為什麼社會有分歧
http://evshary.com/2024/10/27/%E7%82%BA%E4%BB%80%E9%BA%BC%E7%A4%BE%E6%9C%83%E6%9C%89%E5%88%86%E6%AD%A7/
2024-10-27T17:27:17.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
在現代社會中,人們常常都在說社會分裂越來越嚴重。由於網路的發展,各種意見容易匯聚,然後又因為社群媒體的演算法不斷擴大同溫層,讓某些意見持續放大,最終產生出衝突。常見的例子像是國家定位、同性婚姻、核電使用,而在國外更有持槍議題、移民、人種平權等等。在社會中,某些議題上有立場衝突必定是會存在的。社會是由人組成的,人人也都有不同意見。當大家對某個方向都贊同,那社會肯定是會朝這個方向前進,這時就沒有太多討論價值。會吸引人們目光的總是那些有不同意見的議題,透過激烈討論,直到達成某種程度的共識後才會逐漸潛伏,被其他更引人注目的議題所取代。這就如同大海上有很多波浪,當最大的波浪消失了,大家的注意力就會集中在次高的波浪上一樣。
隨著時代的推進,人們的價值觀也不斷更新,過去認為正確的概念在現代可能也會被推翻。其中最著名的就是種族不平等。以美國為例,奴隸制度直到內戰才被廢除,但是一直要到二戰後才真正落實廢除種族隔離。而現在很多社會運動者更加追求在各個領域,各種人種都要能一定程度的參與,例如大學入學或是公司聘用。
然而這類社會進步價值的推進,也一定會帶來反作用力。追求進步價值的人 (SJW),常常會被其他相對比較保守的人嘲笑為「覺青」、「左膠」。這個非常正常,任何對社會現狀的改動都會有阻力。一開始可能因為某些事件爆發(如 Black Lives Matter、Me too),改革的動力非常強大,不斷在某個議題上面往前推進,社會也願意支持。但隨著時間推移,改革者的要求越來越多,社會大眾也會逐漸對議題失去興趣,其中的保守派也會開始抗拒,最終反而形成另一股強烈的反對力量把改革派反推回去。這就像是鐘擺一樣,在議題中的兩個立場不斷擺盪,直到形成社會可以接受的新共識。
這樣的現象其實我們可以在很多例子上看見。以前陣子台灣的同婚議題來看,同志對同性婚姻的訴求得到年輕人的認可,產生出改革力量,推動公投。然而社會雖然對同性戀愛的接受度越來越大,卻還是無法忍受改變傳統上對婚姻的定義,最終在公投上否決了這項改變。不過從結果上來說,儘管同性婚姻沒成功,但是社會也接受了新的同性伴侶相關法律。就像是改革派往前兩步,保守派往後推一步,最終還是前進一步,社會達成了新的共識。
同樣的狀況也發生在全球化上面,過去幾十年由於全球化,人們可以享受發展中國家製造的便宜商品,但卻也造成了先進國家的製造業外流。美國的藍領階層在 2016 年的大選反撲中選出了川普,透過拉高關稅而造成逆全球化。現在再加上地緣政治和疫情的原因,逆全球化的趨勢短時間內應該是不會緩解,但可預期的是也不會回到大家完全閉關鎖國的格局。整體態勢應該最終還是在一個新的共識點達成平衡,直到下一股外在力量再次引發改變。
回到我們個人,我們所參與的團體,例如公司、社團等等,其實也是一種小社會。當遇到外在壓力下,通常也會產生出改革和保守兩股力量。舉例來說,公司營收不好需要進行轉型、社團老化需要吸引新血加入。改革派會認為不變動就是等死,保守派則是擔心太大的變動會失去了團體本身的價值,導致團體的崩解。兩種力量在內部不斷拉扯,直到找出新的平衡出來。
雖然我們這裡使用改革和保守兩種詞,但這並沒有任何的褒義和貶義。改革並不代表有完美結局,看看多少國家在革命後陷入貧窮崩壞。保守而轉型太慢也常常是公司被新的挑戰者所取代的原因。改革沒有保守的制約往往會衝太快,讓系統不穩定而崩潰,反過來說,保守也需要有改革派的驅動來應對新的挑戰。有智慧的領導人必須要在這兩種勢力中小心翼翼維持平衡,走出緩慢並有力的改變力量。
我們人類總是喜歡有共識沒分歧,但是分歧在一個正常的社會中是一定存在的,因為人與人彼此間就是不一樣。分歧從來不是壞事,這是社會多樣性的一種展現。當我們可以用比較自然態度看待他人意見不同時,社會也越不會二極化、彼此相互對立。因為我們知道不同立場都有存在的必要,唯一需要的是一套穩定合理產生出彼此都能接受共識的方法。這個方法可能是公投、可能是選舉,只要人們可以接受即可。當分歧可以用這套系統來彌合,社會就不會因此而產生分裂,進而朝有共識的方向往前邁進。
]]>
@@ -46,7 +71,7 @@
http://evshary.com/2024/10/20/%E7%B4%8D%E7%93%A6%E7%88%BE%E5%AF%B6%E5%85%B8/
2024-10-20T21:37:31.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
這本書在說什麼 & 適合的人「納瓦爾寶典」是 Eric 整理 Naval Ravikant 過去 X 上的推文、部落格和 podcast 上的想法所集結而成,前一版的名字叫做「快樂實現自主富有」。Naval 是一位知名的矽谷天使投資人,創辦了 AngelList。這本書的內容主要是 Naval 對於人生的各種看法,包括金錢、創業、努力、快樂等等。
想要瞭解矽谷創業家是如何思考、他們的人生價值觀是什麼,非常推薦閱讀這本書。他有很多思考方式很有啟發性,常常會讓我覺得耳目一新,沒想到還可以這樣看待事情。一本書如果可以在某個角度開啟不同視野就非常有價值了,更別說它在人生的各個面向都有獨特的見解。
我畫線的地方
下面提供一些對我有所感觸的句子:
人生並不是競爭的過程,而是找出自己的天命。沒有任何人可以在成為自己上面贏過你。
No one can compete with you on being you.Most of life is a search for who and what needs you the most.
不要靠時間、勞力賺錢,要靠判斷賺錢。沒有機器或是 AI 可以取代你的判斷。
I want a robot, capital, or computer to do the work, but I want to be paid for my judgment.
如果我不再想著要為了未來而忍受當下,那就沒有退休的概念了。如果我所作的事情是自己生命中的天命,那怎麼還有退休這回事呢?
Retirement is when you stop sacrificing today for an imaginary tomorrow. When today is complete, in and of itself, you’re retired.
環境會塑造一個人,但是如果我們夠聰明的話,就會去選擇可以讓自己變更好的環境。
The current environment programs the brain, but the clever brain can choose its upcoming environment.
如果我們不想要徹徹底底變成某個人,那就沒有必要去忌妒。專注在讓自己身上,他人的經歷成就最多只能提供參考而已。
Do you want to actually be that person with all of their reactions, their desires, their family, their happiness level, their outlook on life, their self-image? If you’re not willing to do a wholesale, 24/7, 100 percent swap with who that person is, then there is no point in being jealous.
個人想法
我認為 Naval 都是用整體系統的方式來看待事情。他不會用我們一般很直覺的方式來思考,而是從社會的角度來看每個人所扮演的角色。正因為如此,他才能創造出不同常人的事業。書中很多地方都給我不一樣的觀點,不過整體來說,可以整理成如下四個點。
金錢與財富
一般我們都認為金錢就是財富,但是 Naval 強調兩者的不同。金錢不過是社會為了感謝你的貢獻所提供給你的借據,你可以用這個來換取其他商品,但是借據本身是無法創造價值的。然而財富不一樣,它在你睡覺的時候仍然可以不斷創造價值,不斷增值,例如房地產、工廠、程式等等投資。對我們而言,正確看待金錢才能善用金錢。金錢本身只是一種資源,單純放著沒有任何效益,唯有當它開始流動的時候才會產生出價值。
Naval 提到了三種槓桿:人力槓桿,靠雇用員工來放大產值,但是你需要去負擔管理成本。金錢槓桿,如很多現在的財富管理人或是投資者,他們玩的是一種金錢遊戲,看怎麼用錢滾錢。而最簡單的槓桿則是利用新型態的槓桿,例如程式、自媒體、書籍等等,它們的複製成本極低,一旦成功,就可以快速放大獲得利潤。有趣的是,很多自媒體在介紹本書的時候都會特別強調這句話,也許是因為剛好符合他們目前所作的事情的關係。我個人認為三種槓桿並沒有優劣之分,一個公司最終也是三種槓桿都會用到,就算是自媒體,到一定的規模也還是與需要有員工協助才行。重點是我們可以把這三種槓桿放在心中,在必要的時候選擇需要的來使用。
競爭與努力
這部分是我最喜歡的地方,因為常常都和他人比較,想要比別人好。但 Naval 提醒我們,沒有必要去嫉妒羨慕他人,畢竟我們也不願意徹底成為某個人。當羨慕某個人在某方面表現優異的時候,可以想想自己願不願意付出他所付出的代價,例如放棄與親朋好友相處的時間或是對員工很刻薄等等。另外一方面來說,競爭和比較代表自己和別人在做同樣的事情,社會也可以輕易找出其他人來替代自己。就某種程度來說社會也希望如此,因為越容易被替代,就越不需要付出高昂的代價。然而換個角度來說,若是自己發展出獨特不可取代的價值,剛好社會也需要這個價值,社會就會願意提供非常豐厚的報酬。至於怎麼找出自己不可取代的價值呢?Naval 建議可以找看看什麼東西是別人覺得無聊,但是你很有興趣的。人生其實就是一個不斷尋找什麼最需要自己的過程。
和他人的關係最好是正合關係,也就是利益相同,往同個方向前進。有些遊戲是零和遊戲,例如地位的競爭,某個職位只有一個,大家只能把別人擠下去來得到該位置。在這個情況下,所有參與者的努力是彼此抵消,無法共同創造價值。這給我的啟發是要避開競爭的遊戲,並且參與合作的遊戲。在一個系統中大家的方向都不同樣時,只是互相拉扯,而利益一致的時候,方向就會相同,所有的努力都會推動前進,產生的價值也是巨大的。
談到努力,我們從小到大都被灌輸努力很重要。有志者事竟成、一分耕耘一分收穫。努力絕對很重要,但是更常被忽略的是努力的方向。我們很常只關注付出多少努力,反而忽略了要選擇做什麼以及和誰一起做,很多時候後者影響更為巨大。因此保留時間思考很重要。以工作時間衡量一個人的價值已經是工業時代的事情了,現在的社會中如何判斷的價值更高。Naval 舉個很鮮明的例子,股東們從來不在乎巴菲特或是馬斯克一週工作多久,股東會說:「做你們自己就好」,因為這樣他們才能創造出最大的價值。這也讓我反思自己是不是也都只是用付出多少時間努力來當衡量標準,努力只是手段而已,重要的是到底能打造出什麼成果。
從人生的角度來看,一生中 99% 的努力都會被浪費掉,例如求學階段學的知識在考完試之後,大部分都還給老師了。可能最終我們會發現自己生命中的志願只用到 1% 的過去知識而已,就如同我們花很多時間約會找對象,最終也只為了找到適合的丈夫和妻子,中間的努力與最終成果沒有直接關係。我們不可能一開始就知道那 1% 是什麼,但是一旦發現自己找到了,就要勇於放棄其他 99% 並全心投入其中。
在現代社會中,各種技術和機會不斷湧現,從網路、手機到 AI,社會形態的迭代速度越來越快。不需要擔心自己會錯過時代的機會,因為機會只會越來越多。就如同 Naval 所說,如果對某個機會會猶豫,那可能就不是適合自己的,我們完全不用擔心找不到其他機會。找出真正適合自己的方向並專注投入其中,而非人云亦云跟著人群大眾去競爭。尋找與探索遠遠重要於努力競爭。
閱讀和學習
Naval 提到他很喜歡閱讀,所以對於閱讀也有自己的一套想法。他並沒有被被閱讀本身所拘束,而是享受閱讀本身,所以認為閱讀的書本數量只是個空虛指標。很多時候書並不需要全部讀完,因為作者只是為了描述某個論點而不斷論述,舉了各式各樣的例子來讓理論完整且有說服力。一旦你認為已經了解核心概念了,應該就可以放下手上的書轉而去讀其他的書,沒必要完整看完。我們的社會很鼓勵閱讀,但也因此讓閱讀變得過度形式化,應該要回歸閱讀真正的本質,而不被看完一本書的形式所拘束。
那可以看些什麼書呢?Naval 的論點挺有意思的,他覺得如果只是去讀大家都看的書,那你的想法只會跟別人一模一樣,沒有太多不同。對我而言排行榜的書和他人推薦的書其實也是一種過濾機制,可以幫助我們找出值得一讀的書籍。不過他的提醒也讓我意識到要有能創造自己獨立想法的養份,有意識讓自己的書單與他人不同增加差異化。Naval 也有提到可以多讀第一手的書籍,例如談到看不見的手,可以去看看亞當斯密的『國富論』、談到演化論可以去看看達爾文的『物種原始』。我們可以更直接的接觸該作者的思考方式,而不間接透過他人轉述。至於一些關於人生恆久不變的古老問題,例如生命的本質這種,更可以透過時間來選書。經過時間的洗禮,會流傳到現代還有價值的書籍一定程度上能幫助我們解決問題。
雖然本書很多內容是從 Naval 的 X 推文整理而成,但他卻否定了收集格言的價值。格言很酷,但是我們欠缺相關的經驗和背後的思維模型的話,它並無法幫助我們思考解決問題,只會隨時間過去而遺忘。我想這個也就是為何本書會出現的原因,透過完整且有系統的論述,讓我們才能真正了解 Naval 的思考方式,這個比起格言才是更珍貴的寶藏。
對於 Naval 而言,除了閱讀,還有一些技能也是非常重要的。首先是各個學科的基礎知識,因為複雜的理論都是從基礎而來,這個也就是 Charlie Munger 的所謂「思維模型」。再來就是流暢的表達能力,比起高深的文學用詞,更重要的是怎麼用簡單的語言來清楚表達自己。合作是人類社會成立的基石,而要能夠合作就需要彼此能夠有效溝通,甚至是說服他人。最後就是邏輯能力,這點其實我也很有感,有時候我們會遇到非常複雜的問題不知道從何下手,這時候有清晰的邏輯能力就能夠有效分析問題。在我工作的經驗中,能力好的同事都有把複雜問題簡單化的能力,用最基本的邏輯來分析並且一一排除問題。以上這些能力都值得我們重視。
價值觀
一如其他人的看法,Naval 強調了健康的重要性,不管是事業、金錢、家庭,沒有健康就無法照顧到其他面向。他有提到一個有趣的論點,健康、金錢和時間這三者在人生不同階段都無法同時擁有。年輕的時候,沒錢但有時間和健康、中年時沒時間但有錢和健康、老年的時候則是有錢有閒,但沒健康。無論如何,健康對於我們人生都是要不斷去關注的課題。或許有時候我們會說沒時間關照健康,但是 Naval 說「沒有時間」意味著「這不是我的優先權」。仔細思考一下,確實也是這樣,不去做某件事,就是因為認為其他事情更重要。當別人問健康是不是比其他事情還重要時,我會說是,但是當問有沒有時間去照顧健康時卻說沒有時間,這似乎是一件很衝突的事情。因此當問到有沒有時間時,應該要換個思考方式,這個是不是我的優先權,是的話就要把其他優先度較低的事情排開。
Naval 提到了他有三個核心價值觀。第一個是誠實,這裡的誠實最主要是對自己誠實,不需要為了他人眼光去偽裝自己。他提到勇氣是能夠不管他人目光做自己,一旦認為某個聚會只是浪費時間,他甚至會直接中途離席。我常常認為以和為貴,所以會一定程度壓抑自己配合他人,但是這也造成需要花費精力在非目標的事情上,讓自己很不開心。第二個是不要短期思考,不管是金錢、人際關係、健康都需要長期堅持才能有複利效應,不要因為短期的快樂而造成長期的痛苦。最後則是平等待人,與他人相處沒有上下之分,我不高人一等,但也不落於人下,只有維持平等才能確保關係的長久。這非常困難,特別是我們為他人工作的時候,自己因為是下屬,自然而然就會以老闆意見為上,隱藏自己的想法。然而工作也不過是個交易關係,並不應該因此失去自我。Naval 很敢於做自己,和我的個性差異很大,雖然不可能和他一樣,但是是個可以讓我可以學習調整自己的模範。
小結
總結來說,Naval 分享了他在人生方方面面的各種想法,儘管很多部分很有道理,但有些要落實在行動也不容易。舉個例子,他說如果認為自己的時間多高價值,低於該價值的事情就應該要外包,然而他也承認自己很多時候也做不到。我會覺得重點在於看看別人不一樣的價值觀,找出適合的部分並融入自己的人生中。不需要完全學他,但是可以藉此調整看待事情的方式。
看完整本書可以發現 Naval 很強調自我。做自己不要跟別人競爭、跟隨自己的興趣閱讀、誠實對待自己不要偽裝。我想對我而言,這本書的最大收穫就是尊重自己與他人的不同,就算活得很自我,一樣可以獲得充份的財富和快樂。
反思與行動
如同書中最後所提: “Inspiration is perishable - act on it immediately”。下面是看完書後我希望為自己帶來不一樣改變的地方。
- 當發現自己在用努力與別人競爭的時候,思考一下我有沒有在做自己。在做自己上是不需要跟別人競爭的。
- 當自己無法決定某個選擇時,就先不要接受該選項。因為現代社會不缺機會,好的選擇不會讓自己猶豫。
- 與他人共贏,人與人是平等關係,並不是上和下。當有共同利益且能為彼此帶來價值時,這樣的合作就更加容易成功。
]]>
@@ -73,7 +98,7 @@
http://evshary.com/2024/10/06/%E7%82%BA%E4%BB%80%E9%BA%BC%E5%81%89%E5%A4%A7%E4%B8%8D%E8%83%BD%E8%A2%AB%E8%A8%88%E7%95%AB/
2024-10-06T23:35:11.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
這本書在說什麼 & 適合的人「為什麼偉大不能被計劃」是由兩位作者 Kenneth Stanley 和 Joel Lehman 所著。他們是機器學習和人工智慧研究學者,其團隊做了一個圖片孵化網站,意外發現要從亂數中產生出好的圖片並不能透過事先的計劃,而是只能透過不斷嘗試,發掘夠新奇有趣的圖片,然後以此為踏腳石繼續往下探索。這樣的發現也可以套用到其他人類偉大的發現和發明之中。這些偉大的成就,大多都不是透過設定目標和安排計畫來達成,反而都是因為在興趣探索時意外發現。
在現代社會中,人生也都有既定的目標,讀書升學、找個好工作、結婚買房、賺到可以退休的錢。有時候也會不禁想到按照這樣目標走,好像缺乏了什麼,無法創造不一樣的可能性。若是對這樣的人生有所疑惑的話,卻又沒有個方向的話,這本書可以很好地釐清並啟發自己不同的想法。
我畫線的地方
書中有些讓我特別有感觸的地方:
越是遠大的目標,越是不可能透過計畫來達成。能夠透過努力和計畫達成的目標根本稱不上偉大,因為每個人都可以透過同樣的方式達成。
若⽬標設置⾜夠適度,它就會起到積極作⽤;反之,⽬標越「⾼⼤上」,情況就越複雜…關鍵在於,通向「⾼⼤上」⽬標的踏腳⽯,往往⾮常奇怪。也就是說,若你只是悶頭盯著⾃⼰的⽬標,那它們可能就是你根本意想不到的東西。
新奇比起固定方向的目標更為可靠,因為沒有人踩過,更有可能有別人所沒注意到的發現,雖然我們並不知道是什麼。
設定⽬標意味著遵循⼀條未知的路徑,朝著遙遠的⽬的地前⾏,⽽新奇性只要求我們遠離已經到過的地⽅。離開⼀個已經到過的地⽅,不僅更簡單輕鬆,還蘊含了更豐富的信息…相信新奇性是推動進步的⼀台有意義的引擎。
我們的教育讓大家少了目標就沒有方向了,這時或許順應興趣、本心直覺去走,會是一個更靠譜的方式。
如果你想知道如何擺脫對⽬標的盲⽬信奉,只需要隨⼼⾏事、遵循個⼈興趣的指引即可。不是所有的事情都需要以嚴謹的⽬標為指導。如果你對某件事有強烈的直覺,不妨順應本⼼。如果你沒有明確的⽬標,那也沒必要患得患失,因為不論你最終⾛到哪⾥,結果都不會太壞。
一直以來我們都有所誤會,物競天擇的重點不在於競爭,而是避開競爭。避開競爭才能夠有更大的生存空間。
⾃然進化並不是通過競爭來獲得⽣物多樣性,⽽是通過避免競爭。特別是某⼀⽣物如果能以⼀種新⽅式謀得⽣存,那便是成功找到了⾃⼰的專屬⽣態位。因為它會成為第⼀個以這種新⽅式⽣存的⽣物,所以作為此道開⼭者,競爭不會太激烈,繁衍也會更容易。
過於專注在支微末節的競爭沒有太大意義,重點是這個是不是能夠帶來全新領域的踏腳石。想想自己是不是也常在不重要的地方跟別人競爭那細微的差異呢?
通過細枝末節的調整,擠出最後⼀絲性能提升空間的做法,並不會帶來令⼈振奮的洞見…所有被歷史記住的算法,必然是為未來的開拓者奠定基礎的算法。它們將推動新算法的誕⽣,甚⾄幫助我們開闢全新的領域。到那時,誰還會在乎這些新算法在剛開始出現時,與「⽼靠譜」算法⽐較時的表現如何呢?
個人想法
從小我就很相信目標論。相信任何事物都可以透過設定目標並且執行詳實的計畫來完成。越是想達成偉大的成就就更應該設定遠大的目標、加倍的努力、以及嚴謹的紀律。然而這本書卻打破了想像,提供了完全不一樣的視角。下面三點是我從中獲得的最大收穫。
偉大目標無法被設定
作者的圖片孵化器網站讓人們能夠協作從最基本的圖形,過程不斷產生些微隨機變異,最終產生出各種有趣的圖片。然而,人們卻無法透過事先設定想要產生某種圖案來達成,只能在產生圖片的過程中挑選比較新奇的圖片並且持續嘗試。舉例來說,就像是下圖,我們沒辦法透過事先設定好要創作汽車來產生期待的結果,反而意外是從外星人的圖片演化而來。當初的創作者從來也不會想過外星人的眼睛可以轉換成汽車的輪子。

圖片取自 Kenneth Stanley 的演講
這樣的現象其實在其他研究中也有同樣發現,就像是走迷宮,如果只是設定要往最接近出口的方向前進,很可能會卡在死胡同出不來。然而如果我們不要設定目標,讓探索更隨意,單純去嘗試過去沒試過的路線,反而更有機會走出迷宮。讓機器人學習走路的過程中,設定目標要它不要跌倒反而學不會走路,因為飛踢是往前邁步的開端。這些目標的設定反而成了目標的阻礙。
在人類偉大的發現發明中,因為繞路反而達成目標的情況並不罕見。例如,當初發明真空管並不知道可以用來製作電腦;而人類想要飛行不是像鳥一樣使用翅膀,而是發明內燃機,有趣的是內燃機最一開始也不是為了飛機而做。沒有這些看似不相關的發明,或者說踏腳石,後續更偉大的成就就不可能達成。越是困難、高大上的目標,越是無法被詳實計畫。因為從所在位置到目標之間,並不是筆直一條線。
新奇搜索:放棄目標才有可能成就偉大
既然設定目標不管用,難道就沒有什麼其他比較好的方法了嗎?確實是有其他的方法,也就是所謂的新奇搜索法。主動去尋找新奇有趣的事物,因為這些事物看似雖然沒有關聯,但是卻是有可能成為未知目標所需要的踏板。
這裡作者用的比方我很喜歡:各種偉大的成就就像是散落在一個很大的空間之中,要前往某個偉大的目的地,這之間我們需要有很多踏腳石。然而不能期望前進的方向上所有踏腳石都清晰可見,有時離下一個踏腳石距離太遠根本勾不到。不過也許換個方向走,尋找其他看似不相關的踏腳石,卻反而有可能抵達該目的地。目標就像是指向偉大成就的羅盤一樣,方向明確但並不一定有用。
從上面的比喻我們可以知道,要在這個巨大的搜索空間中尋找有價值的事物,比起一味朝著某個方向前進,不斷去搜尋可以成為踏腳石的地方更為重要。最適合在這個空間中搜尋這些踏腳石的方法,就是所謂的新奇搜索法。我們越是去尋找有趣,從未見過的事物,它們可以創造的可能性越多,通往下個踏腳石,甚至是偉大的成就的機會也越大。我們放棄了偉大的目標,追隨自己的好奇心走,反而可能會抵達另一個不在計畫中的偉大。
避開競爭,走出屬於自己的人生道路
書中我最喜歡的一段是把生物的演化論拿來類比新奇搜索法。生物之所以會存在就是不斷的生存和繁衍,過去課本所學到的物競天擇會進行篩選,留下可以有競爭力、有能力存活的物種,讓生命持續「進化」。然而,作者反對這樣的思維方式,他認為生物演化就像是把牛奶往外潑,牛奶會持續向外擴散,直到遇到障礙物為止。生物也一樣,會不斷去尋找不同的可能性,盡量避免競爭。比起與同物種競爭,最終產生出一個超級生物,更好的方式是尋找新的生活空間、到新的生存環境,相對來說這個更容易達成。這也是為什麼我們會看到世界上有那麼多生物種類,不同環境都有自己的生態圈的原因。
用企業的角度來看,這也是一樣的。在上個世紀各種石油巨無霸、汽車製造巨頭主導著市場,但我們並沒有看到有什麼新的相關領域企業出現並與其競爭。反而是在未知領域,半導體、軟體、網路等方向有新的巨頭出現,對比這些舊企業對世界有更大的影響力。因為避開了在同個市場的直接競爭,所以有新的生存空間能夠發展。這個也是人們常說的紅海藍海的概念,在沒有過多競爭的藍海,才能有更大的可能性。
回歸到個人,老生常談中的做自己就好以及跟著興趣走其實也是有道理的。在人多的地方就會充滿各種競爭,跟著直覺覺得有意思的方向走,依據自己的個人特點避開競爭,反而更有可能得到世俗意義上的成功。書中有個比喻,假設目標是要成為百萬富翁,我就會避開沒有支薪的實習,就算非常喜愛這個工作。然而現實往往是因為追尋了內心的激情和興趣,而不是向「錢」看,某天才意識到自己離百萬富翁只差一個踏腳石而已。
小結
小目標可以被計畫,但是偉大則不能。本書打破了目標的迷思,大從政府企業,小到個人,對於偉大的成就需要有新的認知。在黑馬思維那本書有提到很多成功人士都是不會執著於特定目標,願意嘗試各種新事物,一旦感到苗頭正確,就做出特定的改變。或許這也是有異曲同工之妙。先追尋自我找到有趣的事情,一旦發展到後來對他人有價值,就能發揮出影響力,這時反而各種一般人所盼望的成就也會隨之而來。對於偉大,越是汲汲營營,越是不可得,就像是「眾裡尋他千百度,驀然回首,那人卻在燈火闌珊處」一樣。
反思與行動
雖然這本書是比較概念性的內容,還是盡可能轉換成可執行的行動,應用在自己人生中。
- 自己會走到當下這個位置,是經過無數選擇和探索,跟其他人完全不同。因此對於未來要走的道路,也不需要跟別人比較與競爭。
- 在當下所處的位置去思考有哪些可能性,保持好奇心,以實際行動去探索新奇事物。
- 一旦發現吸引自己的事情,就安心地跟著直覺走,勇於改變方向並前進。
]]>
@@ -100,7 +125,7 @@
http://evshary.com/2024/09/29/%E9%96%B1%E8%AE%80%E6%98%AF%E4%B8%80%E7%A8%AE%E6%9C%8B%E5%8F%8B%E9%96%93%E7%9A%84%E5%B0%8D%E8%A9%B1/
2024-09-29T22:17:17.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
我喜歡閱讀,而且很多人也很熱愛閱讀。儘管如此享受讀書,但有時候不免會被問到你看了那麼多書,到底學到了什麼?又或是聊天間提到某本書,你很興奮自己有看過,然而卻支支吾吾講不出其中的重點。當時間一久,書中內容逐漸忘去,自己也會感覺好像白讀那麼多書。雖然還是很愛閱讀,但是這些種種有時候還是很困擾。
以上這些都是我之前遇到的問題。為此,我慢慢摸索出一套方法讓閱讀的過程更加充實。在這個過程中,也逐漸理解讀書對自身的意義為何,可以用什麼心態來看待閱讀。下面會分成方法和心態來分別分享我的作法。方法
我閱讀每本書時都會創一個筆記檔案,其中記錄下面幾項內容,方便自己未來追蹤閱讀時的收穫和想法。不過要特別注意的是這樣的方式並不適合任何書籍,至少像是小說、詩集等文學類型就不能用這種方式。
閱讀前先問自己
這邊我會先問兩個問題:
- 為什麼我想要看這本書?我想從中得到什麼?
- 這本書的架構是什麼?作者用什麼方法來論述?
第一個問題主要是先知道自己的目的是什麼、想解決什麼問題。這樣在閱讀的過程中可以不斷反問自己作者是怎麼回答的。另外也會比較清楚這本書對自己的意義為何。第二個問題則是從宏觀的角度來觀察作者怎麼論述一個主題,我可以直接針對感興趣的部分先下手。其實這兩個問題都是用來釐清自己是否要閱讀這本書。深入了解一本書是需要幾個小時的時間,在投入之前先初步認識一下「新朋友」也是必要的。除此之外,也可以先去查查別人對這本書的評價和讀書心得,避免到後來才發現這本書和自己的預期差別太大。
劃線上加上原因
我想大部分的人都會在讀書的過程中劃線,記錄自己感動的句子。然而有時候會發現這些句子只是當下感動自己而已,事後回過頭來卻不知道為何要記錄下來。這個的原因在於我們會被感動是因為要搭配當下的那個情境,也就是那句話的上下文。失去了當時的脈絡,再好的句子也會讓人不知其所以然。
劃線就如同是單向的輸入而已,要有效率的學習,需要有雙向的溝通,也就是輸出。我通常會在每句有感觸的劃線上,加上一些筆記,記錄當下的想法。這些包括但不僅限於:為何這句話有感觸?我聯想到了什麼?有什麼樣新的想法?這樣的好處是能夠強迫去思考這句話觸動自己的真正原因,這個原因才是我們真正想要記錄下來的本質。
歸納數個重點
當閱讀完一本書,會有幾十、甚至上百道劃線。這時從這些劃線和我們記錄的想法精煉中出幾個重點。記得一定要用自己的話來重新寫出來,代表是經過自己思考過後的結論。這些重點就是簡化版的你從書中獲得的收穫。當別人問你對這本書的看法時,你可以直接回答這些歸納重點,藉此介紹這本書。重點越少越好,如果太多,反而會失去焦點。我個人建議是盡量在五個內,最多不要超過十個。
做這些歸納還有一個好處,未來你要回過頭複習這本書在講什麼時,可以直接先看這些歸納就好。因為有經過自己的思考,只要看到很快就可以回憶起這本書的內容。如果你想要更多細節,這時還可以回去看劃線的句子以及記錄的筆記。透過這樣的方式,基本上就不會有忘記這本書內容的情況發生了。
如何採取行動
對我而言,讀書的目的是要改變自己。可能是改變生活方式,可能是改變心態,也可能是發掘自己對某個領域的興趣。這時我會記錄下未來要採取什麼行動。一本書論述再好、內容再精采,如果只是看過就好,那其實幫助並不是很大。反過來說,閱讀一本書後,只要有改變自己,不論多麼微小,這本書就功德圓滿了。透過寫下要做的改變,正是強迫讓書真正進入生活影響自己的一種方法。
心得發表
最好的學習方式是能夠用自己的話把這本書複述出來。寫成心得需要對書有足夠的了解以及思考,最終轉換成有架構的文章。當然大部分的人沒有這麼多時間做這件事情。我自己是只有在看到很喜歡的書時才會透過心得分享來整理想法,這樣才更方便推坑給其他朋友。
心態
除了方法以外,我認為重新認知閱讀這件事非常重要。用不恰當的心態來閱讀,不但無法享受讀書本身,更無法吸收其中內容,只是帶來焦慮感而已。下面分享四點我對閱讀的想法。
閱讀是作者與自己對話的過程
以前我會想,有很多人把各種書的重點整理好了,像是幾分鐘了解一本書這類的文章、影音,是不是我就可以不用去看了,直接吸收他人的重點整理就好。甚至現在 AI 已經很方便,讓 AI 幫忙抓重點就好,根本沒必要自己去閱讀。畢竟很多書就只是為了講述一兩個道理而不斷論證而已。後來我才察覺,如果只是一兩句話就可以改變一個人的認知,那世界上大家都只要去讀讀格言佳句就好,書籍根本沒存在必要。
閱讀是一種對話的過程,作者提出了想法,刺激我們的思考,激發出了創意。在這個過程中我們和作者的認知世界開始交疊產生影響,有了新的思維方式。我們真正想要收穫的從來不是作者的思想理論,而是藉由這些所帶來的刺激。在閱讀某些書籍時,可能有人覺得內容了無新意,但是有些人卻很喜愛,因為作者的敘述方法能夠不斷激發他產生出新的想法。這些想法而非內容,才是閱讀的價值所在。
閱讀沒有 KPI
我個人的閱讀經驗是從一開始很愛讀書,到後來追求讀書速度和數量,最終才回歸閱讀的本質。閱讀的目的在於改變自己的思維方式,但很多人都會搞錯方向以為讀越多書越好。最終出現了很多怎麼一年讀 N 本書的理論,或是怎麼樣練成速讀的方法。我明白看到明確數字的提高是對人類成就感的一種刺激,會讓人更願意努力去達成。然而,我還是覺得這樣雖然能達成目標但是卻會養成畸形的心態。
由於現在清楚知道讀書是為了有新的思考,我更願意放慢速度,有意識拉長讀一本書的時間。我們都知道跟優秀的人相處會改變自己,相處越久影響越大,那為什麼不願意多花點時間跟優秀的書慢慢相處呢?每天都接觸一點,拉長時間,這樣更可以潛移默化影響思考習慣。人總是有慣性的,看完一本書後的刺激往往只能維持短短數天,但是透過長時間每天相處,這樣的影響力才能滲入生活之中。
閱讀不該形式化
從過去的學校教育中,其實制約了我們書要從頭開始看到尾的習慣。不但要按照順序看,還需要注意課本中的每個細節,因為考試很有可能就是從某個沒注意到的地方出題的。然而這樣的習慣並不適用真的想要從書中得到收穫。我們會想看一本書,大部分情況都是懷抱著某個課題希望獲得解答,想看看作者對此的看法。既然是想得到答案,那就沒必要用傳統方式閱讀,可以隨意跳著看,尋找解答。有些對自己幫助不大的內容基本上都可以跳過或快速帶過。不需要有強迫症一定要每個地方都看過才是真正讀完。
除此之外,看書這個行為,只要有從書中一句話獲得啟發,就值回票價了。過去我會希望把這本書提到的所有道理方法都記錄下來,並且細細理解。特別是有些作者會把方法或想法列點出來,這讓人覺得是重點,一定要記起來。但是後來發現這樣並沒有意義,有些自己沒有觸動的知識就算紀錄起來也沒有幫助,很快就忘記了。不如全心專注在真正為自己帶來影響地方,好好品味理解。一本好書在不同的人生階段看本來就會有不同的理解,劃線的地方也會不一樣。接受這個事實,知道未來可能會在合適的時間重新閱讀,因此現在只要享受這本書就好。就算是重讀,透過比較過去的筆記和擁有更多人生經驗現在自己的想法,也是一種有趣的體悟。
閱讀就像與朋友相處
閱讀本質上就是用比較低的成本認識跟你有不一樣視野的朋友。我們都有過這樣的體會,跟朋友聊天,透過分享他的經歷,看見了不同的選擇、不同的人生,拓展了認知圈。然而這樣的朋友,特別是和自己性質相異的,並不是那麼多,大部分認識的朋友還是在同溫層中的居多。不過,閱讀卻可以帶來相似的效果。閱讀的過程就是在和作者交流,他分享自己的人生視角,為讀者帶來新的啟發。這也是突破同溫層,看見不一樣世界的好方法。
把書當成朋友還有一個好處,我們不再著急要把書看完了。試想,有哪個人會為了交更多朋友,只是跟眼前的人快速聊聊就結束嗎?我們會更專注跟這位「朋友」互動交流,從他身上獲得知識,並且反饋自己的想法,建立起一種「對話」。透過思考他的生命和我的有什麼不同,啟發了新的想法,開啟自己人生不一樣的可能性。
結語
以上分享是從我過去看書的經歷中摸索出的作法,在享受閱讀的同時也能從中獲得扎實的收穫。當然,每個人都有自己一套和書相處的方式,適合自己最重要。如果我的分享能有稍稍為你帶來啟發,那就再好不過了。
]]>
@@ -125,7 +150,7 @@
http://evshary.com/2024/09/22/%E7%8D%B2%E5%8F%96%E8%B3%87%E8%A8%8A%E4%BE%86%E6%BA%90%E7%9A%84%E6%96%B9%E6%B3%95/
2024-09-22T15:52:35.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
在現代社會大家獲得資訊的管道已經不侷限於新聞媒體或報章雜誌了,像是 YouTube、Podcast、短影音或部落格等等都是常見的方式。最讓人苦惱的不是有沒有資訊,而是優質的資訊源。太多的訊息反而讓自己的注意力被分散,而無法專注在真正帶來價值的事物上。不過話又說回來,適當地更新資訊也是保持我們對世界變化維持敏銳關注的必要一環,維持一個巧妙的平衡很重要。這裡分享一些平常我得知新知的管道:
Podcast
我最常使用的資訊來源獲取管道,主要是可以邊聽邊做其他事情
- 曼報:兩位主持人會針對某一個產業或公司進行深入介紹,可以讓人有個概括的認知
- 財報狗:裡面有個達人聊產業單元我很喜歡,來賓會分享該產業的一些概況,以及自己是怎麼經營事業的
- 解鎖地球:受訪者會講自己在世界各地經歷的不一樣風土民情
- 斐姨所思:鎖定台灣熱門議題的節目,有時候會邀請到不錯的來賓,主要看邀請到誰來決定要不要聽
- 忽左忽右:社會人文的優質節目,從歷史、文學、能源到政治無所不包
- 硅谷 101:在科技產業工作的話必聽,主要談談各個新興產業發展狀況,自動駕駛、AI、星艦、核能等等。由於受訪者常常是在矽谷工作的中國人,很常比較中國和美國兩國的產業發展狀況
- 聲東擊西:也是社會人文類的節目,但是內容有時比較從心理哲學層面出發,而在美國大選時還有一系列介紹候選人的內容
- 商業就是這樣:主要對一些時事延伸出有趣的商業主題,像是法國奧運時就會有奧委會怎麼挑選比賽項目
- Foreign Policy:關於外交政策的訪問,嘉賓不侷限於美國人,有時會訪問國外的前元首、外交部長、國防部長等等
- Lex Fridman Podcast:很多知名人物都有被訪問過,如川普、馬斯克、祖克柏,不過老實說他的訪問實在太長了,動輒就是幾小時,所以我只會挑有興趣的來聽
- All-In Podcast:主要是了解這四位知名投資人對美國和世界局勢的看法,比較偏向美國國內的視角,但是他們有些觀點有時會讓人耳目一新
YouTube
其實大部分情況下我都是把 YouTube 當成 Podcast 來聽
- 小 Lin 說:淺顯易懂的經濟商業科普節目,小 Lin 的團隊很強,可以把複雜的事情轉換成簡單的架構
- MoneyXYZ:主要是分享他的人生觀,然後會介紹一些好書。他的特點是可以把書中的論點講得很有說服力
- RealLifeLore:介紹世界各國地緣政治的節目,很常會從地理出發,給人耳目一新的論點
- PolyMatter:介紹各個國家狀況的節目
- Norges Bank Investment:挪威主權基金的節目,會訪問一些優秀的企業家
- Johnny Harris:一個獨立記者的頻道,主要鎖定國際政治
我大部分都是用 RSS 來訂閱一些部落格的更新以及部分快訊
- 地球圖輯隊:世界各地的有趣事情
- 報導者:對很多社會議題做深入的報導
- Paul Graham:有名的風險投資人,雖然發文頻率很少,但每篇都能引起廣大迴響
- 阮一峰的网络日志:每週會有一篇週報,整理一些有趣的科技新知
電子報
有些不錯的文章會透過電子報的形式發表出來,我會有限度的訂閱,畢竟也不想要塞爆自己的信箱
- 曼報:同 Podcast,是介紹各產業的文字版本,但是有時候和 Podcast 並不會完全一致
- M 觀點:作者是研究科技巨頭的專家,會追蹤科技企業的狀況並且分析,科技領域工作的人值得追蹤
- 瓦基:專門分享各種書籍的讀後心得,我主要是透過他的介紹來找到不錯值得一讀的書
Telegram
主要是追蹤一些有趣的資訊,由於我不使用社群媒體,所以就從 Telegram 這邊來獲取
- 敏迪選讀:淺白口吻介紹一些國際局勢相關的新聞,一些平常我們沒注意到的地方,如孟加拉、非洲、南美也都會提及
- IEObserve:有時會分享一些有趣事物,和科技經濟相關
- 股癌:一樣會分享科技經濟的有趣事物
小結
簡單分享一下自己對資訊來源的看法和原則
• 不需要怕自己資訊來源不夠豐富,重要的是有可以信任的優質來源,並且可以不斷隨時間更新自己的獲取管道,不合時宜的也要敢於移除。
• 不需要急於獲得短時間內的消息,我自己對新聞類的資訊不是很在意。因為如果真的有重要的事情發生,它自然會浮現在自己的認知圈中。
• 獲取的資訊盡量以長期對我們有幫助為主,例如看見不一樣的人生觀或世界觀,認識新的國家或產業等等。
• 我會盡量不要透過社交媒體得到資訊來源,因為很容易被其他事物所分心。
• 就算是挑選過的資訊來源也不一定所有的內容都要看,掃過標題,真的有興趣再看即可
這個列表會持續更新,也歡迎大家分享自己的資訊來源。
]]>
@@ -150,7 +175,7 @@
http://evshary.com/2024/09/17/%E8%AA%8D%E7%9F%A5%E9%A9%85%E5%8B%95%EF%BC%9A%E5%81%9A%E6%88%90%E4%B8%80%E4%BB%B6%E5%B0%8D%E4%BB%96%E4%BA%BA%E5%BE%88%E6%9C%89%E7%94%A8%E7%9A%84%E4%BA%8B/
2024-09-17T11:20:11.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
這本書在說什麼 & 適合的人「認知驅動」是周嶺「認知覺醒」的續作。如果要用一句話概括這本書,那就是不要過度關注內在的自我成長,要對外為他人產生創造價值,而外在的回饋將會回到自身。本書雖然零零散散引用很多其他人觀念或道理,但我覺得這些都圍繞在如何行動並對外創造價值上。
這本書適合那些重視自我成長,但是看了很多書,學了很多道理,卻對未來仍然迷惘的人。在中國有一句話很常見:「懂了很多大道理,卻過不好這一生」。比起不斷吸收別人灌輸的道理,當一個社會的消費者,更好的做法是用實際行動提供價值,成為這個社會的創造者。閱讀後會開始思考,自己究竟可以怎麼創造社會所需的價值,當成為社會所需要的人時,就會很明確未來要走的方向了。
我畫線的地方
下面提供一些我畫的重點,幫助你認識這本書。
當自己覺得很努力卻沒有成果時,看看是不是過度關注輸入,而沒想著對外輸出
- 內向成長,即圍繞⾃⾝展開的成長活動,⽐如早起、跑步、閱讀等。
- 外向成長,即圍繞外界展開的成長活動,⽐如寫作、畫畫、寫程式等。
…我們過度專注於內向成長⽽忽視了外向成長,即重習慣輕技能,重輸⼊輕輸出。
只有自己夠有價值,才能被他人強烈需要,而被需要就會創造交換的機會
改變⾃⼰的關鍵是創造價值…因為只有當⾃⾝創造的價值⾜夠⼤時,我們才能被別⼈強烈需要,才能參與到更⼤的社會交換中去,並得到對⽅對等的回饋
降低期待,不要急於求成,事情自然就會做好。有時太多的壓力都來自於好高騖遠。我們很容易高估短時間內的成果,而低估長時間所帶來的改變。
我的⼀個減壓秘訣就是盡量不要同時設定很多⽬標,主動降低期待,不急於看到成果。這⼀秘訣⾮常奏效。因為不管是外部的還是內部的,只要⽬標或欲望⼀多,我們必然會焦慮叢⽣、急於求成
讀書只是幫助我們提高視野,用不同維度看事情的手段,而非真正的目的
讀書並不是⼈⽣成敗的分⽔嶺,那麽真正的分⽔嶺在哪裡呢?答案也是兩個字:維度。
能夠創造屬於自己的價值,或許就會解決人生意義這個問題,因為我們被他人所需要
需要我們的⼈越多,我們的幸福感就越強,就會樂此不疲地踏上⼈⽣旅途,根本沒有時間去想「⼈活著的意義到底是什麽」這樣的問題。只有當⾃⼰毫⽆價值、被⼈忽視的時候,我們才會糾結於此
個人想法
這本書給了我不少收穫,下面用三個角度來分享:
輸出重於輸入,利他就是利己
過去幾年我每年平均也都有閱讀 30 本書左右,卻仍然覺得自己好像都沒有太多成長。常常對一件事情有不少的看法,而且也覺得確實比起他人自己對一些事物的認知角度有些不一樣,然而有時候只會覺得這些好像沒什麼意義。學更多東西還不是只是過普通的生活,與其動輒花幾小時讀完一本書,不如花在讓自己生活過得更舒服似乎更有價值。在書中的開頭作者提到的和讀者問答一下子就命中了要害,「那你有什麼產出嗎?」。的確,我好像都沒有用知識生產出什麼有用的事物。
為什麼自己會停在只接受輸入而已呢?因為接受輸入最容易實現,我只要被動去學習作者的思維就好,而不需要費盡心思思考怎麼創作。就像是用戰術的勤奮來彌補戰略的懶惰。每看完一本書都會感到自我感覺良好,好像等級上升,變成全新的自我。若是仔細想想,看完書的前後我真的有什麼改變嗎?好像也不太多,只能安慰自己這些改變都是潛移默化。
那為什麼需要輸出呢?書中提到幾個點:首先輸出就是在確保自己真的了解,我們都經歷過自以為理解,卻發現要自己複述卻講不出來的情況,這就代表並非真的學會。再來,輸出的好壞全部由外界評判,就像是練琴一樣,如果自己只是悶著頭不斷練,卻沒有外界給予回饋,那可能最終只能感動自己而已。最後就是要產出價值,這個社會其實也是遵循等價交換的,當一個人所提供的價值足夠大的時候,自然就會有相等價值的機會產生。作者對利他就是利己的解釋也是來自於此。我們被他人所需要,對方也會提供我們同等的回饋。
作者提到這個社會分為三種層次:消費層、生產層、創造層。消費者不需要有任何目標,他們可以無意識的消費著其他層所創造的事物,例如文字、影片或是各種有形的商品等等。生產層是由外在所逼著生產事物,就像是工作一樣,我們不是創造而是生產他人所要求的產品。至於創造層,雖然也是在生產,但是這些東西會貼上他們專屬的標記,這是屬於他們的東西。一旦社會可以給予正向回饋,巨大的成就感和意義就會隨之而來。透過主動創造,就能跳脫漫無目的消費,更加清楚自己所想要的,並且也提供給這個社會額外的價值。
人生成敗的分水嶺不是讀書,而是維度
當初我會想閱讀這本書,正是來自這句話。老實說,這句話乍看之下有點世俗:為什麼要定義人生成敗呢?怎麼比較不同人生的好壞呢?難道我不能過著普通人的生活,而要去追求他人眼裡的成功嗎?不過或許我們可以先不要管成敗,而專注在所謂的人生歷練。有些有智慧的人可能一輩子沒讀多少書,但是可以說出直指人心的話語,正是因為他們已經經歷過這些,看過太多相同的劇情。實際親身經歷過,眼耳鼻等感官多個維度都接觸到,比起單純看他人文字敘述更加刻骨銘心,而這其中的差距就是知識與智慧差別。
這樣讀書就沒有意義了嗎?假設世界上有個機器,可以快速讓我們經歷無數次人生,體驗各式各樣的可能性,這個機器的效用可能比讀書更加有效益。然而這個機器是不存在的。也許我們有那個機遇可以遇到很多優秀的人事物幫助我們拓展眼界,但是更多時候我們只是個普通平凡人,日復一日過規律的生活。這時最低成本的方式是透過書籍看到其他人不一樣的人生,看見優秀的人不同的思考方式,進而認知到生命也有不一樣的可能性。擁有書本的知識後,遇到新的人生各種挑戰,就更有機會找出適合的應對方法,產生出更高的智慧。
不過,對我而言這句話的含義反而是在於要認清楚自己讀書的目的。不應該過度追求閱讀本身,不管是閱讀的時間或是數量。最重要的是有沒有透過閱讀這個行為改變自己的思考方式,是不是能夠從更高的維度來思考生命中遇到的各種問題,而不是拘泥在現有的眼界中。閱讀的目的在於用低成本的方式看到生命不一樣的可能性,不要把手段和目的搞錯。
降低期待,不要急於求成
書中不斷反覆強調的另一個重點在於不要急於求成。我們常常都會同時設定多個目標,希望趕快達成,因此市面上也就因應產生出大量教導如何速成的書籍。這個也是現在步調快速的社會所造成的結果,大家會焦慮自己趕不上他人,任何事情都期望有捷徑可走,反而造成心裡大量的壓力。這時可以從降低期望下手:降低數量,一次只針對一個目標;降低難度,不要期待短時間可以搞定問題。
這也是我的親身經歷,我常常會設定多個目標,然後要求自己在每月每週每天要達成某個程度,但發現最終都做不到,又或是無法長期堅持。而在工作上面,也總是在多個任務之間快速切換,想說可以更加有效率,卻發現完成時間沒有比較快,反而品質降低,而且身心疲憊。慢即是快並不是老生常談,而是確實有用的道理。人們總是高估自己短時間可以達成的成就,低估長時間能夠做到的結果。
作者提到了一個解決焦慮、急於求成的方法,也就是「七年就是一輩子」這個概念。人們的一輩子常常就只專精於一項技能,而如果我們轉換思考,每七年只專注在一個技能上,那麼我們可以活上好幾輩子。這個思考方式可以避免我們對多個目標的同時追求,造成極度焦慮,也增加自己的耐心,不再用短時間刻度來看待自己的人生。若是拉長時間來看,會意外地發現自己已經成就不少事情。
小結
從整體來說,我並不認為這本書的架構十分嚴謹,更像是作者把自己所瞭解的各種理論方法拼湊在一起呈現給讀者。因此有些道理我並不認為真的那麼有說服力。但是,就如同作者在書中所說的,一本書如果有一段話影響了自己,那麼閱讀這本書就十分值得了。從這本書中,我體悟到了行動的重要性。比起學了很多知識,怎麼把這些知識轉換成對他人有意義的事物更為重要,這也是我想要重新經營部落格的原因。在人生當下的階段,專心並有耐心把一件對外部有價值的事情做好,不要急於求成,等幾年過後再回頭來印證這個方法是否正確吧!
反思與行動
若是閱讀能為自己帶來任何行動上的改變,那這本書就物超所值了。以下列出幾項我的行動清單:
- 反思自己可以為他人創造的獨特價值為何。當學習新事物的時候,可以想想有沒有什麼方式可以輸出價值。
- 用較大的時間刻度看看自己過去的成就,可以用時間軸的方式來呈現。然後想想接下來的人生階段要以什麼事情為最大的優先目標。
]]>
@@ -177,7 +202,7 @@
http://evshary.com/2019/08/03/%E4%B8%80%E4%BA%9B%E6%B8%9B%E5%B0%91code-size%E7%9A%84%E6%96%B9%E6%B3%95/
2019-08-03T16:39:40.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
前言在開發嵌入式系統的時候,很常遇到需要在資源緊張的環境上進行開發,所謂的資源緊張大概不外乎memory不夠使用、flash不夠大,但是老闆或PM仍然希望RD在產品上面新增feature,這時候就只能針對code size進行優化了。我自己待的部門剛好就是遇到這種產品已經維護10年以上,可是又希望加新feature的狀況,因此開始尋找減少code size的方法,這邊分享一些我自己的心得。
Compile Optimization
首先我們可以看一下compiler是不是已經做過優化了,大家都知道gcc在編譯的時候可以選擇optimization的level,從0-3。0代表的是default,而隨著數字越高,對code size和execution time的優化就越高。
大部分的人都會建議使用-O2,在code size和execution time取平衡,但是如果真的對code size十分在意的話,其實也可以使用-Os,代表的是-O2但是不包含部分會影響code size的優化。
到底每個optimization的level是做了那些優化,可參考GCC的官方文件
strip
strip算是最基本的降低code size工具,他會移除debug資訊(可供gdb使用的資訊)以及symbol table,因此size會降低許多。
這邊簡單做個實驗:
1
2
3
4
5
6
7
8
9
| #include <stdio.h>
void func() {
printf("func\n");
}
int main() {
func();
return 0;
}
|
- 接著來編譯,為了凸顯strip的效果,我們加上-g來加上gdb debug訊息
- 接著我們可以用
nm -a test來看到他的symbol table
1
2
3
4
5
| 0000000000000000 a
0000000000201030 b .bss
0000000000201030 B __bss_start
0000000000000000 n .comment
....
|
- 以及用
objdump -h test來看到有哪些section header,可以發現有許多debug資訊
1
2
3
4
5
6
7
8
9
10
11
12
| ...
27 .debug_aranges 00000030 0000000000000000 0000000000000000 0000105d 2**0
CONTENTS, READONLY, DEBUGGING
28 .debug_info 0000033a 0000000000000000 0000000000000000 0000108d 2**0
CONTENTS, READONLY, DEBUGGING
29 .debug_abbrev 000000f6 0000000000000000 0000000000000000 000013c7 2**0
CONTENTS, READONLY, DEBUGGING
30 .debug_line 000000d4 0000000000000000 0000000000000000 000014bd 2**0
CONTENTS, READONLY, DEBUGGING
31 .debug_str 0000028a 0000000000000000 0000000000000000 00001591 2**0
CONTENTS, READONLY, DEBUGGING
...
|
- 接著執行
strip test後,會發現symbol table已經消失了(無法使用nm),以及沒有debug的section header。兩者size有極大差異。
1
2
3
4
5
| > ls -al
-rwxrwxrwx 1 evshary evshary 11152 Aug 4 11:34 test
> strip test
> ls -al
-rwxrwxrwx 1 evshary evshary 6304 Aug 4 11:39 test
|
objcopy
strip可以減少極大部分的code size,但是如果這樣還不夠的話,我們可以用objcopy把一些沒用到的section header移除掉,但是要提醒一下,這個移除幾乎不會影響太大,大概就幾百byte而已。
1
2
3
4
| > objcopy -R .comment -R .note.ABI-tag -R .gnu.version test small_test
-> ls -al
-rwxrwxrwx 1 evshary evshary 6304 Aug 4 11:39 test
-rwxrwxrwx 1 evshary evshary 6024 Aug 4 11:45 small_test
|
這邊所謂的沒用到section header主要是一些環境的版本資訊,到底這些header代表什麼意思,可以參考Linux Standard Base PDA Specification 3.0RC1 - Chapter 5. Special Sections
利用 compile option 來移除沒用到的 symbol
我們知道程式裡面常常會有些程式碼(function/data)並沒有被人使用到,不論是因為長久maintain被修修改改,還是因為本身就有預留給未來使用。但是這些沒用到的功能如果都被編進去程式中其實是很浪費的,我們這邊可以用一些小手段來移除。
在gcc的編譯過程中我們可以加上特別的編譯參數-fdata-sections和-ffunction-sections,這兩個的意思是把每個symbol(function或data)獨立成不同的section。為什麼要這樣做呢?當然是為了後面在link的時候我們可以直接移除沒用到的section,在link的時候多加上--gc-sections參數即可。
細節可以參考How to remove unused C/C++ symbols with GCC and ld?。
觀察 map file
map file是我們在編譯過程中很重要的一個工具,他可以用來檢視目前symbol的size有多大,我們可以用nm來取得symbol table,甚至根據symbol的size大小來排序(指令是nm --size-sort -r -S [執行檔])。透過觀察map file,我們可以瞭解程式內部每個功能佔的大小為何,進一步思考有沒有優化的空間,甚至發現該功能根本是沒有在使用的。
我自己也曾經有遇過code size的問題,那時候我一樣是用nm來讀取map file,忽然發現某個變數大到不可思議,觀察了一下發現那個變數是直接用global的方式宣告,並不是要用的時候才malloc,導致在一般firmware運作的過程中那塊記憶體完全沒辦法被使用。更重要的是那個功能並不常被使用,而且還會隨著硬體平台有不一樣的大小,結果RD為了方便,直接保留可能會用到的最大值,造成空間的極度浪費。
Remove debug message
其實RD在開發的過程中,或多或少都會留一些debug訊息,雖然少少的,但是累積起來量也是很驚人,畢竟一個debug訊息就是一個字串。在code size緊張的情況下,應該可以審視一下,看能不能把debug訊息移除。
值得注意的是有些embedded的firmware確實是會有關閉debug資訊的方式,但是這個有可能只是不顯示(例如關閉console顯示),並不是真的移除,要仔細確認自己的狀況是哪種。
不過如果真的到了一定要移除debug訊息程式才能夠被使用的情況,這樣也挺危險的了,因為未來如果要maintain,必要的debug訊息還是逃不了。我會建議程式開發的過程中每個功能都可以自行決定要不要把debug的程式碼編進去,至少遇到bug還可以只開啟相關功能的debug訊息,而不是全部訊息都全開。
移除沒用到的功能(library)、檔案
在我們的embedded firmware裡面有些會需要使用SSL或SSH這種非常龐大的library,可能佔firmware的size超過1/3。像是這種library其實有很多功能是我們沒有用到的,以SSL、SSH來說,其實我們只會用到其中少部分的加密cipher,而不是全部。如果真要使用,建議要對library本身功能機制足夠熟悉,在編譯的時候只開用到的option即可。
除了library外,一個產品經過長時間的maintain,中間一定會有許多功能是後來沒用到,卻沒被移除的。如果只是程式碼倒還好,可以用前面提到的gc-section來排除,但是如果是file system的檔案,那就要靠自己來處理了。我個人的經驗是,有很多功能是過去產品有的,但是因為後來時代不符合被移除,結果相關檔案就都一直遺留下來,例如可在browser上面運作的java plugin等等,這些的size是也很可觀的。
Compression
壓縮也是減少code size的其中一個方法,除了啟動的程式外,我們可以把runtime過程才要load的東西進行壓縮。通常這類的角色可以是kernel啟動完成後另外加載的AP,或是filesystem。不過壓縮要考慮的點就是壓縮率、解壓的程式碼的大小以及速度,最好可以在這其中之間取得平衡。壓縮率對我們來說就是可以把程式縮小到什麼地步,如果縮小不大就沒有意義了,然後解壓的部分也很重要,要是有很高壓縮率,但是解壓程式很大,那整體來說並沒有得到多高的效益。而如果壓縮率高,但解壓速度過慢,也會影響到使用者體驗,這些都需要考慮到。
filesystem的部分有點可以稍微注意一下,大部分的應用都是web居多,而web其實是有壓縮的空間,且不需另外解壓的。我們知道一般web都是由html、CSS、javascript所組成,而這些內容丟給browser的時候並不需要是人眼比較好閱讀的方式,例如說不需要換行、縮排等等。這麼一來我們就有可以動手腳的空間,可以在編譯過程中,把原始的檔案做壓縮,最後才變成file system,這樣的壓縮率是很可觀的。除了減少size外,這還帶來另外一個很大的好處就是減少網路流量的傳輸,特別在embedded system中系統效能其實都不快。提醒一下,記得開發過程使用git追蹤的web檔案最好是原始檔案(人眼好讀的),編譯過程才壓縮,不然這只是給自己帶來開發的困擾而已。
web壓縮的方式網路上有很多,有些甚至提供online的服務,例如HTMLCompressor或是textfixer等等,可以自己尋找適合的工具。
結語
上面分享了許多方法,但最後我要先澄清一下,自己需要搞清楚到底不夠的是flash還是memory,上面的方法並不是做了兩個都一定會減少。舉個例子來說,移除沒有必要用到的大變數通常只會影響memory的使用率,因為compile出來firmware的size並沒有包括大變數(因為是bss section,未初始化區段),而file system的壓縮通常也只會影響flash的使用率,除非firmware有把檔案預先從flash讀出來放在memory中。我想強調的是使用這些方法時,還是要有必備的系統觀以及對你的系統有一定熟悉程度。
老實說軟體開發者最討厭的大概就是被各種硬體條件所限制,然而這些在embedded的世界中還是有很大的機會會遇到,特別是考量到成本的時候。雖然很討厭這類的問題,但是解決後其實還是蠻有成就感的。以上分享希望能夠幫助大家解決code size issue。
參考
]]>
@@ -204,7 +229,7 @@
http://evshary.com/2019/06/23/%E4%B8%89%E5%B9%B4%E7%9A%84%E5%B7%A5%E4%BD%9C%E7%9C%81%E6%80%9D/
2019-06-23T20:29:02.000Z
- 2024-10-27T09:36:44.308Z
+ 2024-11-03T13:19:38.800Z
前言工作到現在已經三年半了,雖然有許多成長,但也看見自己很多的不足,可以再進步的地方。個人覺得如果要能夠更快速地成長,需要定期總結自己的經驗以及所學習的東西,並且思考未來可以再怎麼做會更好。平常我有做日記的習慣,但是還沒有為自己統整工作上面的心得,這邊除了當作紀錄以外,也是可以提供給跟我差不多狀況的人參考。不過老實說,這些分享並不一定正確,但是至少是此時此刻的我最真實的想法,也歡迎大家多多指教。
經歷
畢業前
我是從研替開始軟體工程師的生涯,以前在大學、研究所時,雖然有寫程式,但是畢竟都還是學生等級的程式,個人是覺得不夠深入與成熟。不過另一方面其實也累積了不少基礎,有許多重要的知識都是那時紮根的,包括Linux的使用、git的使用、Network的概念、Security的概念,這些對後來的自己都有很多幫助。雖然有時會想要是現在的自己回到過去的話,肯定可以學得更快更好、更有效率,畢竟產業和學術上還是有多少落差,但這也都有點後見之明了,而且正是因為曾經經歷過,才會有不同看事情的角度。會覺得過去要是怎樣怎樣現在就會更好,大概是人免不了的通病吧!
第一年
進到職場後,最不習慣的是每件事都要很清楚是在做什麼,過去在學校基本上只要code能work就行了,所以最常做的就是上stack overflow找找,然後copy & paste,不太會去理清背後的原理,或是思考怎麼做才會更有效率。然而在職場上,如果只是剪剪貼貼的話,遲早會出問題的,被同事問回答不出來還是小事,更慘的是自己做完了導致其他的bug出現。另外一點是動作需要很迅速,我記得剛過試用期後就被交付了要porting BSP上的ICMP的功能到FreeRTOS,時間給我3天,結果最後花費的時間還是超過,這跟學校其實差異很大,我在學校光是改一個memory leak的bug就改了2個月(雖然是因為還要兼顧課業)。最後,關於品質的部分,也是那時的我需要克服的坎,我不喜歡做測試,可是當時的主管就很強調要做自我驗證,才不會提供的程式上面有很多顯而易見的問題,給出去的程式也是代表自己的品牌,需要細心驗證才行。
其實整體來說,我在職場上的第一年大概是以調整心態並且適應工作為主,而工作內容大概都是偏向AP層的修改,或是開發些應用程式。最常見的case大概是做客製化的firmware以及處理客戶回報的問題,改的內容不外乎是web上的修改,或是AP層上面的邏輯的問題。不過也不是沒有要寫新feature,包括在JAVA應用程式上用JNI連結到C library、Linux command line tool、帳號管理API等等,或多或少訓練了怎麼設計程式架構。
第二年
第二年開始我已經有能力解決比較困難的問題,那時團隊遇到SDRAM不足的問題,後來我透過分析map檔找到一個沒有必要使用的巨大global variable,克服這個難關。不過老實說,我現在回想起來這個問題也不是太難,只是要對firmware compile過程有比較深一點的認知而已。另外當時遇到了過熱當機的問題,這個老實說是幫助我成長最大的問題,我把NXP的MCU spec讀了好幾次,了解了ARM的exception架構,另外也深入理解FreeRTOS以及lwip等NXP提供的BSP是怎麼與MCU互動的。除此之外,我基於資深同事提出的proprietary protocol架構上做改進,並且設計提供給AP使用的API,其實也理解了設計protocol的原則,包括易用、相容性、功能獨立性等等。
這一年對我來說是技術成長最快的一年,開始練習解決問題需要有系統的思維,除了AP層以外,更加理解軟體與硬體的相依性,BSP的概念等等。那時候我常常都是在ARM的exception handler中加上dump stack的功能,然後反推造成當機的原因。這些經驗對後來看待問題時有很大的幫助,會思考這個OS的運作性質是什麼,怎麼去分配記憶體的,比較能夠有系統觀去解決問題。
第三年
第三年因為要做經驗傳承,開始跟資深同事學習公司既有的proprietary OS,除了AP以外,更重要的是底層kernel的運作,類似UNIX上面STREAM的架構。由於FreeRTOS的架構相對來說比較簡單(有些人甚至認為比較像library),所以proprietary OS也是強化了我對OS的理解,而且多了可以比較的參照物。除此之外,因緣巧合下我開始有了機會可以當project leader,雖然團隊加上我只有3個人,不過也算是個不錯的經驗。我主要負責的是與PM、測試溝通,然後分配feature & bug給團隊,並且確保merge的code沒有任何問題。同時間,我也開始和其他同事合作導入CI/CD、code review的概念,剛好就在我的project上進行實驗。
這個時間點對我來說除了技術以外,開始有了與人相關的任務,不論是領導還是溝通。另外因為自己有比較多一點的權力,所以也嘗試導入自己所喜歡的文化,如CI/CD。比較有趣的是,我發現以前的同學也差不多在這個時間擔任leader的角色,也許大家走的路都差不多吧!
現在
延續前一年,我開始擔任既有產品的maintain窗口,學習分配工作給團隊的其他人,並且思考要怎麼進行有效率的溝通,不論是團隊內還團隊外。技術方面則是開始接觸eCos這個系統,雖然外界已經沒人在用了,但是這個產品仍然需要有人maintain。發現挺有趣的是我差不多一年接觸一種OS,也加深了以前學OS的一些概念,例如synchronization、scheduler等等。
其實到了現在我覺得已經進入了一個坎,技術開始進步緩慢,而且因為既有產品線眾多,有許多maintain的effort,沒有心力去學新技術。目前,不得不好好反思自己的職涯規劃,以往我都是認為只要有學習成長就可以了,沒有想太多自己未來的走向,包括什麼是自己的強項,我接下來的時間要學什麼,可以成長多少等等。如果再宏觀一點,從人生角度來說,我規劃學習這些技術對工作有什麼幫助?在我的生命中是什麼樣的地位?我的人生究竟是想要什麼?成就感嗎?還是只要賺夠多錢就行了?這些都是以前有想過,但是沒有仔細思量的,現在因爲工作上面遇到了些障礙,所以會開始思考什麼才是自己想要的。
雖然我是因為感覺沒有成長所以思考是不是要改變跑道,但是另一方面來說,我覺得也是因為這個契機才開始會反省工作在自己人生中的意義是什麼,這倒也不是什麼壞事。人本來就應該要很清楚自己想要什麼,留在某個地方就是要承擔自己失去的其他機會成本,離開某個地方就是要能捨棄當前環境的舒適以及穩定,沒有好或壞,就只是要自己承擔相對應的責任。
總結
這職場三年多下來,其實我也學習了很多事情,比起技術而言,我覺得最重要的是觀念的改變。從一個人的觀念和面對事情的態度,大概就可以推估他的未來發展。技術要學其實是可以很快,但是個人特質是很難短時間內改變,因此我覺得這是影響個人成就非常深遠的關鍵。以下就我的觀點分享認為重要的事情。
- 發問前一定要再三思考
- 在問別人問題的時候,要先思考想從對方那邊得到什麼樣的答案。簡單來說就是不要無腦發問,同事都是很忙的,所以相對應來說可以問問題的次數是有限制。因此每次發問都先思考:我問的問題是否其實查一查資料或做做實驗就可以解決?我想問的問題到底是什麼?有時候整理一下自己的想法後,就赫然發現其實問題已經得到了解答,根本不需要問人,這也是常聽到的Rubber Duck Debugging。
- 一般來說我們遇到不確定的問題都會去請教主管,看要怎麼做會比較好,這個做法在剛進公司時是OK的,畢竟對工作內容還不熟,但是隨著自己慢慢熟悉,要做的應該是自己能夠做主並且決策。以公司的角度來說,多請人就是要減少大家的工作量,如果事事都要去問人的話,那就不需要多請人了。當然有些問題可能是一定要主管做決策的,那可以提出自己的想法以及建議的解決方式,主管只要確認我們的解法沒有什麼大問題就可以了。
- 定期反省,找出更有效率的做法
- 可以的話,建議每天做日記,思考今天的工作內容有什麼可以改進之處。不過老實說這樣確實是蠻累的,而且會變成無腦的慣性,所以也可以改成每週一次。一個人在工作上的表現,大概就是解決問題的能力和效率,如果這個能力能不斷提升,能創造的價值就越高。
- 舉例來說,在我的公司就是要處理很多文件流程,每次要跑大家就都要到處問人,後來我受不了了,乾脆自己整理一份跑流程的SOP,每次跑我就參考SOP執行,如果有錯再修改SOP,大大減少我在工作上的煩躁感。而且後來有新人進來要跑流程時,我也可以請他們看SOP,而不需要手把手教學,減少時間的浪費。
- 用目的論思考,了解自己做的事情是為了什麼,要解決什麼問題
- 我發現有時候自己做的事情和別人對我的期待其實是有落差,我認為重要的東西,別人卻覺得那個不是重點。因此面對任何任務,都要確定做這件事的目的是什麼,例如是要給客戶滿意的解釋,還是要百分之百肯定問題的根因,然後是不是值得投入相對應的資源。
- 常常做事情都會不小心過度鑽研在細節上面,大家各自提出自己的意見,而無法做出正確的決策,這時候最好都是要回到最初的問題:我們到底是要解決什麼,怎麼決策才能符合我們最一開始的目的。不會有完美的解答,但是只要能達到設定的目標,那就是可以接受的答案。
- 溝通的時候,站在對方的立場思考
- 工作上基本上一定會有cowork的機會,而很多的爭論幾乎都是來自於溝通不夠完全。回應他人的問題時,可以站在他的角度思考,他想得到什麼答案,我能提供什麼答案,怎麼在中間取得平衡,不要變成事情都是某一方去承擔,另一方面也是提高溝通效率,不會信件來回很多次都得不到共識。
- 有時候不要太依賴信件,有些情況直接面對面溝通會來得有效率,且也不會太過生硬,讓人有距離感,有時候都是因為雙方文字上彼此誤會而吵起來。
- 要定期盤點自己的能力
- 我會強烈建議要隨時maintain一份A4的履歷,並不是說要騎驢找馬,而是為了把自己重點且精華的能力精簡成一份履歷,其實也是認識自我的一種方式。整理完後會發現原來自己的強項是什麼、還欠缺什麼,工作的時候就比較不會得過且過,而是會用宏觀的視野思考為什麼要做,還能怎麼做會更好,因為這些都將變成未來與人談判的籌碼。當然如果有好的機會的話,已經有一份履歷在手,就可以隨時把握。
- 負起責任
- 負起責任有幾個方面,首先就是對自己做的事情,任務交到自己的手上,那就是要把它做好,如果發現有任何問題就是要隨時反應,不要到了最後一刻才說。另外這也隱含了一點:我不是機器人,別人說什麼就做什麼,而是要有能力自己判斷、決策並且承擔最後的結果。能做到這點,周圍的人就可以放心與自己合作了。
- 另外一方面是對自己負責,永遠要記得不管做什麼決定,承擔結果的是自己。不管是想要加班做事情、針對某個問題作深入鑽研、隱藏遇到的問題裝做表面一片和諧,其實都無妨,只要能夠接受最終結果就好。既然都已經是成年人了,就不要想著拿盡所有好處而且可以逃避責任。以職業生涯來說,選擇自己的去留也是同樣的道理,如果放棄了現在的位置,那就別未來才後悔失去了許多福利,如果選擇留著,那也別再抱怨沒有新的成長,一切都是在於自己的選擇。
不過老實說,上面的分享也只適用於想不斷提升自己的情況,但是人生是有很多面向的,我也曾經看過有人工作只出五分力,剩下的時間都是專注在自己的生活品質上面。這並沒有什麼不好,甚至如果以長遠來看,他說不定活得還比認真努力打拼的人更快樂。反正,最重要的還是要記得人生是自己的,做什麼決定都沒關係,只要肯承擔後果就好。
]]>
@@ -231,7 +256,7 @@
http://evshary.com/2018/12/02/IPython-Notebook-Jupyter%E6%95%99%E5%AD%B8/
2018-12-02T22:03:13.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介Jupyter Notebook,過去被稱為ipython notebook,是ipython內的強大工具。
Jupyter最常用在學習資料處理上面,因為輸入指令後就可以產生相對應的圖形結果,做到資料視覺化的功能。而且更重要的是我們可以將自己的結果輸出成html或上傳Github,分享給其他人進行討論。
安裝
MAC
如果有安裝python-pip了,可以直接用如下指令安裝。要是遇到權限問題可以再加上sudo。
1
| pip install "ipython[notebook]"
|
使用
基本操作
- 創造一個資料夾,然後在裡面開啟jupyter notebook
1
2
3
| mkdir ipython_notebook && cd ipython_notebook
jupyter notebook
|
1
| jupyter notebook --port 8080
|
接下來在web上應該可以直接連線Jupyter。
選擇New->python3後就可以在web新創一個notebook,值得注意的是這個notebook的副檔名是.ipynb,存放位置就是在我們當前的目錄,也就是ipython_notebook
登入機制
jupyter notebook其實是有登出機制的,在右上角logout後,就要用密碼或token才能登入。
這時候其實可以直接重啟server,或是輸入jupyter notebook list來查看token,就可以再次登入了。
編輯方式
在Jupyter中,進入notebook後會看到一個可以輸入值的空間,這個叫做cell。cell上面輸入python語法後,按下shift+enter就會產生執行結果。而我們可以增加或減少這些cell。
特別注意原本cell是藍色的,代表在command mode,但是如果點選cell後就會變成綠色,代表進入edit mode。從edit mode跳回command mode只要按下ESC即可。
另外可以注意每個cell可以選擇不同屬性,最常用的還是Code和Markdown。Code就是python的部分,而Markdown則是可以寫上相關的文字敘述。
常用快捷鍵
主要可以點選Help->Keyboard Shortcuts來看目前快速鍵怎麼使用(或是按ESC+h更快)
常用快速鍵如下所示:
c:複製當前的cellx:剪下當前的cellv:貼上剪貼簿的celldd:刪除當前cella:在上方插入新的cellb:在下方插入新的cellshift+enter:執行當前cell並跳到下一個cellctrl+enter:執行當前cellshift+tab:可以顯示當前函式的使用方法
分享
我們除了可以把當前notebook下載成html外,也可以push到Github上並且利用nbviewer這個網站來分享。
舉個例子,A gallery of interesting Jupyter Notebooks就收集了不少有趣的Juypter Notebook範例。
只要有ipynb上傳到Github,我們就可以看到輸出結果,就像這個GitHub的結果可以被nbviewer顯示出來。
參考
]]>
@@ -258,7 +283,7 @@
http://evshary.com/2018/12/02/ARM-CortexM3-4%E6%AC%8A%E9%99%90%E5%88%87%E6%8F%9B/
2018-12-02T15:04:44.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介最近我在研究怎麼在ARM Cortex M3/4上面跑一個自己寫的OS,最主要是參考jserv的mini-arm-os和pikoRT,相關程式碼放在arm-os-4fun。
最近發現自己遇到了些問題,想說再研究怎麼解決的過程中順便把細節紀錄下,供自己未來可以參考。
這邊首先要探討的是Cortex M3/4上面有的權限模式,以及它們是怎麼進行切換等細節。
原本我是在qemu上面跑STM32虛擬機,但是後來發現好像跟真實硬體有點不一致,所以後來我都在STM32F429的硬體上面來測試了。
Cortex M權限設計
首先我們先了解Cortex上面有哪些權限模式,處理器上面有兩種Operation Modes:Thread mode和Handler mode。
- Thread Mode:一般程式運行的狀態。
- Handler Mode:處理exception的狀態。
然而除了這個以外,還有不同的Privilege Levels,避免一般使用者可以存取敏感資源。
- Privileged:可以存取所有資源,在CPU reset之後就是privileged。
- Unprivileged:通常是讓OS中userspace的程式運行用的,在幾個方面存取資源是受限的。
- MSR、MRS指令存取上會有限制。
- 無法存取system timer、NVIC。
- 有些memory無法存取。
Operation Modes和Privilege Levels的關係如下所示,Unprivileged不能進入Handler Mode的。
| - | Privileged Level | Unprivileged Level |
|---|
| Handler Mode | O(state1) | X |
| Thread Mode | O(state2) | O(state3) |
- 上面標註的state 1-3是為了方便我們後面講解而標的。
如何切換權限與模式
關於切換的部分可參考下圖,圖片來源A tour of the Cortex-M3 Core
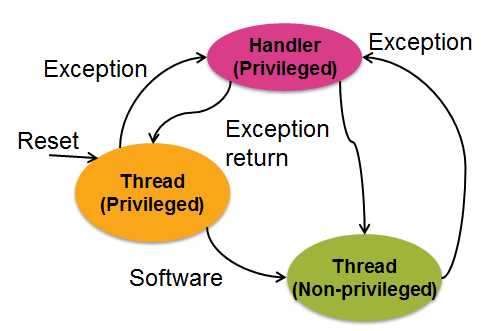
下面我們先看怎麼樣從state2,state3進入state1,也就是發生exception,然後再從state1回來。
Exception Entry
進入exception有兩種情況:
- 目前我們在thread mode
- preempts:發生的exception比目前我們所在的exception權限還高
發生exception時,ARM會自動把當前的register的資訊存起來,順序為xPSR, PC, LR, R12, R3, R2, R1, R0。儲存的方式就是push到當前的stack中,可能是main stack(SP=MSP),也可能是process stack(SP=PSP)。
| address | register |
|---|
| SP+00 | R0 <- SP after exception |
| SP+0x04 | R1 |
| SP+0x08 | R2 |
| SP+0x0C | R3 |
| SP+0x10 | R12 |
| SP+0x14 | LR |
| SP+0x18 | PC |
| SP+0x1C | xPSR |
| SP+0x20 | xxx <- SP before exception |
完成後接著會開始執行exception handler,並且把EXC_RETURN寫入LR。
Exception Return
要從exception跳還必須要符合兩個條件:
- 目前正在Handler Mode。
- PC的值是合法的EXC_RETURN。
關於EXC_RETURN的值,其實代表了ARM從handler mode回去的路徑,有三種可能:
- 目前是nested exception,回去上層還是handler mode。
- 是由privileged thread mode呼叫的,也就是要回到state2。
- 是由unprivileged thread mode呼叫的,也就是要回到state3。
因此EXC_RETURN有三個可能的值
| EXC_RETURN | Description |
|---|
| 0xFFFFFFF1 | Return to Handler mode.
Exception return gets state from the main stack.
Execution uses MSP after return. |
| 0xFFFFFFF9 | Return to Thread mode.
Exception Return get state from the main stack.
Execution uses MSP after return. |
| 0xFFFFFFFD | Return to Thread mode.
Exception return gets state from the process stack.
Execution uses PSP after return. |
Privileged to Unprivileged
接著我們要來探討怎麼從Privileged進入Unprivileged,也就是state2進入state3的部分。
如果要進入Unprivileged,那必須使用到特殊register - control。
| bit | Description |
|---|
| CONTROL[1] | 0:Use MSP, 1: Use PSP |
| CONTROL[0] | 0:Privileged thread mode, 1:Unprivileged thread mode |
要特別注意操作control register一定要用MRS和MSR register
1
2
3
4
| # CONTROL值搬到R0
MRS R0, CONTROL
# R0的值放入CONTROL
MSR CONTROL, R0
|
進入Unprivileged Thread Mode的操作
1
2
| MOV R0, 3
MSR CONTROL, R0
|
ARM在切換上面的設計
ARM在處理nested exception上有自己的一套做法來加快速度,確保高優先權的exception能更快被執行到,達到更高的即時性(real-time)。
下面介紹兩種在Cortex M上面的機制:
- tail-chained:
- 情況:如果發生exception1的時候又發生exception2,但是exception2的優先權沒有高於exception1,必須等待。
- 原本:一般來說exception1結束的時候會先pop stack,然後再push stack進入處理exception2。
- 改進:exception1到exception2中間的pop&push其實是沒意義的,所以ARM Cortex M會在exception1結束後直接執行exception2,減少了中間的浪費。
- late-arriving
- 情況:如果發生exception1並且執行state saving(上面說的push register),這時候有更高優先權的exception2進來,發生preempts。
- 原本:會中斷exception1的state saving,優先讓給exception2。
- 改進:exception2其實也是需要state saving,所以繼續維持state saving,然後直接執行exception2。當exception2結束後,就又可以使用tail-chained的模式來執行exception1。
參考
關於Cortex M相關的資料非常推薦下面兩本書籍,都有中文的翻譯。JosephYiu有參與ARM Cortex M的設計,比較有權威性。
可參考jserv老師和學生撰寫的rtenv+簡介,裡面也有提到ARM CM3權限的部分。
]]>
@@ -285,7 +310,7 @@
http://evshary.com/2018/12/02/gnuplot%EF%BC%9A%E5%A0%B1%E5%91%8A%E5%BF%85%E5%82%99%E7%9A%84%E7%B9%AA%E5%9C%96%E5%B7%A5%E5%85%B7/
2018-12-02T10:15:18.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介當我們要製作報告或論文的圖表時,除了excel以外,其實也可以使用gnuplot這套工具。gnuplot非常的強大,除了可以畫各種圖表以外,還可以跨不同平台使用。
我們這邊簡單紀錄一些常用圖表怎麼繪畫。
安裝
MAC
如果我們要正常顯示圖表的話需要有x11,這部分可以安裝APPLE的XQuartz即可,這樣啟動gnuplot的時候就會自動啟動XQuartz了,可參考Can’t plot with gnuplot on my Mac
接下來安裝gnuplot的時候要特別注意,如果沒有加上--with-x11的話,可能會造成Terminal type set to 'unknown'的warning,可參考Can’t find x11 terminal in gnuplot Octave on Mac OS
1
| brew install gnuplot --with-x11
|
使用
基本操作
1
2
3
4
5
6
7
8
9
10
|
gnuplot
plot sin(x)
plot [x=-10:10] [0:2] cos(x)
reset
exit
|
讀取檔案
我們可以把多筆資料先存成檔案,然後再讓gnuplot來讀
我們先存資料到data.txt,中間用空格隔開
執行gnuplot就會看到有許多一點一點資料散佈在plot上
如果要開啟多個檔案
1
| plot "data1.txt", "data2.txt", "data3.txt"
|
存成程式
每次都要自己一個個輸入指令說實在太麻煩了,我們可以存成.plt檔,以下面為例存成plot.plt
進入gnuplot後輸入如下指令即可
圖表上的文字
圖表上面總是要有些文字說明,可參考如下設定
1
2
3
4
5
6
7
8
9
10
11
12
|
set title "pic_title"
set xlabel "x(unit)"
set ylabel "y(unit)"
set key box
set nokey
plot "data1.txt" title "title 1", "data2.txt" title "title 2"
|
圖表的顯示
也許我們會想改變圖表上面的顯示
1
2
3
4
5
6
7
8
9
10
|
set grid
set style data lines
set xrange [-10:10]
set yrange [-10:10]
set xtics x: 每次x軸都增加x
|
plot上其實也可以做一些操作
1
2
3
4
5
6
7
8
|
plot "data.txt" with lines linestyle 1 linewidth 1
plot "data.txt" with point pointtype 1 pointsize 1
plot "data.txt" with linespoints
plot "data.txt" with boxes
|
儲存成圖片
1
2
3
4
5
6
7
8
9
10
|
set terminal png
set terminal png size 1200,800
set output "output.png"
plot .....
set terminal x11
|
常用
- 折線圖
- 先產生出data.txt
- 使用在gnuplot中load如下plt檔
1
2
3
4
5
6
7
| reset
set title "pic_title"
set xlabel "x(unit)"
set ylabel "y(unit)"
set terminal png
set output "output.png"
plot "data.txt" with linespoints title "title 1"
|
- 長條圖
- 先產生出data.txt
- 使用在gnuplot中load如下plt檔
1
2
3
4
5
6
7
8
9
| reset
set title "pic_title"
set xlabel "x(unit)"
set ylabel "y(unit)"
set terminal png
set output "output.png"
set boxwidth 0.3
plot "data.txt" with boxes title "title 1"
|
參考
]]>
@@ -312,7 +337,7 @@
http://evshary.com/2018/12/01/ffmpeg%E5%BD%B1%E9%9F%B3%E8%99%95%E7%90%86%E5%B7%A5%E5%85%B7/
2018-12-01T10:16:12.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介有時候需要對影片、音樂做各種處理,例如轉檔、切割等等,這時候可以使用很強大的影音處理神器ffmpeg來做這些操作。
這邊不會細談調整編碼等細節,只是記錄日常常用到的操作指令而已。
安裝
MAC
使用
轉檔
-f代表format
1
| ffmpeg -i [要轉的檔案] -f [目標格式] [輸出檔名]
|
有哪些格式可選可用如下指令
裁減影片
-ss代表從何時開始,-t代表維持時間,-to代表停止的時間
1
2
3
4
|
ffmpeg -i [要轉的檔案] -ss 00:00:05 -t 00:00:30 [輸出檔名]
ffmpeg -i [要轉的檔案] -ss 00:00:05 -to 00:00:25 [輸出檔名]
|
顛倒影像
-vf代表vedio filter,可以讓影片經過處理,轉換影片角度有下面三種常用
- hflip:水平翻轉
- vflip:垂直翻轉
- transpose=1:順時針轉90度
1
2
3
4
5
6
7
8
|
ffmpeg -i [要轉的檔案] -vf hflip [輸出檔名]
ffmpeg -i [要轉的檔案] -vf vflip [輸出檔名]
ffmpeg -i [要轉的檔案] -vf transpose=1 [輸出檔名]
ffmpeg -i [要轉的檔案] -vf transpose=2 [輸出檔名]
|
影片截圖
-an代表不需要聲音,-vframes代表要抓幾張圖,-r代表每秒抓幾張圖
1
2
3
4
5
| ffmpeg -i [要轉的檔案] -an -ss [抓取時間] -vframes [幾張圖] -r [幾張圖] [輸出圖檔]
ffmpeg -i [要轉的檔案] -an -ss 00:00:00 -vframes 1 cover.jpg
ffmpeg -i [要轉的檔案] -an -ss 00:00:00 -vframes 1 -r 0.1 tmp-%d.jpg
|
調整音量大小
-vol代表聲音大小,256是正常
1
| ffmpeg -i [要轉的檔案] -n [聲音大小] [輸出檔名]
|
播放影音
在ffmpeg內有一個tool是ffplay,可以簡單用來播放影音
雖然沒有進度條,但是如果按著右鍵左右移動也會有進度條的效果
1
| ffplay -loop [次數] [影片名稱]
|
常用
影片轉音樂
1
| ffmpeg -i [要轉的檔案] -f mp3 [輸出檔名]
|
轉換成mp4
1
| ffmpeg -i [要轉的檔案] -f mp4 [輸出檔名]
|
裁減影片
1
| ffmpeg -i [要轉的檔案] -ss [開始時間] -to [結束時間] [輸出檔名]
|
抓截圖
1
| ffmpeg -i [要轉的檔案] -an -ss 00:00:00 -vframes 1 cover.jpg
|
聲音調整
1
2
3
4
|
ffmpeg -i [要轉的檔案] -vol 300 [輸出檔名]
ffmpeg -i [要轉的檔案] -vol 200 [輸出檔名]
|
手機拍攝如果是反的情況
1
2
3
4
|
ffmpeg -i [要轉的檔案] -vf transpose=1 [輸出檔名]
ffmpeg -i [要轉的檔案] -vf transpose=2 [輸出檔名]
|
參考
]]>
@@ -339,7 +364,7 @@
http://evshary.com/2018/11/25/dd-%E8%B3%87%E6%96%99%E8%99%95%E7%90%86%E7%9A%84%E5%A5%BD%E5%B7%A5%E5%85%B7/
2018-11-25T18:27:45.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介dd全名叫做data duplicator,這個工具最主要的功能是對資料作複製、修改、備份,是一個很方便的小工具。通常Linux中預設都會有,不需要額外安裝。
使用教學
基本
1
| dd if=[input_file] of=[output_file]
|
轉換
- 做相對應的轉換
conv=CONVS- lcase:大寫字母換小寫
- ucase:小寫字母換大寫
- nocreat:不要建立輸出檔案
- notrunc:input小於output時,仍維持output大小
- fdatasync:讓資料同步寫入硬碟
1
2
|
dd if=[input_file] of=[output_file] conv=lcase
|
區塊
- bs=[bytes]:等同於同時設定ibs和obs,一次讀或寫的block size。
- ibs=[bytes]:指定每次讀取的block size(default 512 bytes)
- obs=[bytes]:指定每次寫入的block size(default 512 bytes)
- count=[number]:只處理前[number]輸入區塊,block size要參考ibs。
- seek=[number]:輸出檔案跳過前[number]個區塊,block size要參考obs。
- skip=[number]:輸入檔案跳過前[number]個區塊,block size要參考ibs。
常用指令
參考
]]>
@@ -366,7 +391,7 @@
http://evshary.com/2018/11/25/youtube-dl%E7%B6%B2%E8%B7%AF%E5%BD%B1%E7%89%87%E4%B8%8B%E8%BC%89%E5%99%A8/
2018-11-25T11:38:01.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介當我們要下載網路影片時,通常會去使用browser上的套件來下載,其實除了browser套件外,我們也可以使用command-line的方式,也就是這篇要介紹的youtube-dl。
youtube-dl功能十分強大,也有很多參數可以調整,能下載的網站不只是youtube,也可以是其他熱門網站,例如Facebook等等,更重要的是這個工具有多個平台可以使用(Windows、Mac、Linux)。
除了指令youtube-dl以外,我們也可以用GUI的介面的工具youtube-DLG,使用上更為方便,詳請可參考最強的網路影片下載器 Youtube-dl-gui 只要有網址就能幫你搞定。
安裝
MAC
1
2
3
| brew install youtube-dl
brew install ffmpeg
|
Ubuntu
1
2
3
| sudo apt-get install youtube-dl
sudo apt-get install ffmpeg
|
Python
其實更好的方法是使用Python的pip來安裝,因為youtube-dl本身就是使用Python所寫成的,而由於影片的網站更新很快,所以可能要隨時更新到最新版的youtube-dl才行,OS distribution不一定會出的那麼快。
1
2
3
| pip install --upgrade youtube_dl
pip3 install --upgrade youtube_dl
|
使用
這邊介紹一些常用的指令
支援
- 確定有支援下載哪些影片網站,相關列表也可以從官網查詢
1
| youtube-dl --extractor-descriptions
|
格式
如果我們沒有指定格式的話,通常youtube-dl會幫我們挑最好的
1
2
3
4
5
6
|
youtube-dl -F [URL]
youtube-dl -f mp4 [URL]
youtube-dl -f [列表中的format code] [URL]
|
輸出格式
由於官方的輸出格式預設有帶ID(%(title)s-%(id)s.%(ext)s),我們可以將其去除
1
| youtube-dl -o '%(title)s.%(ext)s' [URL]
|
字幕
- 選擇嵌入特定字幕
--write-sub代表下載字幕--embed-sub代表嵌入字幕--sub-lang代表要選擇的字幕
1
2
3
4
|
youtube-dl --list-subs [URL]
youtube-dl --write-sub --embed-sub --sub-lang [字幕] [URL]
|
1
| youtube-dl --write-sub --embed-sub --all-subs [URL]
|
轉為音樂格式
如果我們要下載音樂格式的話,基本上需要有ffmpeg的輔助
- 選擇要下載的音樂格式,例如mp3、m4a、flac等等
1
| youtube-dl -x --audio-format [音樂格式] [URL]
|
- 可以用
--audio-quality強迫ffmpeg轉換較高品質的音樂,0是最好,9是最差
1
| youtube-dl -x --audio-format [音樂格式] --audio-quality [音樂品質] [URL]
|
- 下載時附上封面(使用youtube截圖)和音樂資訊(作曲者等等)
1
| youtube-dl -x --audio-format [音樂格式] --embed-thumbnail --add-metadata [URL]
|
下載播放清單
- 其實只要把[URL]換成播放清單的網址即可,不過我們也可以指定開始和結束位址
--playlist-start:開始--playlist-end:結束,也就是倒數第幾個影片
1
| youtube-dl --playlist-start [開始位置] --playlist-end [結束位置] [URL]
|
常用
我這邊直接列出常用的指令,如果要使用可以直接copy比較快
1
| youtube-dl -f mp4 --write-sub --embed-sub --all-subs -o '%(title)s.%(ext)s' [URL]
|
1
| youtube-dl -x --audio-format mp3 --audio-quality 0 --embed-thumbnail --add-metadata [URL]
|
參考
]]>
@@ -393,7 +418,7 @@
http://evshary.com/2018/10/21/%E8%A2%AB%E8%A8%8E%E5%8E%AD%E7%9A%84%E5%8B%87%E6%B0%A3/
2018-10-21T10:02:38.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介這篇想要介紹的是「被討厭的勇氣」這本書,書中用哲學家和年輕人用對話方式來闡述阿德勒心理學。由於阿德勒心理學跟較廣為人知的佛洛伊德心理學相比更冷門一點,所以很多想法都給現代人帶來啟發,也因此廣受歡迎。
這系列書分為兩集,上集是對阿德勒心理學有個綜觀認識,而下集則是因為讀者有回饋不少意見而針對這些疑問的回答。個人認為下集比較偏向怎麼去實踐方面,其中幾乎有八成是在講教育部分。雖然我覺得一般人如何去實踐部分較少有點可惜,但是對諮商師、教師來說可能極具價值吧!
其實書中討論的阿德勒心理學範圍還蠻廣的,原本我想嘗試用整體架構來分析,但是發現可能以目前所掌握的相關知識不足以做這樣的評論,所以我改成會針對幾點比較有收穫的概念來介紹。
目的論
目的論其實是這本書很重要的精華,反對了宿命論,強調了人類可以自我改變的能力。我們常常太過注重因果關係了,「因為過去發生怎樣怎樣,所以現在的我才變成這樣」或是「都是因為他先怎樣怎樣,我才會這樣」。雖然某種層面上可能是對的,但是更可能的是這些都只是藉口,因為我們並非受制過去原因而行動,而是朝向自己決定好的目的而行動。換句話說,自己之所以不幸,完全是自己親手所選擇的。
這個概念很重要,如果強調因果論,那代表的是現在的我是無法改變的,因為過去是無法改變的,這是宿命。然而將其想成是我們為了什麼目的才變成現在的自己,那隱含的意思是只要改變了目的,現在的自己也會跟著改變。不是因為過去的經驗形塑了現在的我,而是我去賦予過去經驗什麼意義來解釋自己的人生。由此可知,重要的不是經歷了什麼,而是如何去運用它。
我們在生活中常常會對現狀不滿,這時候就會去找理由,都是因為環境、過去等等什麼原因導致自己這樣的。但是如果用目的理論來看,我們可能是「不想去改變」而去找理由。雖然現狀令人不滿,但是改變更加痛苦,為了不去改變,我們必須要有可以歸罪的理由。說直白一點,我們是因為缺乏「改變的勇氣」,所以寧可選擇了不幸的現狀。
在目的論下,一切的理由都是藉口,當前現況完全是自己所選擇的。在下集有提到一個三角柱的概念,我們跟親人、朋友常常會抱怨誰誰誰很可惡,自己很可憐,這也就是三角柱其中兩面,「可惡的他」和「可憐的我」,但是更為重要的是第三面「今後該怎麼辦」。不斷地找理由不會改變現況,要專注於自己能改變的事情上面。
老實說,目的論真的蠻殘酷的,我們為了讓自己好過一點,感性上會想逃避自己的責任,去抱怨外在的環境,但是就現實與邏輯而言,如果真的要改變現狀,那就得承擔起自己應負的責任,並找出改變的方法。「責任」與「勇氣」說起來容易,但是當想到要用在自己身上時,才真正感受到其重量。
逃離競爭關係
阿德勒説:「一切的煩惱都是人際關係的煩惱」。雖然有點極端,不過確實人類的煩惱大多數是來自人際關係。其中對我而言,最常見的煩惱是怕自己輸給別人。人類與身俱來就有「追求卓越」的慾望,想奮發向上,但是一旦理想無法達成時,就會有產生自己低劣無能的「自卑感」。
在當前社會上,其實都會有「競爭」的關係,在學校時是同學,在公司時是同事,會害怕自己輸給別人,擔心自己可能會輸,因此要不斷贏下去。儘管這種方式可以不斷促進自己進步,但也導致看到別人成功幸福時,會無法發自內心地去祝福,甚至更惡劣的,看到別人不幸會覺得可以證明自己的成功。
其實我從求學階段就或多或少發現自己也有這樣的心態,不斷去比較自己與同儕間。然而競爭是一個無限循環,我打敗了一群人,還有更厲害的人在等著,就算我打敗所有人站在巔峰,還是會時時擔心自己會輸,不斷去維持自己的地位,這也意味著永遠得不到幸福。如果我們真的想獲得幸福,必須要脫離競爭模式,放棄比較。
目前的我會把人生當做擁有一筆錢可以隨意去買自己想要的東西,如果去比較我買的東西跟別人比起來有沒有比較大、比較好,那並不會得到快樂。不如專心在選擇自己要買哪些東西,我想要買的東西組合肯定跟別人不一樣,也無從比較起,重點是買到的東西能不能帶給我快樂,而不是比別人還要好。
課題的切割
其實從上面提到的目的論可以看出,阿德勒心理學很重視可控制這件事,因為可控這件事對人類而言十分重要,甚至有研究指出會影響到健康。如果用目的論來看,那代表人生是可控制的,我們能去改變。然而事實上人生還是有很多層面是不能控制的,特別是人與人關係,我沒辦法掌握別人怎麼想,如果不能控制,那就會造成自己的不安,對幸福人生來說是種破壞。
關於這點,阿德勒提出了「課題切割」,劃清界線,這件事從哪邊開始是自己的課題,哪邊是別人的,最簡單的區分方式是思考「因為這個決定而帶來的結果,最後會由誰來承受?」。切割課題後,不去介入他人課題,也不讓他人介入自己的課題。介入他人的課題會背負他人的人生,而讓他人介入自己的課題則會讓自己左右為難,就像父子騎驢的故事,不管自己怎麼做,都有人會不滿意的。
課題切割最高明的點在於確認了什麼是自己可控,什麼不是。我們只要專注在自己能改變的事情上,其他則不用太在意。按照書中的說法,這個就是人際關係的王牌,因為主動權在我手上,不用在意他人想法。
也許會有人認為這樣會很招人厭惡,不太能夠做到。然而不這麼做,將會讓自己的人生變得很被動,因為要不斷去迎合別人。這邊也帶出了本書的書名,為了行使自由,讓自己依照自己的生活方針過日子,必須要能接受別人的討厭,因此需要擁有被討厭的勇氣。
建立橫向關係
人際關係有分為橫向和縱向,阿德勒心理學否定一切的「縱向關係」,提倡所有的人際關係都應該是「橫向關係」。縱向關係帶來的是稱讚、責罵,然而橫向關係帶來的是尊敬、感謝。
我會特別把這點拿出來提的原因是書中有舉一個很有趣的例子:假設你遵從上司的指示,結果卻因此面臨工作上的挫敗,這應該是誰的責任?如果是縱向關係的人就會認為是上司的責任,因為是上司的指示,然而這個卻是隱含著自己逃避了責任、閃避複雜的人際關係,因為不用思考太過困難的事、不必為失敗負責,所以仰賴他人的指示過日子。對於橫向關係的人來說,應該要拒絕並提出更好的方案,工作成敗是自己要負責的,沒有任何理由推託。其實在工作上還蠻常遇到為了避免麻煩,把問題交給別人決定的情況,讓別人決定別人負責,但是真正負責任的做法也許是自己也提出想法,然後再與別人共同討論並共識出較好的做法。
除了對上關係外,對下也是「縱向關係」的一種,像是對孩童的讚賞或責罵。阿德勒很尖銳地指出,大人說對孩子好而去責罵通常不是真正為了小孩好,而是因為小孩犯錯隱含著大人有教育失敗的責任,而為了自己不要被批評,所以想要控制他照著自己的想法走。然而教育是為了讓孩子能夠自立,我們只能從旁提供協助,就算是失敗也是要由自己去負起責任。有點像是學習騎腳踏車,真正騎車的人是小孩自己,跌倒也必須是自己去承擔,但我們可以提供他建議和方法,如果怕小孩受傷而不放手,那他就永遠學不會騎車,只能不斷依賴我們。這跟教育有關的部分目前我大概只有這樣的了解,也許未來有小孩之後可能會有更多的體悟吧!
活在當下
「活在當下」這句話大部分的人都聽膩了,幾乎都變成是一個政治正確的口號,不過這邊我想提提阿德勒對活在當下的看法。本書用旅遊來比喻人生,出去旅遊絕對不是到達目的才叫旅行,如果是這樣我們就用最快的方式飛到目的地,然後再快速返回不就達成目標了?從自己踏出家門的那一刻起,就已經稱作旅行,旅行的概念是在到達目的前的每個瞬間,認真享受每個瞬間才是旅行的目的。
同理人生也一樣,人生就像是登山攻頂的活動,有大半時間都在半路上,如果不能認真對待這個過程,只期待登頂的那個瞬間,那不就代表人生有一大半是沒有價值的?對我而言,常常也會期待未來會變得更好,希望「當下」趕快過去,只要我做完什麼事情人生就會不一樣了,像是學生時期要準備大考、工作時要面對大案子等等。可是再回過頭來想,面對困難挑戰永遠只想說熬過去人生會更好,好像完全沒有真正更好過,因為我只有完成挑戰那一瞬間獲得解脫的快樂,但很快又會有下一個挑戰。與其自己只能在這樣的痛苦中不斷輪迴,不如專心面對當下每個瞬間。
關於活在當下,其實也是呼應了前面目的論的看法。「人生是一連串的剎那,過去和未來都不存在,別想要藉著回顧過去、預見未來,給自己一個免除責任的藉口。」由於自己真正擁有的是現在,如果用過去當做藉口,就意味著放棄了現在所擁有的選擇權。當自己想把現在的不如意推給過去,或是期盼未來會更好時,都要注意是不是根本沒有活在現在,應該要認真做當下自己所能做改變的事情。
評價
以書寫手法來說,兩本書的結尾基本上是年輕人被哲學家說服,受到感動想去嘗試阿德勒心理學,說實在這有點讓人覺得矯情,我覺得其實不用用這種傳教意味濃厚的結尾也不會讓書的價值打折扣,不太清楚為什麼用這種想煽動人心的結尾。
另外,很多觀念在對話中並沒辦法越辯越明,個人認為講不夠詳細、邏輯不夠清楚的地方還蠻多的。舉個例子,書中有提到要無條件相信別人,但下集又提到相信不是照單全收,對於對方的思想信念要持懷疑態度,如果我都對人產生懷疑了,還稱得上是信任嗎?這裡作者沒有做更詳細的解釋。當然這可能也是對話方式的書籍所受限之處,畢竟對話類型的書比起理論類型更能讓一般人接受,但對話勢必要省略比較細節的內容了。
看完上下兩集後,我認為如果是要把阿德勒心理學當作是自己的人生觀,還有太多需要釐清之處了,而且這也會有洗腦之嫌。然而不可否認,他在百年前提出的這些思想確實有其高明之處,簡而有力地戳破我們不敢面對的一面,這些部分可以再好好理解並且善用在生活中。我們可以利用前人的思想來形塑自己的人生觀,但是不要只是照本宣科去執行,這樣就跟下集一開始的年輕人一樣會陷入苦惱之中了。
如果認為完完全全照著某個理論做就可以得到幸福,那其實不也是逃避負責任,缺乏真正去面對自己人生的勇氣呢?
]]>
@@ -420,7 +445,7 @@
http://evshary.com/2018/10/14/GnuPG%E6%95%99%E5%AD%B8/
2018-10-14T11:37:34.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介GPG全名為Gnu Privacy Guard(GnuPG) ,最初的目的是為了加密通訊的加密軟體,是為了替代PGP並符合GPL而產生的。目前很多自由軟體社群要驗證身份也都會需要用到這套工具。
使用
安裝
1
2
3
4
|
sudo apt-get install gnupg
brew install gnupg
|
- GUI
- 其實現在GUI介面都做得很好看了,而且也很容易上手,建議可以用GUI的tools。
- MAC的GUI tools可從gpgtools.org安裝
建立key
先產生key
- 可選擇”RSA & RSA”,key長度為4096
- 真實姓名就填自己的英文名字,備註可填中文
- 產生的key會放在
~/.gnupg這個目錄下 - 記得要輸入密碼,防止別人入侵系統時可以直接拿到私鑰
- 最後會產生出user ID的hash(UID)
1
2
3
| gpg --full-generate-key
gpgconf --kill gpg-agent
|
接下來就是產生撤銷憑證,未來忘記密碼可以用來撤銷,因此要小心保管
- 注意如果key有填utf-8,這步在MAC可能會出問題,不過如果是用GUI卻沒問題,原因並不清楚。
1
2
3
| gpg -o revocation.crt --gen-revoke [UID]
gpg --gen-revoke [UID] > ~/.gnupg/revocation-[UID].crt
|
釋出公鑰,這個公鑰可以傳給朋友,或是上傳到server
1
| gpg -ao mypublic.asc --export [UID]
|
如果是要把朋友的公鑰放入已知道人的清單
1
| gpg --import friends.asc
|
可以用fingerprint顯示自已的公鑰後,弄到pdf上印出
1
| gpg -v --fingerprint [UID]
|
管理key
查看、編輯與刪除key
查看目前的鑰匙
1
2
3
4
5
6
|
gpg --list-keys
gpg --list-sigs
gpg --list-secret-keys
|
編輯key(對key簽名也是用同樣的方法)
刪除已存入key的方式,如果有私鑰要先刪除
1
2
3
4
|
gpg --delete-secret-key [UID]
gpg --delete-key [UID]
|
搜尋
首先先搜尋對象的public key
- 這裡指定的key server是用MIT的,可以找其他也有公信力的Server,可參考wiki
1
| gpg --keyserver hkp://pgp.mit.edu --search-keys 'Linus Torvalds'
|
得到對方的public key後,將其存入~/.gnupg/pubring.gpg
1
| gpg --keyserver hkp://pgp.mit.edu --recv-keys 79BE3E4300411886
|
可查看與更新朋友的public key
1
2
| gpg --list-keys
gpg --refresh-keys
|
import/export
除了搜尋以外,也可以用import/export的方式管理朋友的公鑰
1
2
| gpg --import public_keys_list.txt
gpg --export -ao public_keys_list.txt
|
import/export自己的金鑰
1
2
3
4
5
6
|
gpg --armor --output public-key.asc --export [UID]
gpg --armor --output private-key.asc --export-secret-keys [UID]
gpg --import [金鑰]
|
用key傳送接收信件
假設我們要傳送secret.tgz給朋友,可以先進行加密
1
| gpg -ear 朋友 < secret.tgz > secret.tgz.asc
|
朋友收到secret.tgz.asc後可用如下指令變回secret.tgz
1
| gpg -d < secret.tgz.asc > secret.tgz
|
如果要確認發信人身份
1
2
3
4
|
gpg --clearsign file.txt
gpg --verify < file.txt.asc
|
參考
]]>
@@ -449,7 +474,7 @@
http://evshary.com/2018/07/04/%E8%BB%9F%E6%8A%80%E8%83%BD%EF%BC%9A%E4%BB%A3%E7%A2%BC%E4%B9%8B%E5%A4%96%E7%9A%84%E7%94%9F%E5%AD%98%E6%8C%87%E5%8D%97/
2018-07-04T21:18:29.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
今天想要來介紹一本對軟體工程師來說很棒的書,叫做軟技能:代碼之外的生存指南 (Soft Skills : The software developer’s life manual)。最一開始會關注到這本書是因為有人介紹說這本書堪稱是軟體界的「原則」。由於對「原則」有還不錯的評價,所以就有了閱讀的興趣。這本書號稱是給軟體工程師看的書,但是裡面卻沒有任何一行程式碼,作者希望告訴讀者的是要成好的軟體工程師,不能只專注在專業上,要把重點放在「整個人」上。書中分享了如何找工作、自我營銷、自我學習等等,甚至還有理財、健身和愛情。同樣身為軟體工程師,我認為可以從前人身上觀察和學習他的經驗應該是蠻有幫助的,因此下面會分享幾個從書中學到比較重要的概念。第一個是就算是受聘於公司,也應該要當作自己是在經營生意。只有把「我」當成是一家公司看待,才能做出好的商業決策。在一般公司朝九晚六(如果沒加班的話)的生活,很容易把個人的思維限制住,認為就是把固定事情做好然後領固定的薪水。然而,如果從經濟學的角度來看,其實我們都是在販賣服務並且獲取報酬,只是販賣的對象是固定某個客戶而已。當可以用比較宏觀的角度看待工作的時候,就會發現可以選擇的策略比想像中多很多,例如開始評估自己所提供的服務和價錢跟當前市場狀況是否有吻合,不吻合的話就會進一步精進服務的內容(提升能力),或是開拓其他可能的客戶(找其他公司)。這種心態上的轉變會讓我們不會只是被動接受現況,而會有積極的思維去影響現實,獲得更好的結果。
再來關於自我行銷的方面作者也提到很多,自我行銷其實跟前面相呼應,如果要把工作當作在經營生意,怎麼讓潛在客戶知道自己就很重要。找工作最容易的方法是讓工作來找你,當別人有求於你時,就更容易得到比較好的條件。對軟體工程師來說,最好的行銷方式就是寫blog,有許多有價值的文章,自然知名度就會打開。書中強調了好幾次經營blog的重要性,然後還提到最重要的就是毅力,只要持之以恆地撰寫文章,就已經勝過大多數的同行了。雖然我本身已經有意識地在經營blog了,但是常常都只是想說留個紀錄供自己未來參考。然而作者反對這種做法,他認為如果要能吸引別人最重要的是出發點是對他人有益,如果能夠對他人產生價值,就會受到關注,因此文章不是自己寫開心就好。這對我過去寫文章的方式是一種震撼,現在開始會思考我的記錄事情的角度是否可以解決讀者遇到的問題,是否容易閱讀及理解。
在變動很快的科技業中,如何自我學習是非常重要的,特別是軟體業,沒多久就有新的framework或程式語言出現,這些技術大概很難透過學校老師教導,只能靠著自己尋找資源去學習。書中作者介紹了十步學習法,不過我不打算在這裡細部講解這個方法,取而代之,我想分享作者提到的四個自學方式循環:學習、實踐、掌握、教授。我們不應該期待自己把某個領域學完後再開始應用,要盡量在最短時間內找到必須要學會的內容,然後就去實踐,從實踐過程中一定會遇到問題,這時再回去翻資料掌握這些問題,當有一定程度的理解後,嘗試跟他人分享,確認是否真的理解。透過這樣的循環,可以幫助自己更快掌握該領域知識。其實這套方法跟之前我看過的有效自學方式很類似,例如最小必要知識架構術、費曼法,很明顯這些方法已經成為主流了。我想,不應該被傳統的學習概念(從基礎知識一步步慢慢學習)所限制,而是從應用面來學習,也就是知道自己要做到什麼,反推回去需要學習哪些知識,不但有效率,而且也更符合這個社會緊湊的腳步。
關於時間管理的部分,作者推薦用使用番茄鐘(通常代表的是工作25min後休息5min),如果不知道番茄鐘可以參考wiki的介紹。這一年下來,其實我都是用番茄鐘來管理我的時間,目前也覺得透過番茄鐘,確實可以幫助專注力,然而我卻從書中發現自己並沒有善用番茄鐘最大的威力。番茄鐘並不只是用來幫助自己提升效率的工具,更重要的是可以用來幫助時間規劃。在時間管理上,最常遇到的問題就是不知道每項工作到底要花多少時間做完,而在固定時間內,到底可以做完多少事情。這兩個問題番茄鐘都幫忙解決了,透過把一項大任務切割成番茄鐘的長度,代表的是強迫自己分割大任務變成可估算完成時間的小任務,而每個人每天可以完成多少的番茄鐘是有數量限制的,也代表我們會很清楚每天可以做多少事情,這樣規劃方式可以加強預測工作進度的準確度。另外番茄鐘帶來的另一個好處是可以更安心地進行休閒活動,大家應該會有經驗如果去玩樂會有種罪惡感想逼自己去工作,如果清楚每日能做到的番茄鐘數量,那休息享樂時就不會感到內疚,因為每天該完成的工作都已經達成了!
