Home
Influx Proxy 是一个基于高可用、一致性哈希的 InfluxDB 集群代理服务,实现了 InfluxDB 高可用集群的部署方案,具有动态扩/缩容、故障恢复、数据同步等能力。连接到 Influx Proxy 和连接原生的 InfluxDB Server 没有显著区别 (支持的查询语句列表),对上层客户端是透明的,上层应用可以像使用单机的 InfluxDB 一样使用,Influx Proxy 会处理请求的转发,并对各个 InfluxDB 集群节点进行管理。Influx Proxy 基于饿了么开源的 Influx-Proxy,并进一步开发和优化,支持了更多的特性,移除了 Python、Redis 依赖,解决了受限于一个数据库、需要额外配置 KEYMAPS 、数据负载不均衡的问题。
注意:InfluxDB Cluster(一个开源的分布式时间序列数据库,InfluxDB Enterprise 的开源替代方案)已经发布,具有比 Influx Proxy 更好的特性,文档详见 InfluxDB Cluster Wiki 文档。

- client:influxdb-java、influxdb-shell (influx)、curl、浏览器等客户端
- load balance:负载均衡,如 F5、Nginx、LVS、HAProxy 等
- influx-proxy:influx-proxy 实例,架构示意图部署了两个 influx-proxy 实例
- circle:一致性哈希环(circle),一个 circle 包含了若干个 influxdb 实例,共同存储了一份全量的数据,即每个 circle 都是全量数据的一个副本,各个 circle 数据互备。不同 circle 不能包含相同 influxdb 实例,每个 circle 包含的 influxdb 实例个数可以不相等。circle 只是一种逻辑划分,无实体存在,架构示意图配置了三个 circle
- influxdb:influxdb 实例,以 url 进行区分,可以部署在同一服务器上以不同端口运行多个实例,一个 influxdb 实例只存储了一份全量数据的一部分数据
原理文章:一致性Hash(Consistent Hashing)原理剖析
- 一致性哈希算法解决了分布式环境下机器扩缩容时,简单的取模运算导致数据需要大量迁移的问题
- 一致性哈希算法能达到较少的机器数据迁移成本,实现快速扩缩容
- 通过虚拟节点的使用,一致性哈希算法可以均匀分担机器的数据负载
- 一个 circle 是一个逻辑上的一致性哈希环,包含少数的物理节点和更多数的虚拟节点
- 一个 circle 中的所有 influxdb 实例对应了这个一致性哈希环的物理节点
- 每个 circle 维护了一份全量数据,一个 influxdb 实例上的数据只是从属 circle 数据的一部分
- 每个 circle 数据存储位置计算:
shard_key(db,measurement) + hash_key(idx) + influxdb实例列表 + 一致性哈希算法 => influxdb实例 - 当
influxdb实例列表、hash_key、shard_key不发生改变时,db,measurement将只会唯一对应一台influxdb实例 - 当
influxdb实例列表、hash_key、shard_key发生改变时,需要对少量机器数据进行迁移,即 重新平衡 (rebalance)
- client 请求 load balance 地址
- load balance 根据负载均衡算法选择一个 influx-proxy 转发请求
- influx-proxy 收到请求,根据请求中 db 和 measurement 信息,每个 circle 使用一致性哈希算法计算出一个 influxdb 实例,并将请求转发给这些 influxdb 实例
- influxdb 实例处理请求,写入数据
- 若存在 influxdb 实例宕掉,或者网络、存储故障导致无法 influxdb 无法写入,则 influx-proxy 会将数据写入到缓存文件中,并直到 influxdb 实例恢复后重新写入
- client 请求 load balance 地址
- load balance 根据负载均衡算法选择一个 influx-proxy 转发请求
- 若请求中带有 db 和 measurement 信息,使用一致性哈希算法计算出所有 circle 对应的 influxdb 实例,并随机选择一个健康的 influxdb 实例,将请求转发给这个实例
- 若请求中只带有 db 信息,则判断为数据库相关的集群查询语句,并将请求转发给该 circle 的所有 influxdb 实例
- influxdb 实例处理请求,读出数据,返回给 influx-proxy
- 若是单个实例返回数据,则直接返回 client;若是多个实例返回数据,则合并后返回 client
- 支持 query 和 write
- 支持 /api/v2 接口端点
- 支持 flux 语言查询
- 支持部分集群 influxql
- 过滤了部分危险的 influxql
- 集群对上层客户端透明,如同单机 InfluxDB 访问
- 支持写入失败时将数据缓存到文件,然后重写
- 支持多个数据库的创建、存储和访问
- 支持数据库分库存储,基于一致性哈希
- 支持自定义哈希分片,用于调整数据库分库
- 支持动态扩/缩容、故障恢复、数据同步、数据清理等功能
- 部署简单,只有二进制程序和配置文件
- 支持写数据时附加 rp 和 precision 参数
- 支持 influxdb-java, influxdb shell 和 grafana 接入
- 支持 prometheus remote read he write 接口
- 支持 prometheus 监控及 /metrics 接口
- 支持认证和 https,支持 influxdb 的认证和 https
- 支持认证信息加密
- 支持 /health 健康状态检查
- 支持数据库白名单限制
- 支持版本信息显示
- 支持 gzip
最新稳定版本为 v2.5.12,适用于生产环境,更新日志详见更新日志 v2.5.12,下载地址:
- influx-proxy-2.5.12-darwin-amd64.tar.gz
- influx-proxy-2.5.12-darwin-amd64.zip
- influx-proxy-2.5.12-darwin-arm64.tar.gz
- influx-proxy-2.5.12-darwin-arm64.zip
- influx-proxy-2.5.12-linux-amd64.tar.gz
- influx-proxy-2.5.12-linux-amd64.zip
- influx-proxy-2.5.12-linux-arm64.tar.gz
- influx-proxy-2.5.12-linux-arm64.zip
- influx-proxy-2.5.12-windows-amd64.tar.gz
- influx-proxy-2.5.12-windows-amd64.zip
$ ./influx-proxy -h
Usage of ./influx-proxy:
-config string
proxy config file with json/yaml/toml format (default "proxy.json")
-version
proxy version
版本信息显示:
$ ./influx-proxy -version
Version: 2.5.12
Git commit: 6ce4816
Build time: 2024-08-15 09:51:44
Go version: go1.21.13
OS/Arch: linux/amd64
程序启动命令:
$ ./influx-proxy -config proxy.json
2024/08/09 20:46:37.527626 main.go:52: version: 2.5.12, commit: 6ce4816, build: 2024-08-15 09:51:44
2024/08/15 19:00:47.358669 config.go:179: 2 circles loaded from file
2024/08/15 19:00:47.358685 config.go:181: circle 0: 2 backends loaded
2024/08/15 19:00:47.358689 config.go:181: circle 1: 2 backends loaded
2024/08/15 19:00:47.358693 config.go:183: hash key: idx
2024/08/15 19:00:47.358696 config.go:184: shard key: %db,%mm
2024/08/15 19:00:47.358700 config.go:188: auth: false, encrypt: false
2024/08/15 19:00:47.360434 main.go:70: http service start, listen on :7076
一份配置文件示例如下,采用 JSON 格式(也可以使用 YAML 或者 TOML 格式):
{
"circles": [
{
"name": "circle-1",
"backends": [
{
"name": "influxdb-1-1",
"url": "http://127.0.0.1:8086",
"username": "",
"password": "",
"auth_encrypt": false,
"write_only": false
},
{
"name": "influxdb-1-2",
"url": "http://127.0.0.1:8087",
"username": "",
"password": "",
"auth_encrypt": false,
"write_only": false
}
]
},
{
"name": "circle-2",
"backends": [
{
"name": "influxdb-2-1",
"url": "http://127.0.0.1:8088",
"username": "",
"password": "",
"auth_encrypt": false,
"write_only": false
},
{
"name": "influxdb-2-2",
"url": "http://127.0.0.1:8089",
"username": "",
"password": "",
"auth_encrypt": false,
"write_only": false
}
]
}
],
"listen_addr": ":7076",
"db_list": [],
"data_dir": "data",
"tlog_dir": "log",
"hash_key": "idx",
"shard_key": "%db,%mm",
"flush_size": 10000,
"flush_time": 1,
"check_interval": 1,
"rewrite_interval": 10,
"rewrite_threads": 5,
"conn_pool_size": 20,
"write_timeout": 10,
"idle_timeout": 10,
"username": "",
"password": "",
"auth_encrypt": false,
"ping_auth_enabled": false,
"write_tracing": false,
"query_tracing": false,
"pprof_enabled": false,
"https_enabled": false,
"https_cert": "",
"https_key": "",
"tls": {
"ciphers": [],
"min_version": "",
"max_version": ""
}
}- 零值定义:
- 整数的零值:0,字符串的零值:"" (空字符串),布尔值的零值:false,列表的零值:[]
- 字段 未出现 在配置文件中:
- 以下字段说明中没有提及默认值的字段,若没有出现在配置文件中,程序将使用零值
-
circles: circle 列表-
name: circle 名称,要求不同 circle 名称不同,必填 -
backends: circle 包含的 influxdb 后端实例列表,必填-
name: 实例名称,要求不同后端实例名称不同,必填 -
url: 实例 url,支持 https 协议,必填 -
username: 实例认证用户,空则不启用认证,若auth_encrypt开启则启用认证加密 -
password: 实例认证密码,空则不启用认证,若auth_encrypt开启则启用认证加密 -
auth_encrypt: 是否启用认证加密,即用户和密码是否为加密文字,默认为false -
write_only: 是否只写,若启用则该只写不读 (v2.5.8 开始支持),默认为false
-
-
-
listen_addr: proxy 监听地址ip:port,一般不绑定ip,默认为:7076 -
db_list: 允许访问的 db 列表,空则不限制 db 访问,默认为[] -
data_dir: 保存写入失败的数据的缓存目录,存放 .dat 和 .rec 文件,默认为data -
tlog_dir: 用于记录重新平衡、故障恢复、数据同步、错误数据清理的日志目录,默认为log -
hash_key: 配置一致性哈希算法的后端 key,可选值为idx、exi、name、url或包含%idx的模板,分别使用 backend 实例的 索引、扩展索引、name、url、模板的值进行 hash,默认值为idx- 一旦 hash_key 设定,尽量不要变更,否则需要 rebalance 或
influx-tool transfer - hash_key 可以设置任意包含
%idx的模板,如backend-%idx,%idx表示 circle 中 influxdb 实例的索引,v2.5.12 开始支持,详见哈希分片 - 若 backend 实例的 index、name、url 的值发生变更,也会导致 hash 策略发生变化,从而需要 rebalance,如新增 backend 实例、name 变更、url 从 http 协议变成 https 协议等,默认值
idx会使得一致性哈希更加稳定,从而减少 rebalance - 扩展索引
exi是 索引idx的扩展版,v2.5.3 开始支持,一个 circle 中的 influxdb 实例数量大于 10 时建议使用exi - 版本兼容情况详见版本升级
- 一旦 hash_key 设定,尽量不要变更,否则需要 rebalance 或
-
shard_key: 配置数据分片哈希的模板 key,该模板须包含%db或%mm,,默认值为%db,%mm- 一旦 shard_key 设定,尽量不要变更,否则需要 rebalance 或
influx-tool transfer - shard_key 可以设置任意包含
%db或%mm的模板,如shard-%db-%mm,%db和%mm分别表示数据中的 database 和 measurement,v2.5.12 开始支持,详见哈希分片
- 一旦 shard_key 设定,尽量不要变更,否则需要 rebalance 或
-
flush_size: 写数据时缓冲的最大点数,达到设定值时将一次性批量写入到 influxdb 实例,默认为10000 -
flush_time: 写数据时缓冲的最大时间,达到设定值时即使没有达到flush_size也进行一次性批量写入到 influxdb 实例,单位为秒,默认为1 -
check_interval: 检查 influxdb 后端实例是否存活的间隔时间,默认为1秒 -
rewrite_interval: 向 influxdb 后端实例重写缓存失败数据的间隔时间,默认为10秒 -
rewrite_threads: 重写缓存的线程数量,默认为5 -
conn_pool_size: 创建 influxdb 后端实例写入的连接池大小,默认为20 -
write_timeout: 向 influxdb 后端实例写数据的超时时间,默认为10秒 -
idle_timeout: 服务器 keep-alives 的等待时间,默认为10秒 -
username: proxy 的认证用户,空则不启用认证,若auth_encrypt开启则启用认证加密 -
password: proxy 的认证密码,空则不启用认证,若auth_encrypt开启则启用认证加密 -
auth_encrypt: 是否启用认证加密,即用户和密码是否为加密文字,默认为false -
ping_auth_enabled: 在/ping和/metrics接口上启用认证,默认为false -
write_tracing: 写入请求的日志开关,默认为false -
query_tracing: 查询请求的日志开关,默认为false -
pprof_enabled: 是否启用/debug/pprofhttp 端点,默认为false -
https_enabled: 是否启用 https,默认为false -
https_cert: ssl 证书路径,https_enabled开启后有效 -
https_key: ssl 私钥路径,https_enabled开启后有效 -
tls: tls 配置-
ciphers: 启用 https 时要协商的一组密码套件 id,参考 ciphersMap,默认为[] -
min_version: tls 协议最小版本,可选值为tls1.0、tls1.1、tls1.2和tls1.3,https_enabled开启后有效 -
max_version: tls 协议最大版本,可选值为tls1.0、tls1.1、tls1.2和tls1.3,https_enabled开启后有效
-
hash_key 和 shard_key 共同控制数据应该写入哪个 influxdb 实例。
hash_key 是一致性哈希算法的后端 key,包括 idx、exi、name、url 或包含 %idx 的模板(%idx 是 circle 中 influxdb backend 实例的索引),例如 backend-%idx。
shard_key 是数据分片哈希的模板 key,包含 %db 或 %mm(%db 和 %mm 分别是数据中的 database 和 measurement),例如 shard-%db-%mm。
为了避免数据倾斜(即数据分布不均匀),hash_key 和 shard_key 都需要适当设置。设置之前,influx-tool hashdist 可以帮助模拟和测试哈希分布。例如,执行
$ head -n 3 table.csv
db1,cpu1
db1,cpu2
db2,cpu3
$ influx-tool hashdist -n 6 -k backend-%idx -K shard-%db-%mm -f table.csv -D -
node total: 6, hash key: backend-%idx, shard key: shard-%db-%mm, total hits: 40
node index: 0, hits: 5, percent: 12.5%, expect: 16.7%
node index: 1, hits: 5, percent: 12.5%, expect: 16.7%
node index: 2, hits: 9, percent: 22.5%, expect: 16.7%
node index: 3, hits: 7, percent: 17.5%, expect: 16.7%
node index: 4, hits: 7, percent: 17.5%, expect: 16.7%
node index: 5, hits: 7, percent: 17.5%, expect: 16.7%测试单个 database 和 measurement 分布:
$ influx-tool hashdist -n 10 -d db1 -m cpu1
node total: 10, hash key: idx, shard key: %db,%mm, database: db1, measurement: cpu1
node index: 4注意: 一旦 hash_key 和 shard_key 之一发生更改,就需要 rebalance 或 influx-tool transfer
访问:https://github.com/chengshiwen/influx-proxy/tree/master/docker/quick
下载 docker-compose.yml 和 proxy.json,执行:
docker-compose up -d
将会启动 1 个 influx-proxy 容器(端口为 7076)和 4 个 influxdb 容器(共 2个 circle,每个 circle 有 2 个 influxdb)
自定义修改 proxy.json,执行(注意将 /path/to/custom/proxy.json 替换为实际路径):
docker run -d --name influx-proxy -e TZ=Asia/Shanghai -v /path/to/custom/proxy.json:/etc/influx-proxy/proxy.json chengshiwen/influx-proxy:latest
将会启动 1 个 influx-proxy 容器(端口为 7076)
访问:https://github.com/influxtsdb/helm-charts/tree/master/charts/influx-proxy
下载 InfluxDB Proxy Helm chart,执行:
helm install influx-proxy ./influx-proxy
将会启动 1 个名为 influx-proxy 的 release
GRANTREVOKEKILLEXPLAINSELECT INTOCONTINUOUS QUERY-
多个语句,以分号(;)分隔 -
多个 measurement,以逗号(,)分隔 正则 measurement
select fromshow fromshow measurementsshow seriesshow field keysshow tag keysshow tag valuesshow statsshow databasescreate databasedrop databaseshow retention policiescreate retention policyalter retention policydrop retention policydelete fromdrop series fromdrop measurementon clause-
from clause如from <db>.<rp>.<measurement>
InfluxDB Java 客户端:influxdb-java 2.5+,兼容 influx-proxy 和 influxdb 查询
涉及 CREATE, DELETE 或 DROP 语句,请务必使用 POST 方式,Query 构造函数第三个参数需要设置为 true,否则可能会导致语句执行不成功:
Query(final String command, final String database, final boolean requiresPost)
官方文档:/query HTTP endpoint
| 方法 | 查询类型 |
|---|---|
| GET | 用于所有以以下子句开头的查询:SELECT (不包括 SELECT INTO), SHOW
|
| POST | 用于所有以以下子句开头的查询:ALTER, CREATE, DELETE, DROP, GRANT, KILL, REVOKE, SELECT INTO
|
InfluxDB-Java 使用示例如下:
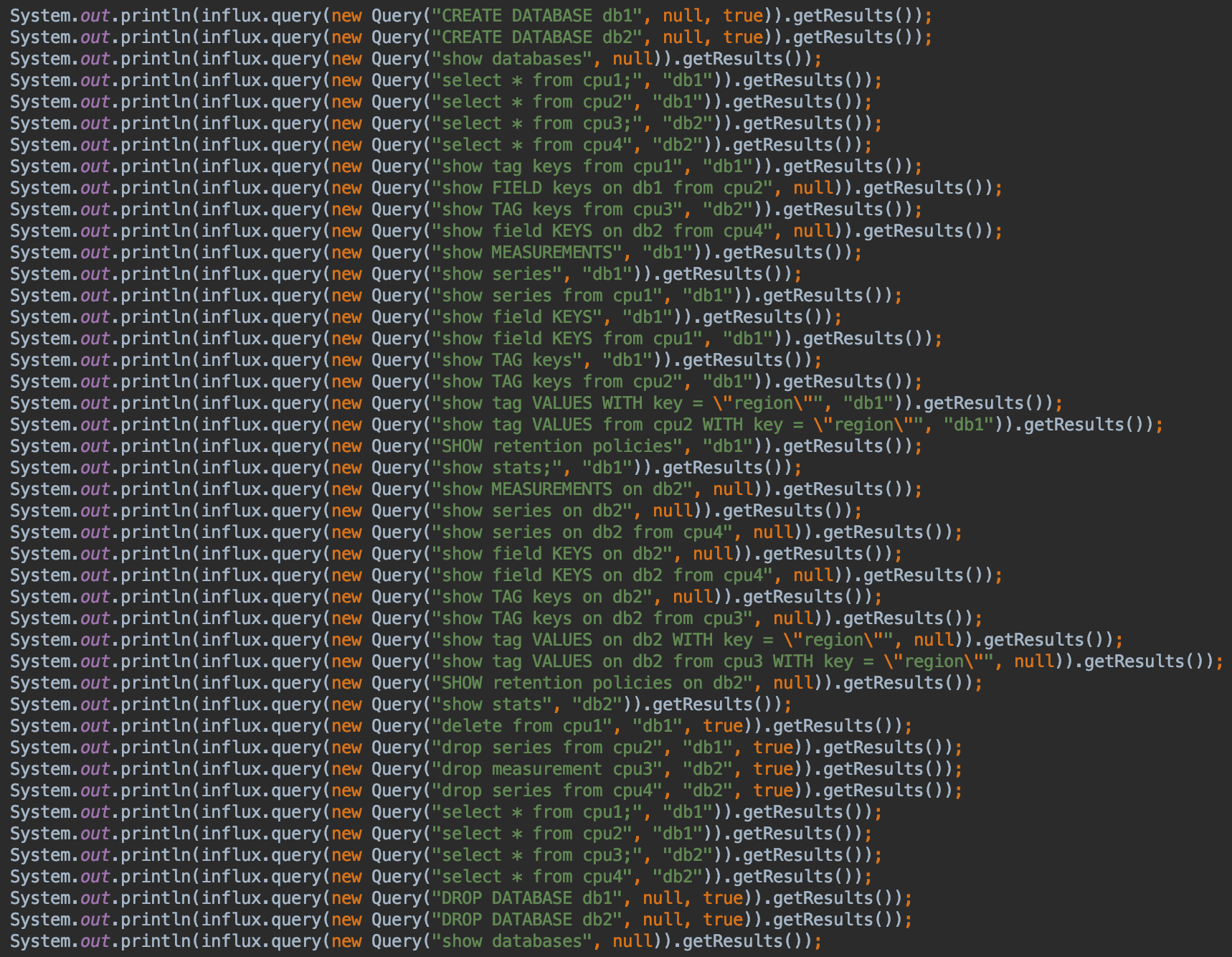
以下适用于生产环境
- 架构:
- 使用负载均衡,部署至少两个 influx proxy,推荐两个 influx proxy 的方案 (proxy 的 data 目录需要互相隔离)
- 使用至少两个 circle,推荐两个 circle 的方案
- 每个 circle 的 influxdb 实例数量根据实际数据情况进行配置,参考硬件资源,建议至少三个
- 存储:
- 使用网络共享存储,如 NAS、SAN 等,避免服务器故障无法恢复、导致数据丢失的问题
- 建议 SSD 固态硬盘,提升硬盘读写 IOPS;HDD 机械硬盘会导致 IOPS 降低、性能下降
- 涉及存储:influxdb 实例持久化数据、influx-proxy 实例写入失败的缓存文件数据
官方给出单机单节点 InfluxDB 性能测试数据参考:
| CPU | 内存 | IOPS | 每秒写入 | 每秒查询* | 唯一series |
|---|---|---|---|---|---|
| 2-4 核 | 2-4 GB | 500 | <5,000 | <5 | <100000 |
| 4-6 核 | 8-32 GB | 500-1000 | <250000 | <25 | <1000000 |
| 8+ 核 | 32+ GB | 1000+ | >250000 | >25 | >1000000 |
* 每秒查询指中等查询,查询对系统的影响差异很大,查询复杂度由以下条件定义:
| 查询复杂度 | 标准 |
|---|---|
| 简单 | 很少或没有函数,也没有正则表达式 |
| 时间限制为几分钟,几小时或最多24小时 | |
| 通常在几毫秒到几十毫秒内执行 | |
| 中等 | 具有多种函数和一两个正则表达式 |
也可能有GROUP BY子句或对采样时间范围为几个星期的数据 |
|
| 通常在几百或几千毫秒内执行 | |
| 复杂 | 具有多个聚合或转换函数或多个正则表达式 |
| 可能会采样时间范围为几个月或几年的数据 | |
| 通常需要几秒钟才能执行 |
- 预估每秒写入的总数据量、每秒查询的总请求数,建议单台每秒写入不超过 250000
- 确定一个合适的单节点每秒写入量,根据每秒写入的总数据量,大致确定单台机器硬件资源配置
- 计算出每个 circle 大致需要的 influxdb 实例的个数,并增加一定冗余机器
- 二进制:通过 supervisord、systemd、upstart 等管理
- 容器:通过 docker/k8s 部署,自带自启动、重启管理
- 支持 InfluxDB 1.2-1.8,建议使用 1.6+,支持更好基于磁盘的时序数据索引
- InfluxDB 2.0+,详见 influxdb-v2 和 Release v3.0.0
常见选项的默认配置 (influxdb.conf):
# 禁止报告开关,默认 每 24 小时往 usage.influxdata.com 发送报告
reporting-disabled = false
# 用于备份和恢复的 RPC 服务的绑定地址
bind-address = "127.0.0.1:8088"
[meta]
# 元数据存储目录
dir = "/var/lib/influxdb/meta"
# retention policy 自动创建开关
retention-autocreate = true
# 元数据服务日志开关
logging-enabled = true
[data]
# 数据目录
dir = "/var/lib/influxdb/data"
# 预写日志目录(write ahead log)
wal-dir = "/var/lib/influxdb/wal"
# fsync 调用之前的写等待时间,默认为 0s,SSD 设置为 0s,非 SSD 推荐设置为 0ms-100ms
wal-fsync-delay = "0s"
# inmem 内存索引(需要大量内存),tsi1 基于磁盘的时序索引
index-version = "inmem"
# 查询日志开关
query-log-enabled = true
# 分片缓存在拒绝 /write 请求前能写入的最大内存大小,默认为 1g
cache-max-memory-size = "1g"
# tsm 引擎将快照缓存并将其写入 tsm 文件的缓存大小,完成后释放内存
cache-snapshot-memory-size = "25m"
# 持续一段时间后,如果分片没有收到写入或删除,tsm 引擎将对缓存进行快照并将其写入新的 TSM 文件
cache-snapshot-write-cold-duration = "10m"
# 持续一段时间后,如果 tsm 引擎未收到写入或删除,tsm 引擎将压缩分片中的所有 TSM 文件
compact-full-write-cold-duration = "4h"
# tsm 压缩每秒写入磁盘的平均字节数,允许短暂突发瞬间可以达到 compact-throughput-burst
compact-throughput = "48m"
# tsm 压缩在短暂突发瞬间每秒写入磁盘的最大字节数
compact-throughput-burst = "48m"
# 最大并发压缩数,默认值 0 会将 50% 的 CPU 核心数用于压缩
max-concurrent-compactions = 0
# inmem 设置项:在删除写入之前每个数据库允许的 series 的最大数量,设置 0 则不限制
max-series-per-database = 1000000
# inmem 设置项:每个 tag 键允许的 tag 值的最大数量,设置 0 则不限制
max-values-per-tag = 100000
# tsi1 设置项:预写日志 wal 文件将压缩为索引文件时的阈值大小
# 较小的阈值将导致日志文件更快地压缩,并导致较低的堆内存使用量,但会以写入吞吐量为代价
# 更大的阈值将不会频繁地压缩,在内存中存储更多的 series,并提供更高的写入吞吐量
max-index-log-file-size = "1m"
# tsi1 设置项:tsi 索引中用于存储先前计算的 series 结果的内部缓存大小
# 缓存结果将从缓存中快速返回,而不需要对匹配 tag 键值的后续查询进行重新计算
# 将此值设置为 0 将禁用缓存,这可能会导致查询性能问题
series-id-set-cache-size = 100
[coordinator]
# 写入请求超时时间
write-timeout = "10s"
# 最大并发查询数,默认值 0 表示不限制
max-concurrent-queries = 0
# 在终止查询之前允许执行查询的最长持续时间,默认值 0 表示不限制
query-timeout = "0s"
# 慢查询的最大持续时间,一个查询超出该时间将打印 Detected slow query 日志
# 默认值 0s 表示不记录慢查询
log-queries-after = "0s"
[retention]
# 执行保留策略并淘汰旧数据开关
enabled = true
# 执行保留策略的检查时间间隔
check-interval = "30m0s"
[monitor]
# 内部记录统计信息开关,生产环境中若数据量较大,建议关闭
store-enabled = true
# 记录统计信息的数据库
store-database = "_internal"
# 记录统计信息的时间间隔
store-interval = "10s"
[http]
# http 开关
enabled = true
# http 绑定地址
bind-address = ":8086"
# 认证开关
auth-enabled = false
# http 请求日志
log-enabled = true
# 详细写入日志开关
write-tracing = false
# flux 查询开关
flux-enabled = false
# flux 查询日志开关
flux-log-enabled = false
# pprof http 开关,用于故障排除和监控
pprof-enabled = true
# 启用 /pprof 端点并绑定到 localhost:6060,用于调试启动性能问题
debug-pprof-enabled = false
# https 开关
https-enabled = false
# https 证书
https-certificate = "/etc/ssl/influxdb.pem"
# https 私钥
https-private-key = ""
# 查询返回的最大行数,默认值 0 允许无限制
max-row-limit = 0
# 最大连接数,超过限制的新连接将被丢弃,默认值 0 禁用限制
max-connection-limit = 0
# 客户端请求 body 的最大大小(以字节为单位),设置为 0 则禁用限制
max-body-size = 25000000
# 访问日志路径,若设置并当 log-enabled 启用时,请求日志将写入到该文件
# 默认则写入 stderr,与 influxdb 日志混合在一起
access-log-path = ""
# 请求记录状态过滤,例如 ["4xx", "5xx"],默认 [] 表示无过滤,所有请求被记录打印
access-log-status-filters = []
# 最大并发处理的写入数,设置为 0 则禁用限制
max-concurrent-write-limit = 0
# 最大排队等待处理的写入数,设置为 0 则禁用限制
max-enqueued-write-limit = 0
# 写入在待处理队列中等待的最大持续时间
# 设置为 0 或将 max-concurrent-write-limit 设置为 0 则禁用限制
enqueued-write-timeout = "30s"
[logging]
# 日志等级,error、warn、info(默认)、debug
level = "info"重点配置 (cpu/内存/磁盘io/超时/日志):
# 禁用报告,默认为 false
reporting-disabled = true
[meta]
# 元数据存储目录
dir = "/var/lib/influxdb/meta"
[data]
# 数据目录
dir = "/var/lib/influxdb/data"
# 预写日志目录(write ahead log)
wal-dir = "/var/lib/influxdb/wal"
# fsync 调用之前的写等待时间,默认为 0s,SSD 设置为 0s,非 SSD 推荐设置为 0ms-100ms
# 若要降低磁盘 io,则适当调大
wal-fsync-delay = "20ms"
# inmem 内存索引(需要大量内存),tsi1 基于磁盘的时序索引,默认为 inmem
index-version = "tsi1"
# 查询日志开关,可视情况关闭
query-log-enabled = true
# 分片缓存在拒绝 /write 请求前能写入的最大内存大小,默认为 1g
# 若服务器内存较小,则适当调小;若要降低磁盘 io,则适当调大
cache-max-memory-size = "1g"
# tsm 引擎将快照缓存并将其写入 tsm 文件的缓存大小,完成后释放内存,默认为 25m
# 若服务器内存较小,则适当调小;若要降低磁盘 io,则适当调大
cache-snapshot-memory-size = "25m"
# 持续一段时间后,如果分片没有收到写入或删除,tsm 引擎将对缓存快照并写入新的 TSM 文件,默认为 10m
# 若要降低 cpu 压缩计算和磁盘 io,则适当调大,但避免时间过长一直占用内存
cache-snapshot-write-cold-duration = "10m"
# 持续一段时间后,如果 tsm 引擎未收到写入或删除,tsm 引擎将压缩分片中的所有 TSM 文件,默认为 4h
# 若要降低 cpu 压缩计算和磁盘 io,则适当调大
compact-full-write-cold-duration = "4h"
# tsm 压缩每秒写入磁盘的平均字节数,默认为 48m,允许短暂突发瞬间可以达到 compact-throughput-burst
# 若要降低磁盘 io,则适当调小,但避免过小导致压缩周期变长
compact-throughput = "48m"
# tsm 压缩在短暂突发瞬间每秒写入磁盘的最大字节数,默认为 48m
# 若要降低磁盘 io,则适当调小,但避免过小导致压缩周期变长
compact-throughput-burst = "48m"
# 最大并发压缩数,默认值 0 会将 50% 的 CPU 核心数用于压缩
# 若要降低 cpu 压缩计算和磁盘 io,则适当调小,但避免过小导致压缩周期变长
max-concurrent-compactions = 0
# tsi1 设置项:预写日志 wal 文件将压缩为索引文件时的阈值大小
# 较小的阈值将导致日志文件更快地压缩,并导致较低的堆内存使用量,但会以写入吞吐量为代价
# 更大的阈值将不会频繁地压缩,在内存中存储更多的 series,并提供更高的写入吞吐量
# 若要降低 cpu 压缩计算和磁盘 io,则适当调大,但避免过大导致一直占用内存
# 若服务器内存较小,则适当调小或保持不变
max-index-log-file-size = "1m"
# tsi1 设置项:tsi 索引中用于存储先前计算的 series 结果的内部缓存大小
# 缓存结果将从缓存中快速返回,而不需要对匹配 tag 键值的后续查询进行重新计算
# 将此值设置为 0 将禁用缓存,这可能会导致查询性能问题
# 若服务器内存较小,则适当调小
series-id-set-cache-size = 100
[coordinator]
# 写入请求超时时间,默认为 10s
write-timeout = "20s"
[monitor]
# 内部记录统计信息开关,生产环境中若数据量较大,会影响内存及cpu,建议关闭
store-enabled = true
# 记录统计信息的时间间隔,生产环境中若数据量较大,但需要开启监控,则调大间隔
store-interval = "10s"
[http]
# http 请求日志,可视情况关闭
log-enabled = true
[logging]
# 日志等级,error、warn、info(默认)、debug,可视情况调整等级
level = "info"环境变量 (supervisor/docker/k8s):
INFLUXDB_REPORTING_DISABLED=true
INFLUXDB_META_DIR=/var/lib/influxdb/meta
INFLUXDB_DATA_DIR=/var/lib/influxdb/data
INFLUXDB_DATA_WAL_DIR=/var/lib/influxdb/wal
INFLUXDB_DATA_WAL_FSYNC_DELAY=20ms
INFLUXDB_DATA_INDEX_VERSION=tsi1
INFLUXDB_DATA_QUERY_LOG_ENABLED=true
INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=1g
INFLUXDB_DATA_CACHE_SNAPSHOT_MEMORY_SIZE=25m
INFLUXDB_DATA_CACHE_SNAPSHOT_WRITE_COLD_DURATION=10m
INFLUXDB_DATA_COMPACT_FULL_WRITE_COLD_DURATION=24h
INFLUXDB_DATA_COMPACT_THROUGHPUT=48m
INFLUXDB_DATA_COMPACT_THROUGHPUT_BURST=48m
INFLUXDB_DATA_MAX_CONCURRENT_COMPACTIONS=0
INFLUXDB_DATA_MAX_INDEX_LOG_FILE_SIZE=1m
INFLUXDB_DATA_SERIES_ID_SET_CACHE_SIZE=100
INFLUXDB_COORDINATOR_WRITE_TIMEOUT=20s
INFLUXDB_MONITOR_STORE_ENABLED=true
INFLUXDB_MONITOR_STORE_INTERVAL=10s
INFLUXDB_HTTP_LOG_ENABLED=true
INFLUXDB_LOGGING_LEVEL=info内存释放:
- 当 Linux 内核版本 >= 4.5 时,Go 1.12-1.15 版本的 Runtime 在 Linux 上默认使用了性能更为高效的
MADV_FREE策略,而不是之前的MADV_DONTNEED,导致进程 RSS (物理内存) 不会立刻下降,直到系统有内存压力了才会释放占用 - Go 版本 <= 1.11 或 >= 1.16,Go Runtime 在 Linux 上默认使用的是
MADV_DONTNEED策略,进程 RSS (物理内存) 下降得比较快,但性能效率上可能差些
influxdb 受到 MADV_FREE 影响的版本:
- 1.7.9-1.7.10: go1.12.6
- 1.7.11-1.8.10: go1.13.8
- 2.0.0-2.0.7: go1.15.2
上述 influxdb 版本若要强制使用 MADV_DONTNEED 策略,需添加环境变量 GODEBUG=madvdontneed=1,例如
# 二进制
GODEBUG=madvdontneed=1 /usr/bin/influxd -config /etc/influxdb/influxdb.conf
# docker
docker run -d -e GODEBUG=madvdontneed=1 influxdb:1.8采用 grafana:5.2.4 对各个 influxdb 实例进行监控,导入 dashboard.json,将创建监控仪表盘:

导入方法:
- 导入 Dashboard: Create -> Import -> Upload .json File -> Import,将导入名为 InfluxDB Metrics 的 Dashboard
- 配置 Data Sources: Add data source -> 创建名字包含 influxdb 且 Type 为 InfluxDB 的数据源,将自动匹配该 Dashboard
监控指标说明:
-
Memory:Sys、Heap Sys、Heap In Use
- 分配的堆栈数据总内存、堆内存(包含正在使用和未释放的内存)、正在使用的堆内存
-
HTTP Writes、HTTP Queries
- 每秒写入、查询的请求数,单位为 ops
-
Write Bytes、Query Bytes
- 每秒写入、查询的数据字节大小
-
Points Written、HTTP Errors
- 每秒已写入的点数、错误请求数,单位为 ops
-
Number of Series、Number of Measurements
- Series 和 Measurements 的个数,其大小会直接影响内存使用大小
- Series 的个数 (不包括
_internal,其为 influxdb 的内部数据库) 对内存影响最大
- 优化启动信息显示,避免
read meta error: EOF误以为是错误日志- 修复缩容时,旧 influxdb 实例有认证导致无法迁移数据的问题
- 修复错误数据清理 clear 操作代码中匿名函数传参不正确导致不能完整清理数据的问题
- 修复迁移时可能会有个别数据未迁移的问题
- 修复删除语句处理不正确的问题:
delete from、drop measurement- 优化 json 处理性能
- 处理数据写入、查询、缓存失败数据重写时,支持更多日志输出
- 重构缓存失败数据重写代码逻辑
- 优化 db 检查,db 禁止访问时,输出 db 日志信息
- 支持写入数据时提前检查不合法的数据,并输出数据日志信息
- 配置文件 proxy.json 变更:
- 新增
hash_key,配置说明见配置字段说明- 新增
check_interval,支持配置后端实例检查存活的间隔时间- 新增
rewrite_interval,支持配置后端实例重写数据的间隔时间- 新增
write_timeout,支持配置后端实例写数据的超时时间- 新增
idle_timeout,支持配置服务器 keep-alives 等待的超时时间- 新增
log_enabled,支持输出 debug 日志信息用于故障排查- 支持对 proxy.json 未配置项设置默认值,默认值说明见配置字段说明
- 支持对 influxdb 实例配置进行检查校验
- 支持 http 接口
/health查询所有 influxdb 实例的健康状态- 支持 http 接口
/replica查询 db,measurement 对应数据存储的所有 influxdb 实例副本- 支持所有 http 接口附带 pretty 参数,以美化的 json 格式输出
- 重命名 http 接口:
- 迁移进度统计信息查询接口
/status变更为/migrate/stats- 设置和查询迁移状态标志接口
/migrating变更为/migrate/state- 修复多个 influx-proxy 部署时,rebalance、recovery、resync、clear 状态不一致的问题
- 对所有 http 接口添加认证检查,除了接口
/ping、/encrypt和/decrypt- 优化所有 http 接口 method 和 auth 检查的代码,提升代码复用性
- 完全优化认证加密代码,修改加密密钥
- 修复写数据被丢弃的罕见问题:数据没有时间戳、precision 参数不是 ns 的情况
- 支持查询语句
drop database、drop series from和on clause- 重构 query 代码逻辑,移除正则表达式匹配查询语句的代码,提升查询性能
- 优化读写请求错误时的错误信息返回,支持 influxdb shell 正确显示错误信息
- 修复重写老版本缓存的失败数据时导致 index out of range 的问题
- 支持重启后对已缓存的失败数据进行重写
- 支持配置文件配置项检查
- 优化读写请求的日志输出
- 修复重写缓存失败数据时,db 名称包含转义字符的问题
- 迁移数据时支持 field 中包含多种数据类型的情况
- 配置文件 proxy.json 变更:
backends配置增加字段auth_secure,支持独立配置auth_securehash_key新增支持exi,一个 circle 中的 influxdb 实例数量大于 10 时建议exi,即扩展索引,默认依然为idx- 移除
vnode_size- 移除
log_enabled,拆分为write_tracing和query_tracing- 变更
mlog_dir为tlog_dir- 新增
conn_pool_size,创建 influxdb 后端实例写入的连接池大小,默认为20- 新增
write_tracing,写入请求的日志开关,默认为false- 新增
query_tracing,查询请求的日志开关,默认为false- 提升性能:
- 写入性能提升:移除互斥锁,添加协程池,关键函数性能优化
- 查询性能提升:增加查询哈希的缓存,集群语句查询并发性能优化
- 迁移性能提升:添加协程池,分批查询、多批并行写入性能优化
- 更换高性能库:compress/gzip 更换为 klauspost/pgzip
- 健康接口性能提升:并行查询性能优化
- 问题修复及优化:
- 修复写入数据语句有前置空格导致无法写入的问题
- 修复 field 中字符串包含反斜杠 "\" 导致无法写入的问题
- 修复重新平衡、故障恢复、数据同步等迁移操作不支持包含双引号的 measurement
- 统一优化错误信息的返回格式为 json
- 重新平衡、故障恢复、数据同步等迁移操作支持错误重试,最多 10 次
- 代码、结构调整优化,逻辑、结构更清晰
- 重命名 http 接口:
- 数据清理接口
/clear变更为/cleanup- 迁移进度统计信息查询接口
/migrate/stats变更为/transfer/stats- 设置和查询迁移状态标志接口
/migrate/state变更为/transfer/state- 变更部分 http 接口的参数和返回:
/health:返回 body 部分更新,详见 接口 /health/replica:返回 body 部分更新,详见 接口 /replica/encrypt:请求参数 msg 变更为 text,详见 接口 /encrypt/decrypt:请求参数 msg 变更为 text,详见 接口 /decrypt/rebalance:请求参数 db、cpus 分别变更为 dbs、worker,新增 batch、limit,详见 接口 /rebalance/recovery:请求参数 db、cpus 分别变更为 dbs、worker,新增 batch、limit,详见 接口 /recovery/resync:请求参数 seconds、db、cpus 分别变更为 tick、dbs、worker,新增 batch、limit,详见 接口 /resync/cleanup:请求参数 cpus 变更为 worker,新增 batch、limit,详见 接口 /cleanup/transfer/state:请求参数 migrating 变更为 transferring,返回 body 部分更新,详见 接口 /transfer/state/transfer/stats:返回 body 部分更新,详见 接口 /transfer/stats
- 优化日志输出,增加启动版本信息显示
- 优化 influxdb 实例故障时的查询策略
- 修复迁移操作中 int64 转换为 float64 导致精度丢失的问题
- 优化迁移操作中时间解析的性能
- 修复并发情况下存在数据竞争的问题
- 修复少数情况下从查询语句中获取 measurement 错误的问题
- 重构查询器的代码,对集群语句改为查询并集的策略
- 配置文件 proxy.json:所有
auth_secure变更为auth_encrypt(包括backends),语义更清晰
- 支持 retention policy 的查询语句
create retention policyalter retention policydrop retention policy- 支持
db.rp.measurement的 from 子句查询- 支持 subquery 语句(仅针对单个 measurement)
- 支持 yaml/toml 格式的配置文件
- 修复 windows 上的 issue #11
- 修复 gzip 压缩错误,替换为 compress/gzip 以保证兼容性
- 禁止
_internal数据库查询
- 修复 field value 包含换行符
\n导致 line protocol 写入错误的问题- 修复 select 字符串作为前缀的 measurement 无法查询的问题(v2.5.6 支持 subquery 语句后引入该问题)
- 修复 select 语句中 field keys 以无空格的逗号拼接且包含空格或点号时,查询返回 illegal influxql 的问题
- 开放
_internal数据库查询 #32- 支持 flux-dsl #46
- 支持
/api/v2/query和/api/v2/write接口 #54- 支持
influx -type=flux -path-prefix=/api/v2/query命令行- 兼容 influxdb
/health接口
- 支持
ping_auth_enabled配置 #65- 修复 read length error: EOF #67
- 修复 cve-2016-2183 ssl/tls 协议信息泄露漏洞,详见
tls配置 (ciphers、min_version、max_version)- 支持
show语句附带limit offset子句- 增加 prometheus 监控,支持
/metrics接口- 支持
rewrite_threads配置,提升重写时消费 .dat 文件的速度,速度提升到 ~3x- 优化迁移时
select * from limit全表扫描性能低的问题 #60- 移除所有迁移接口的
limit参数
- 支持自定义
hash_key和shard_key模板 #68
- 两个参数共同控制数据写入到哪个 influxdb 实例,详见哈希分片
- 支持
influx-tool hashdist命令模拟测试 hash 分布情况- 所有迁移接口支持
since参数,其作用和tick参数相同(tick仍然有效),语义更为清晰/replica接口支持mm参数,其作用和meas参数相同(meas仍然有效),参数更为简洁
- query 支持负载均衡策略
- 支持热加载配置 #29,详见 hot-reload
- 支持分号分隔的多语句查询 #61
- 支持 hash 路由和自定义路由规则 #68
- 支持 clickhouse 输出 #35
- 支持 show cardinality 相关查询语句(show series cardinality 等)
- 支持 udp 协议
- 将 influx-proxy 分离为两部分:
- 核心程序:influx-proxy,基于一致性哈希的高可用集群代理程序,提升一致性哈希的均匀性,达到分库分表,无明显 Bug 且易于维护
- 配套工具:influx-tool,配套工具,支持高性能的迁移 (transfer)、压缩 (compact)、导出 (export)、导入 (import)、清理 (cleanup) 操作,与 influx-proxy 解耦
- 适配 influxdb v2,详见 influxdb-v2
-
proxy.json:对应字段修改适配到最新版本- v2.5.5 开始,
backends配置增加字段auth_encrypt,支持独立配置是否启用认证加密 - v2.5.8 开始,
backends配置增加字段write_only,支持独立配置是否启用只写 - 保持:
hash_key保持idx不变即可 - 移除
log_enabled,拆分为write_tracing和query_tracing - 变更
mlog_dir为tlog_dir - 移除
vnode_size
- v2.5.5 开始,
- 分布式系统的三个指标:CAP 定理的含义
- Consistency:一致性
- Availability:可用性
- Partition tolerance:分区容错
-
CAP 定理:C、A、P 三个指标不可能同时达到,其中 P 总是成立
- 一致性 和 可用性 只能选择其一
- 只能实现 CP 或 AP
-
influx proxy 实现了可用性,即达到 AP
- 时序数据能容忍极少数数据丢失或者不一致
- 可以定期通过数据同步工具达到数据一致性
- 官方 influxdb 集群也实现了可用性,定期同步数据以解决 脏读问题 (数据读取不一致)
基于代理方案,数据处理操作较少,写性能和读性能与 circles 的配置、数据特征(哈希分库)、查询语句等密切相关,基于 influx-stress,influxdb-comparisons 和 tsbs (Time Series Benchmark Suite) 测试,得出
最好情况:数据均匀划分到所有 influxdb 实例上
- 写性能:约等于单个 circle 的所有 influxdb 实例的写入性能总和 * 90%
- 读性能:约等于所有 circle 的所有 influxdb 实例的查询性能总和 * 90%
最坏情况:数据全部划分到一个 influxdb 实例上
- 写性能:约等于单个 circle 的一个 influxdb 实例的写入性能总和 * 90%
- 读性能:约等于所有 circle 的一个 influxdb 实例的查询性能总和 * 90%
- 架构部署方案:
- influx proxy 故障:
- 部署两个 proxy,由于无状态,一个 proxy 死掉不会影响另一个 proxy,具备高可用性
- 若 proxy 在缓存失败数据时死掉,则 proxy 启动时会读取缓存文件并恢复重写,写入数据不会丢失
- 建议使用网络共享存储,避免机器故障完全坏掉导致缓存失败数据丢失
- influxdb 故障:
- 若 influxdb 服务死掉或 influxdb 机器坏掉,则其它 circle 仍然能提供写入和查询服务,具备可用性;本 circle 将可以继续写入数据、提供部分查询能力,具备写可用性、部分读可用性(下简称 “全写少读” 状态,标记为 not active),直到重新运行后,全写少读状态解除变成读写完全可用状态
- 若 influxdb 服务死掉,则 proxy 会缓存失败数据,当 influxdb 恢复后进行重写,故写入数据不会丢失
- 若 influxdb 机器完全坏掉,数据不可恢复,则快速补充新机器,所属 circle 将变成 全写少读 (not active) 状态,直到 influxdb 重新运行后进行重写;同时后台里从其它健康的 circle 进行数据恢复,直到数据恢复完成后,全写少读解状态除变成读写可用状态
- 建议使用网络共享存储,避免机器故障、甚至完全坏掉导致数据丢失,进而需要大量时间恢复丢失数据
当 influxdb 实例无法承载当前数据量时,需要扩充新的 influxdb 实例,或者当前所有 influxdb 实例硬件资源严重过剩,需要缩减 influxdb 实例,则需要进行扩缩容操作:
- 为了高可用性、不停机,扩缩容时请一个 circle 接一个 circle 进行操作
- 修改 proxy.json,增删实例,配置为扩缩容后的目标配置,重新启动所有的 influx proxy
- 根据 接口 /rebalance 进行相关操作
- 指定的 circle 将变成 只写 (write only) 状态,可以继续写入数据、但不能查询,同时后台里进行重新平衡操作,从而不用停机,直到重新平衡完成后,只写状态解除变成读写可用状态
- 可以通过 接口 /transfer/stats 查询重新平衡进度统计信息
- 扩容完成后,建议清理迁移之前的旧数据,参考数据清理
- 备注:rebalance 操作是在一个 circle 内进行数据重新平衡,跟其它 circle 没有关系
-
备注:目前 rebalance 操作在面对海量量数据时,迁移性能较低,花费时间较长,建议以下方案:
-
方案一:使用
influx-tool transfer命令进行迁移,无须 influxdb 运行,具有很高的性能:2-4 GB/min(以实际环境为准)- 特性:influx-tool transfer 将直接读取 influxdb 实例的持久化文件进行迁移,并非基于 http 接口进行数据并行查询和写入,因此具有很高的性能
-
存在问题:要求 influxdb 必须停止运行,且迁移的 measurement 和 tags 不能包含特殊字符
,(逗号)、=(等号),否则会被丢弃;对于丢弃的 measurement,可以考虑性能较低的方案二
-
方案二:使用
influx-tool export命令导出数据,再使用influx-tool import或influx -import -path导入到 influx proxy- 存在问题:此方案通过扫描磁盘文件导出,再通过 http 接口导入,导入性能较低、但整体性能高于 rebalance 操作,适合少部分数据的情形
-
支持特性:influx-tool export 支持
--measurement和--regexp-measurement导出特定 measurement,选项可以设置多次
-
方案一:使用
当出现 influxdb 实例机器故障,甚至无法恢复的情形,需要对故障 circle 的进行数据恢复
- 确定故障 circle 中需要恢复的 influxdb 实例列表
- 修改 proxy.json,重新启动所有的 influx proxy
- 根据 接口 /recovery 进行相关操作
- 故障恢复过程中,待恢复的 circle 将变成 只写 (write only) 状态,可以继续写入数据、但不能查询,同时后台里进行故障恢复操作,从而不用停机,直到故障恢复完成后,只写状态解除变成读写可用状态
- 可以通过 接口 /transfer/stats 查询故障恢复进度统计信息
- 若使用网络共享存储,则不用做故障恢复,只需新 influxdb 实例启动后,等待缓存失败数据重写
- 备注:recovery 操作是将一个健康 circle 的数据恢复到一个故障 circle 中的部分或全部 influxdb 实例,是 circle 与 circle 之间的单向操作
-
备注:如果
hash_key为idx或exi,可以直接复制健康的 influxdb 实例的持久化数据文件目录到待恢复的故障机器,要求 circle 中 influxdb 实例的索引对应相等(需要停机) -
备注:也可以使用配套
influx-tool transfer工具进行迁移恢复
因为网络、磁盘等各种环境原因,可能会有极少概率出现各个 circle 数据不一致的情况、导致脏读问题,因此需要定期做数据同步,以达到数据一致性,实现方案是对所有 circle 的数据进行互相同步
- 确定开始同步的时间点(10位时间戳),将同步此时间点及之后的数据
- 根据 接口 /resync 进行相关操作
- 可以通过 接口 /transfer/stats 查询数据同步进度统计信息
- 备注:resync 操作是所有 circle 直接互相同步数据的操作
扩容后,少部分 influxdb 实例还存储着迁移之前的旧数据,由于这些旧数据不应该继续存储在该 influxdb 实例上,在确认无误后建议清理,避免占用内存资源
- 根据 接口 /cleanup 进行相关操作
- 可以通过 接口 /transfer/stats 查询数据清理进度统计信息
- 备注:cleanup 操作只针对指定 circle 进行错误数据清理
- 备注:被缩容移除的机器,在确认无误后直接删除数据文件或者回收即可,不适用 cleanup 操作
| 接口 | 描述 |
|---|---|
| /ping | 检查 influx proxy 实例的运行状态及版本信息 |
| /query | 查询数据并管理 measurement 数据 |
| /write | 写入数据到已存在的数据库中 |
| /api/v2/query | 使用 InfluxDB 2.0 API 和 Flux 在 InfluxDB 1.8.0+ 中查询数据 |
| /api/v2/write | 使用 InfluxDB 2.0 API 将数据写入 InfluxDB 1.8.0+ |
| /health | 查询所有 influxdb 实例的健康状态 |
| /replica | 查询 db,measurement 对应数据存储的所有 influxdb 实例副本 |
| /encrypt | 加密明文的用户和密码 |
| /decrypt | 解密加密的用户和密码 |
| /rebalance | 对指定的 circle 进行重新平衡 |
| /recovery | 将指定 circle 的全量数据恢复到故障的 circle 的全部或部分实例 |
| /resync | 所有 circle 互相同步数据 |
| /cleanup | 对指定的 circle 中不该存储在对应实例的错误数据进行清理 |
| /transfer/state | 查询和设置迁移状态标志 |
| /transfer/stats | 查询迁移进度状态统计 |
| /api/v1/prom/read | prometheus remote read 接口 |
| /api/v1/prom/write | prometheus remote write 接口 |
| /metrics | 查询 prometheus 格式的指标信息 |
| /debug/pprof | 生成用于性能瓶颈排障定位的采样文件 |
以下各节假定 influx proxy 实例在 127.0.0.1:7076 上运行,并且未启用 https
检查 influx proxy 实例的运行状态及版本信息
GET http://127.0.0.1:7076/ping
HEAD http://127.0.0.1:7076/ping
$ curl -i http://127.0.0.1:7076/ping
HTTP/1.1 204 No Content
X-Influxdb-Version: 2.5.12
Date: Mon, 24 Aug 2020 19:37:24 GMT查询数据并管理 measurement 数据
GET http://127.0.0.1:7076/query
POST http://127.0.0.1:7076/query
| 方法 | 查询类型 |
|---|---|
| GET | 用于所有以以下子句开头的查询:SELECT (不包括 SELECT INTO), SHOW
|
| POST | 用于所有以以下子句开头的查询:CREATE, DELETE, DROP
|
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| db=<database> | 必须 (对于依赖数据库的查询) | 设置数据库 |
| q=<query> | 必须 | InfluxQL 查询语句 |
| epoch=[ns,u,µ,ms,s,m,h] | 可选 | 指定返回时间戳的单位,默认为 RFC3339 格式 |
| pretty=true | 可选 | 以美化的 json 格式输出 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
查询 SELECT 语句
$ curl -G 'http://127.0.0.1:7076/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas"'
{"results":[{"statement_id":0,"series":[{"name":"mymeas","columns":["time","myfield","mytag1","mytag2"],"values":[["2017-03-01T00:16:18Z",33.1,null,null],["2017-03-01T00:17:18Z",12.4,"12","14"]]}]}]}创建数据库
$ curl -X POST 'http://127.0.0.1:7076/query' --data-urlencode 'q=CREATE DATABASE "mydb"'
{"results":[{"statement_id":0}]}查询 SELECT 语句、附带认证信息、返回以秒为单位的时间戳
$ curl -G 'http://127.0.0.1:7076/query?db=mydb&epoch=s&u=myuser&p=mypass' --data-urlencode 'q=SELECT * FROM "mymeas"'
{"results":[{"statement_id":0,"series":[{"name":"mymeas","columns":["time","myfield","mytag1","mytag2"],"values":[[1488327378,33.1,null,null],[1488327438,12.4,"12","14"]]}]}]}写入数据到已存在的数据库中
POST http://127.0.0.1:7076/write
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| db=<database> | 必须 | 设置数据库 |
| rp=<retention_policy_name> | 可选 | 设置写入数据的保留策略,未指定则写入 DEFAULT 的保留策略 |
| precision=[ns,u,ms,s,m,h] | 可选 | 设置写入数据时间戳的单位,默认为 ns |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
写一个点到数据库,时间戳以秒为单位
$ curl -i -X POST "http://127.0.0.1:7076/write?db=mydb&precision=s" --data-binary 'mymeas,mytag=1 myfield=90 1463683075'
HTTP/1.1 204 No Content
X-Influxdb-Version: 2.5.12
Date: Mon, 24 Aug 2020 19:54:33 GMT写一个点到数据库,附带认证信息
$ curl -X POST "http://127.0.0.1:7076/write?db=mydb&u=myuser&p=mypass" --data-binary 'mymeas,mytag=1 myfield=91'
HTTP/1.1 204 No Content
X-Influxdb-Version: 2.5.12
Date: Mon, 24 Aug 2020 19:54:57 GMT从文件写多个点到数据库
$ curl -i -XPOST "http://127.0.0.1:7076/write?db=mydb" --data-binary @data.txt
HTTP/1.1 204 No Content
X-Influxdb-Version: 2.5.12
Date: Mon, 24 Aug 2020 19:59:21 GMTdata.txt 示例数据如下,注意 data.txt 需要满足 Line protocol 语法
mymeas,mytag1=1 value=21 1463689680000000000
mymeas,mytag1=1 value=34 1463689690000000000
mymeas,mytag2=8 value=78 1463689700000000000
mymeas,mytag3=9 value=89 1463689710000000000
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
官方文档:Line protocol syntax
使用 InfluxDB 2.0 API 和 Flux 在 InfluxDB 1.8.0+ 中查询数据
$ curl -XPOST 'http://127.0.0.1:7076/api/v2/query' \
-H 'Accept:application/csv' \
-H 'Content-type:application/vnd.flux' \
-d 'from(bucket:"telegraf")
|> range(start:-5m)
|> filter(fn:(r) => r._measurement == "cpu")'使用 InfluxDB 2.0 API 将数据写入 InfluxDB 1.8.0+
$ curl -XPOST 'http://127.0.0.1:7076/api/v2/write?bucket=db/rp&precision=s' --data-binary 'mem,host=host1 used_percent=23.43234543 1556896326'查询所有 influxdb 实例的健康状态
GET http://127.0.0.1:7076/health
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| stats=false | 可选 | 返回更加详细的 stats 信息 |
| pretty=true | 可选 | 以美化的 json 格式输出 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
$ curl 'http://127.0.0.1:7076/health?stats=true&pretty=true'
{
"checks": [],
"circles": [
{
"circle": {
"id": 0,
"name": "circle-1",
"active": true,
"write_only": false
},
"backends": [
{
"name": "influxdb-1-1",
"url": "http://127.0.0.1:8086",
"active": true,
"backlog": false,
"rewriting": false,
"write_only": false,
"healthy": true,
"stats": {
"db1": {
"incorrect": 0,
"inplace": 2,
"measurements": 2
},
"db2": {
"incorrect": 0,
"inplace": 2,
"measurements": 2
}
}
}
]
},
...
],
"message": "ready for queries and writes",
"name": "influx-proxy",
"status": "pass",
"version": "2.5.12"
}circle:
- id:circle id
- name:circle 名称
- active:circle 的所有 influxdb 实例是否都存活,若为 false 即表示进入 全写少读 状态
- write_only:circle 是否为只写状态(至少有一个 influxdb 实例是只写状态)
backends:
- name:influxdb 实例名称
- url:influxdb 实例 url
- active:influxdb 实例是否存活
- backlog:influx-proxy 是否有 influxdb 实例堆积的缓存失败数据
- rewriting:influx-proxy 是否正在重写缓存失败数据到相应的 influxdb 实例
- write_only:influxdb 实例 是否为只写状态
- healthy:influxdb 实例的数据是否是健康的,即 stats 中所有的 incorrect 为 0 表示健康
-
stats:influxdb 实例的健康状态统计
-
db:influxdb 实例上的 db 名称
-
incorrect:db 中不应该存储到本 influxdb 实例的 measurement 的数量
- 导致原因:机器扩缩容、
hash_key发生变更、或hash_key对应键的值发生变更等 - incorrect 为 0 表示健康
- 导致原因:机器扩缩容、
-
inplace:db 中正确存储到本 influxdb 实例的 measurement 的数量
- inplace 和 measurements 相等表示健康
-
measurements:db 中 measurement 的数量
measurements = incorrect + inplace- 各个 influxdb 实例的 measurements 数量大致相当,表示数据存储负载均衡
-
incorrect:db 中不应该存储到本 influxdb 实例的 measurement 的数量
-
db:influxdb 实例上的 db 名称
查询 db,measurement 对应数据存储的所有 influxdb 实例副本
GET http://127.0.0.1:7076/replica
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| db=<database> | 必须 | 设置 database |
| mm=<measurement> | 必须 | 设置 measurement (meas 仍然有效) |
| pretty=true | 可选 | 以美化的 json 格式输出 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
$ curl 'http://127.0.0.1:7076/replica?db=db1&mm=cpu1&pretty=true'
[
{
"backend": {
"name": "influxdb-1-2",
"url": "http://127.0.0.1:8087"
},
"circle": {
"id": 0,
"name": "circle-1"
}
},
{
"backend": {
"name": "influxdb-2-2",
"url": "http://127.0.0.1:8089"
},
"circle": {
"id": 1,
"name": "circle-2"
}
}
]加密明文的用户和密码
GET http://127.0.0.1:7076/encrypt
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| text=<text> | 必须 | 需要加密的明文文字 |
$ curl -G 'http://127.0.0.1:7076/encrypt' --data-urlencode 'text=admin'
YgvEyuPZlDYAH8sGDkC!Ag解密加密的用户和密码
GET http://127.0.0.1:7076/decrypt
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| key=<key> | 必须 | 用于加解密的密钥,默认是 consistentcipher |
| text=<text> | 必须 | 需要解密的加密文字 |
$ curl 'http://127.0.0.1:7076/decrypt?key=consistentcipher&text=YgvEyuPZlDYAH8sGDkC!Ag'
admin对指定的 circle 进行重新平衡
POST http://127.0.0.1:7076/rebalance
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| circle_id=0 | 必须 | circle 的 id,从索引 0 开始 |
| operation=<operation> | 必须 | 操作类型,可选值为 add 或 rm |
| dbs=<dbs> | 可选 | 数据库列表,以英文逗号 ',' 分隔,为空时将默认为全部数据库 |
| worker=5 | 可选 | 迁移数据时的最大并发线程数,默认为 5 |
| batch=20000 | 可选 | 迁移数据时查询一个批次的点数,默认为 20000 |
| since=<since> | 可选 | 迁移从 <since> 时间点开始(10位时间戳,包含该点)的数据,默认为 0,表示所有数据 |
| ha_addrs=<ha_addrs> | 必须 (若至少有两个正在运行的 influx proxy 实例时) | 所有正在运行的 influx proxy 实例的高可用地址列表 (host1:port1,host2:port2...),以英文逗号 ',' 分隔,单实例时此参数将被忽略 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
当操作类型 operation 为 rm 时,必须添加被移除的 influxdb 实例的配置信息,以 json 格式放入到请求 body 中
{
"backends": [
{
"name": "influxdb-1-2",
"url": "http://127.0.0.1:8087",
"username": "",
"password": "",
"auth_encrypt": false
}
]
}
在 circle 0 扩容 influxdb 实例后(即在 proxy.json 文件配置了新实例,influx proxy 重启将读取到新的实例列表),进行重新平衡操作
$ curl -X POST 'http://127.0.0.1:7076/rebalance?circle_id=0&operation=add'
accepted如果部署了 influx proxy 高可用,运行了多个 influx proxy 实例,则需要在 circle 0 扩容 influxdb 实例后,指定 ha_addrs 参数,再进行重新平衡操作
$ curl -X POST 'http://127.0.0.1:7076/rebalance?circle_id=0&operation=add&ha_addrs=127.0.0.1:7076,127.0.0.1:7077'
accepted在 circle 0 移除 url 为 http://127.0.0.1:8087 的 influxdb 实例后,进行重新平衡操作,设定使用 2 个 cpu 进行数据迁移,这里假定只有一个在运行的 influx proxy 实例
$ curl -X POST 'http://127.0.0.1:7076/rebalance?circle_id=0&operation=rm&worker=10' -H 'Content-Type: application/json' -d \
'{
"backends": [
{
"name": "influxdb-1-2",
"url": "http://127.0.0.1:8087",
"username": "",
"password": "",
"auth_encrypt": false
}
]
}'
accepted将指定 circle 的全量数据恢复到故障的 circle 的全部或部分实例
POST http://127.0.0.1:7076/recovery
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| from_circle_id=0 | 必须 | 来源 circle 的 id,从索引 0 开始 |
| to_circle_id=1 | 必须 | 待恢复 circle 的 id,从索引 0 开始 |
| backend_urls=<backend_urls> | 可选 | 待恢复的 influxdb 实例 url 列表,以英文逗号 ',' 分隔,为空时将默认为待恢复 circle 的全部 influxdb 实例 url 列表 |
| dbs=<dbs> | 可选 | 数据库列表,以英文逗号 ',' 分隔,为空时将默认为全部数据库 |
| worker=5 | 可选 | 迁移数据时的最大并发线程数,默认为 5 |
| batch=20000 | 可选 | 迁移数据时查询一个批次的点数,默认为 20000 |
| since=<since> | 可选 | 迁移从 <since> 时间点开始(10位时间戳,包含该点)的数据,默认为 0,表示所有数据 |
| ha_addrs=<ha_addrs> | 必须 (若至少有两个正在运行的 influx proxy 实例时) | 所有正在运行的 influx proxy 实例的高可用地址列表 (host1:port1,host2:port2...),以英文逗号 ',' 分隔,单实例时此参数将被忽略 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
从 circle 0 恢复所有数据到 circle 1
$ curl -X POST 'http://127.0.0.1:7076/recovery?from_circle_id=0&to_circle_id=1'
accepted从 circle 0 恢复数据到 circle 1 中 url 为 http://127.0.0.1:8089 的实例
$ curl -X POST 'http://127.0.0.1:7076/recovery?from_circle_id=0&to_circle_id=1&backend_urls=http://127.0.0.1:8089'
accepted所有 circle 互相同步数据
POST http://127.0.0.1:7076/resync
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| dbs=<dbs> | 可选 | 数据库列表,以英文逗号 ',' 分隔,为空时将默认为全部数据库 |
| worker=5 | 可选 | 迁移数据时的最大并发线程数,默认为 5 |
| batch=20000 | 可选 | 迁移数据时查询一个批次的点数,默认为 20000 |
| since=<since> | 可选 | 迁移从 <since> 时间点开始(10位时间戳,包含该点)的数据,默认为 0,表示所有数据 (tick 仍然有效) |
| ha_addrs=<ha_addrs> | 必须 (若至少有两个正在运行的 influx proxy 实例时) | 所有正在运行的 influx proxy 实例的高可用地址列表 (host1:port1,host2:port2...),以英文逗号 ',' 分隔,单实例时此参数将被忽略 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
$ curl -X POST 'http://127.0.0.1:7076/resync?worker=10'
accepted对指定的 circle 中不该存储在对应实例的错误数据进行清理
POST http://127.0.0.1:7076/cleanup
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| circle_id=0 | 必须 | circle 的 id,从索引 0 开始 |
| worker=5 | 可选 | 迁移数据时的最大并发线程数,默认为 5 |
| ha_addrs=<ha_addrs> | 必须 (若至少有两个正在运行的 influx proxy 实例时) | 所有正在运行的 influx proxy 实例的高可用地址列表 (host1:port1,host2:port2...),以英文逗号 ',' 分隔,单实例时此参数将被忽略 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
$ curl -X POST 'http://127.0.0.1:7076/cleanup?circle_id=0&worker=10'
accepted查询和设置迁移状态标志
GET http://127.0.0.1:7076/transfer/state
POST http://127.0.0.1:7076/transfer/state
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| resyncing=true | 可选 | 设置 influx proxy 是否正在互相同步数据的状态 |
| circle_id=0 | 可选 | 设置 circle 是否正在迁移数据的状态的 circle id,从索引 0 开始 |
| transferring=false | 可选 | 设置指定 circle 是否正在迁移的状态 |
| pretty=true | 可选 | 以美化的 json 格式输出 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
查询迁移状态标志
$ curl 'http://127.0.0.1:7076/transfer/state?pretty=true'
{
"circles": [
{
"id": 0,
"name": "circle-1",
"transferring": false
},
{
"id": 1,
"name": "circle-2",
"transferring": false
}
],
"resyncing": false
}设置 influx proxy 正在互相同步数据
$ curl -X POST 'http://127.0.0.1:7076/transfer/state?resyncing=true&pretty=true'
{
"resyncing": true
}设置 circle 0 正在迁移数据
$ curl -X POST 'http://127.0.0.1:7076/transfer/state?circle_id=0&transferring=true&pretty=true'
{
"circle": {
"id": 0,
"name": "circle-1",
"transferring": true
}
}查询迁移进度统计信息
GET http://127.0.0.1:7076/transfer/stats
| 查询参数 | 可选/必须 | 描述 |
|---|---|---|
| circle_id=0 | 必须 | circle 的 id,从索引 0 开始 |
| type=<type> | 必须 | 状态统计类型,可选值为 rebalance、recovery、resync 或 cleanup |
| pretty=true | 可选 | 以美化的 json 格式输出 |
| u=<username> | 可选 (若未启用认证) | 设置认证用户,若启用认证 |
| p=<password> | 可选 (若未启用认证) | 设置认证密码,若启用认证 |
$ curl 'http://127.0.0.1:7076/transfer/stats?circle_id=0&type=rebalance&pretty=true'
{
"http://127.0.0.1:8086": {
"database_total": 0,
"database_done": 0,
"measurement_total": 0,
"measurement_done": 0,
"transfer_count": 0,
"inplace_count": 0
},
"http://127.0.0.1:8087": {
"database_total": 0,
"database_done": 0,
"measurement_total": 0,
"measurement_done": 0,
"transfer_count": 0,
"inplace_count": 0
}
}prometheus remote read 接口
prometheus remote write 接口
查询 prometheus 格式的指标信息
生成用于性能瓶颈排障定位的采样文件
curl http://127.0.0.1:7076/debug/pprof/
下载 CPU 性能的采样文件
curl -o <path/to/pprof-cpu> http://127.0.0.1:7076/debug/pprof/profile下载 Heap 内存的采样文件
curl -o <path/to/pprof-heap> http://127.0.0.1:7076/debug/pprof/heap| 项目 | Stars | 描述 | 评价 |
|---|---|---|---|
| chengshiwen/influxdb-cluster |  |
Open Source Alternative to InfluxDB Enterprise | 几乎与 InfluxDB Enterprise 一模一样,基于最新 InfluxDB 1.8.10,高质量且精简的代码、显著很少的 bugs,易于维护并保持与 InfluxDB 上游代码同步升级,生产环境已就绪 |
| influxdata/influxdb-relay |  |
Service to replicate InfluxDB data for high availability | 官方出品,已长期不维护,缺少很多功能,例如不支持数据分片(见注 1) |
| shell909090/influx-proxy |  |
High availability proxy layer to InfluxDB by InfluxData | 饿了么出品,受 influxdb-relay 启发,已长期不维护,缺少一些功能(见注 1) |
| chengshiwen/influx-proxy |  |
InfluxDB Proxy with High Availability and Consistent Hash | Forked 于 shell909090/influx-proxy,支持更多功能,具有高可用性、一致性哈希(见注 1),生产环境已就绪 |
| freetsdb/freetsdb |  |
Open-Source replacement for InfluxDB Enterprise | 低质量且复杂的代码(见注 2),bugs 众多,基于 InfluxDB 1.7.4,只实现了 InfluxDB Cluster 特性的 10%,难以维护,无法保持与 InfluxDB 上游代码同步升级,生产环境尚未就绪 |
| spring-avengers/influx-proxy |  |
A proxy for InfluxDB like codis | 已长期不维护,很多功能缺失,生产环境尚未就绪 |
| derek0377/influxdb-cluster |  |
InfluxDB cluster proxy like codis | 已长期不维护,很多功能缺失,生产环境尚未就绪 |
| jasonjoo2010/chronus |  |
InfluxDB cluster based on version 1.8.3 | 程序设计和行为不同于 InfluxDB Enterprise,很多功能缺失,生产环境尚未就绪 |
注 1: shell909090/influx-proxy/issues/111
注 2: freetsdb/freetsdb/issues/7, freetsdb/freetsdb/issues/8, freetsdb/freetsdb/issues/9
- Email: [email protected]
- GitHub Issues
-
Slack: 加入 Slack 并在
#influx-proxy频道中交流 -
钉钉群:
41579095 -
微信群: 直接扫码进入微信群,或者添加助手(微信号
shiwen-asst)、助手将添加您到微信群
