fri, Sep 17, 2021 at 11:03 PM Ward Cunningham ***@***.***> wrote:
I see Wiki's FindPage sees two versions of this page. The incorrectly
capitalized version does exist. This might explain why the "correct"
version appears to be defective.
[image: image]
<https://user-images.githubusercontent.com/12127/133870360-b9b1d5f7-a935-49e4-9d12-93c71d9730a8.png>
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAV2K3GUVUANNMJFBPUTUCP6RPANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
|
The file (SmalltalkBestPracticePatterns) that you sent me is a raw text
file that is interpreted as 'ANSI' and is essentially dependent upon the
code page in use on the system. The usual default for the extended
ASCII, Windows-1252/(CP-1252) appears to be 179(10) = superscript 3, so
that is what is showing up in things defaulting to that code page. However,
the old IBM code page 437 was likely the default on older systems and that
has 179(10) = '|' (the pipe character). I am not sure why it ended up like
this because the ordinary 7 bit set has the pipe character at 124(10), and
so Windows-1252 has it showing up twice.
Anyway, without seeing more files all I have is that the pipe character is
showing up as 0263(8)/179(10), and since the file you sent is a straight 8
bit text file and the code you sent already deals with the existing byte
there can't be an issue there with respect to the code page because it is
being read as a binary file. Perhaps in the pipe the ruby code is
interpreting it as a different code page, but that should not make a
difference because the byte in question is being translated to straight
ASCII-7 characters.
I can write a small translator to swap the 179(1) out to a 124(10) and
flag/blank/replace any extended ASCII characters if you want to, but to the
extent you have the ruby stuff choking I don't think the problem is there.
I can replace the ruby code with C code if you wish. Vanilla ANSI-C code
would be cleaner, I think, but if you are already running with ruby
elsewhere it might not be worth the time.
It is not clear to me from looking at the website how you go from the raw
file to the page. I don't mind helping there, but I would need a little
more info.
Can you give me some more info as to the environment this is running in? Is
it possible for me to set the existing system up here locally on my
machine?
I attempted to pull down pages from the site with curl, but it gives an
error. I also attempted to pull them down using Chrome in headless mode,
but got the same error:
==============
Trouble Encountered
names.txt
can't fetch document
See github
==============
The page sources in the browser for the working version of the references
you gave and the non-working version show up as byte for byte identical for
both URLs:
https://wiki.c2.com/?SmallTalkBestPracticePatterns
https://wiki.c2.com/?SmalltalkBestPracticePatterns
If I understood you correctly, you were saying that pages exist for both
the '*talk*' and the '*Talk*' versions of the URL. Are those sources also
identical?
Sorry this is a bit scattered. It's late...Note that I will be out of town
tomorrow, but will be back at it on Monday.
Cheers!
…On Fri, Sep 17, 2021 at 12:57 PM Ward Cunningham ***@***.***> wrote:
Looking back through this repo I found some of the programs I wrote to
make my initial conversion.
This program converted $SEP characters to an equally unlikely sequence,
<<<<gs>>>>, that would be allowed by ruby.
https://github.com/WardCunningham/remodeling/blob/master/json.c
This program was compiled to produce the executable, a.out, which was
invoked in a pipeline by the ruby program that did the bulk conversion.
https://github.com/WardCunningham/remodeling/blob/master/json.rb
The import logic that begins on line 9 would choke on some files. I
ignored these and carried on. Today, five years later, we are considering
how to make one of these files go through this conversion.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#51 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAEWAVYMDKKIWZPSVY7GBHTUCNXQDANCNFSM4WGCFYKQ>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
--
Bob Trower
--- From Gmail webmail account. ---
|
Hello,
The old Wiki taught me a lot of things I never would have encountered during my journey as a self-taught programmer. I would love to help bring it back to life, but I was having trouble determining the current status of remodeling efforts. Are there any specific items or areas where I can jump in and assist? Thank you for your time and all that you have done to freely spread knowledge of our craft.
The text was updated successfully, but these errors were encountered: