KDD Knowledge Discovery in Databases
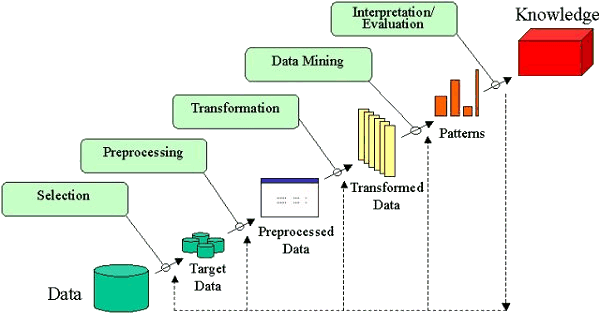
- Developing an understanding of
- the application domain
- the relevant prior knowledge
- the goals of the end-user
- Creating a target data set: selecting a data set, or focusing on a subset of variables, or data samples, on which discovery is to be performed.
- Data cleaning and preprocessing.
- Removal of noise or outliers.
- Collecting necessary information to model or account for noise.
- Strategies for handling missing data fields.
- Accounting for time sequence information and known changes.
- Data reduction and projection.
- Finding useful features to represent the data depending on the goal of the task.
- Using dimensionality reduction or transformation methods to reduce the effective number of variables under consideration or to find invariant representations for the data.
- Choosing the data mining task.
- Deciding whether the goal of the KDD process is classification, regression, clustering, etc.
- Choosing the data mining algorithm(s).
- Selecting method(s) to be used for searching for patterns in the data.
- Deciding which models and parameters may be appropriate.
- Matching a particular data mining method with the overall criteria of the KDD process.
- Data mining.
- Searching for patterns of interest in a particular representational form or a set of such representations as classification rules or trees, regression, clustering, and so forth.
- Interpreting mined patterns.
- Consolidating discovered knowledge.