最後一點是關於自我弱點的方面,從小到大我們所受的教育都是要把缺點彌補起來,然而這在專業上其實是說不通的,大家應該常聽過樣樣通,樣樣鬆。與其告訴他人自己會很多東西,不如專精在比較小的領域(或是大領域中的某種應用),也許在市場上並沒有那麼多的需求,但是錄取機率則會大幅增加。不過也是有要去彌補弱點的情況,那就是該弱點會大幅影響效率時。當不知道某項技術其實可以很容易達成某件事前,可能都會很排斥去學習,但其實只要花幾個小時就能獲得很大的效益,也就是常聽到的CP值很高。然而要怎麼找到這些CP值高的技術呢?我們可以記錄每個自己沒聽過技術的遇到頻率,當遇到頻率高於一定值時,那就代表有學習的價值。舉個例子,其實我有時候看經濟新聞都會聽到A輪、B輪等等名詞,但是都一直沒動力去搞懂,結果對新聞內容都一知半解。在看本書的理財部份時,作者有做一個簡單的解釋,結果花不到半小時,就對這些常見名詞有初步認識了,也變相了加深我對經濟新聞理解,像是這種知識就很值得花時間投資。
當然這本書還有很多很有價值的內容,不過受限於篇幅,無法每個都說。如果對上面的分享心有戚戚焉的話,我想這本書應該蠻適合你。進入科技業也不過快三年而已,未來應該還有很長的職業生涯,如何好好經營是很大的課題。目前還是以多多參考前輩們的經驗以及不斷自我反省為主,找出真正適合自己的道路。
]]>
@@ -476,7 +501,7 @@
http://evshary.com/2018/06/12/Linux%E5%92%8C%E7%A8%8B%E5%BC%8F%E7%9A%84%E4%BA%92%E5%8B%95/
2018-06-12T19:37:27.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介這篇我們想要來探討 Linux 是怎麼和程式互動的,這邊包括兩個部分:Linux 如何執行程式以及程式如何讓 Linux 做系統操作。
程式如何執行main
一般要呼叫程式來執行的,我們知道的是只要在 shell 下類似./a.out的指令,程式就會執行我們程式中的 main,但是這其中的原理是什麼呢?讓我們看看到執行 main 前做了哪些事。
下面例子我們以Kernel v4.17為例
首先 shell 會 fork 一個 process,然後再呼叫 exec 系列函數把該 process 置換成指定的程式
execve 會呼叫 do_execve ,然後再呼叫 do_execveat_common,可參考fs/exec.c的1856行
1
2
3
4
5
6
7
8
| int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
|
接著do_execveat_common會讀取struct linux_binprm,並且根據檔案格式尋找適合的binary header
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
...
struct linux_binprm *bprm;
...
file = do_open_execat(fd, filename, flags);
...
retval = bprm_mm_init(bprm);
if (retval)
goto out_unmark;
bprm->argc = count(argv, MAX_ARG_STRINGS);
if ((retval = bprm->argc) < 0)
goto out;
...
retval = prepare_binprm(bprm);
...
retval = exec_binprm(bprm);
...
}
|
ELF的binary handler位在fs/binfmt_elf.c的690行,做了header確認後會load program header和設定並執行elf_interpreter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| static int load_elf_binary(struct linux_binprm *bprm)
{
...
elf_phdata = load_elf_phdrs(&loc->elf_ex, bprm->file);
...
retval = kernel_read(bprm->file, elf_interpreter,
elf_ppnt->p_filesz, &pos);
retval = flush_old_exec(bprm);
...
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
...
start_thread(regs, elf_entry, bprm->p);
...
}
|
經過Context Switch後,應該會從elf_interpreter執行,通常應該會是/lib/ld-x.x.so。ld-x.x.so的進入點是_start,最後會連結到glibc/elf/rtld.c的_dl_start,針對環境變數做處理。
- 我們常見的LD_PRELOAD也是在這邊進行處理的
當上述工作都做完後,就會進入 ELF binary 的_start,其中會呼叫 glibc 的__libc_start_main進行初始設定,最後就會呼叫main()
1
| result = main (argc, argv, __environ MAIN_AUXVEC_PARAM);
|
使用 system call
通常AP在Linux要跟kernel層互動大概只能透過system call,然而system call的使用大多數已經被包裝起來,所以幾乎不會看到,這邊我們來探討一下要怎麼在Linux直接呼叫system call。以下範例皆來自BINARY HACKS:駭客秘傳技巧一百招
syscall
最簡單的呼叫system call方法是syscall。
syscall.c
1
2
3
4
5
6
7
8
9
10
11
12
| #include <stdio.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
int ret;
ret = syscall(__NR_getpid);
printf("ret=%d pid=%d\n", ret, getpid());
return 0;
}
|
執行結果如下
1
2
3
| $ make syscall
$ ./syscall
ret=18 pid=18
|
看起來是很順利取得PID。我們可以把__NR_getpid換成其他的system call數字,也可以達到同樣效果。
int 0x80
當然我們也可以用int 0x80來做到同樣的事情,但是要注意的是這樣的效率不會比較好,可參考What is better “int 0x80” or “syscall”?
另外這個做法在x64的架構是無法被使用的,可參考What happens if you use the 32-bit int 0x80 Linux ABI in 64-bit code?
syscall2.c
1
2
3
4
5
6
7
8
9
10
11
| #include <stdio.h>
#include <sys/syscall.h>
#include <unistd.h>
int main(void)
{
int ret;
asm volatile ("int $0x80":"=a"(ret):"0"(__NR_getpid));
printf("ret=%d pid=%d\n", ret, getpid());
return 0;
}
|
sysenter
這部分也是只能在x86的平台上使用,會出現這個機制的理由是int 0x80的效率實在太差了。這邊的使用方式有點複雜,就不列出來了。
比較
這三種方式的比較簡單統整一下
syscall:現在主流,能在x64運行
int 0x80:只能在x86,效率差,已被捨棄
sysenter:只能在x86,用來替代int 0x80
詳情可以參考Linux系统调用机制int 0x80、sysenter/sysexit、syscall/sysret的原理与代码分析,寫得非常詳細。
參考
]]>
@@ -505,7 +530,7 @@
http://evshary.com/2018/06/09/gcc%E5%B8%B8%E7%94%A8%E6%93%B4%E5%85%85%E5%8A%9F%E8%83%BD/
2018-06-09T16:50:13.000Z
- 2024-10-27T09:36:44.304Z
+ 2024-11-03T13:19:38.800Z
簡介GNU gcc其實在編譯時也可以帶許多特殊功能,讓程式更佳的彈性,並帶來優化或更好debug的效益。這邊我們主要介紹兩個功能,內建函式和屬性__attribute__。
內建函式
要特別注意的是,這些內建函數是跟CPU架構息息相關,所以並不是每個平台都可以順利使用。另外就是編譯的時候不能帶上-fno-builtin選項,通常-fno-builtin是為了幫助我們確保程式的結果是如同我們所想像的樣子呈現,而不會被一些最佳化改變樣子,方便設定breakpoint和debug。
找呼叫者
首先我們先來談談找呼叫者這件事,我想大家應該都有經驗曾經發現程式死在某一行,但是卻不知道是誰呼叫的,這時候只能痛苦地去從stack反推return address。但是其實gcc內是有特殊內建函式可以幫助我們的,這邊介紹下面兩個好用函式。
void *builtin_return_address(unsigned int LEVEL):找到函式的return address是什麼,參數的LEVEL代表要往上找幾層,填0的話代表呼叫當前函式者的下一個執行指令。void *builtin_frame_address(unsigned int LEVEL):找到函式的frame pointer,參數的LEVEL代表要往上找幾層,填0的話代表呼叫當前函式者的frame pointer。
要注意的是LEVEL不能填變數,也就是編譯時必須確定該數字。
範例
我們還是透過一個簡單的例子來說明一下
test.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| #include <stdio.h>
void test3(void)
{
void *ret_addr, *frame_addr;
ret_addr = __builtin_return_address(0);
frame_addr = __builtin_frame_address(0);
printf("0: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(1);
frame_addr = __builtin_frame_address(1);
printf("1: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(2);
frame_addr = __builtin_frame_address(2);
printf("2: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(3);
frame_addr = __builtin_frame_address(3);
printf("3: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
printf("test3\n");
}
void test2(void)
{
void *ret_addr, *frame_addr;
ret_addr = __builtin_return_address(0);
frame_addr = __builtin_frame_address(0);
printf("0: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(1);
frame_addr = __builtin_frame_address(1);
printf("1: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(2);
frame_addr = __builtin_frame_address(2);
printf("2: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
printf("test2\n");
test3();
}
void test1(void)
{
void *ret_addr, *frame_addr;
ret_addr = __builtin_return_address(0);
frame_addr = __builtin_frame_address(0);
printf("0: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
ret_addr = __builtin_return_address(1);
frame_addr = __builtin_frame_address(1);
printf("1: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
printf("test1\n");
test2();
}
void test(void)
{
void *ret_addr, *frame_addr;
ret_addr = __builtin_return_address(0);
frame_addr = __builtin_frame_address(0);
printf("0: ");
printf("ret_addr=0x%x frame_addr=0x%x\n", ret_addr, frame_addr);
printf("test\n");
test1();
}
int main()
{
test();
return 0;
}
|
好,那我們來編譯並執行看看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| $ make test
$ ./test
0: ret_addr=0x4007c8 frame_addr=0x2bba8ba0
test
0: ret_addr=0x4007bc frame_addr=0x2bba8b80
1: ret_addr=0x4007c8 frame_addr=0x2bba8ba0
test1
0: ret_addr=0x40076d frame_addr=0x2bba8b60
1: ret_addr=0x4007bc frame_addr=0x2bba8b80
2: ret_addr=0x4007c8 frame_addr=0x2bba8ba0
test2
0: ret_addr=0x4006e1 frame_addr=0x2bba8b40
1: ret_addr=0x40076d frame_addr=0x2bba8b60
2: ret_addr=0x4007bc frame_addr=0x2bba8b80
3: ret_addr=0x4007c8 frame_addr=0x2bba8ba0
test3
|
可以看到每層function所對應的return address和frame address都被列出來,但是要怎麼驗證是否真的是這樣呢?我們把程式逆向一下看位置。這邊我們鎖定test1()的return address,也就是0x4007bc,應該是test()函式的呼叫test1()的下一行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| $ objdump -d test
...
0000000000400770 <test>:
400770: 55 push %rbp
400771: 48 89 e5 mov %rsp,%rbp
...
4007b2: e8 59 fc ff ff callq 400410 <puts@plt>
4007b7: e8 28 ff ff ff callq 4006e4 <test1>
4007bc: 90 nop
4007bd: c9 leaveq
4007be: c3 retq
00000000004007bf <main>:
...
|
的確,下一行nop的位置就是就是4007bc,符合我們的想法。
其他有用的builtin函式
除了上面的例子,其實還有其他有用的builtin函式,這邊就只是列出來提供參考:
int __builtin_types_compatible_p(TYPE1, TYPE2):檢查TYPE1和TYPE2是否是相同type,相同回傳1,否則為0。注意這邊const和非const會視為同種類型。TYPE __builtin_choose_expr(CONST_EXP, EXP1, EXP2):同CONST_EXP?EXP1:EXP2的概念,但是這個寫法會在編譯時就決定結果。常用方式是在寫macro時可以搭配__builtin_types_compatible_p當作CONST_EXP,選擇要呼叫什麼函式。int __builtin_constant_p(EXP):判斷EXP是否是常數。long __builtin_expect(long EXP, long C):預先知道EXP的值很大機率會是C,藉此做最佳化,kernel的likely和unlikely也是靠這個實現的。void __builtin_prefetch(const void *ADDR, int RW, int LOCALITY):把ADDR預先載入快取使用。- RW:1代表會寫入資料,0代表只會讀取
- LOCALITY:範圍是0~3,0代表用了馬上就不用(不用關心time locality)、3代表之後還會常用到
int __builtin_ffs (int X):回傳X中從最小位數開始計算第一個1的位置,例如__builtin_ffs(0xc)=3,當X是0時,回傳0。int __builtin_popcount (unsigned int X):在X中1的個數int __builtin_ctz (unsigned int X):X末尾的0個數,X=0時undefined。int __builtin_clz (unsigned int X):X前面的0個數,X=0時undefined。int __builtin_parity (unsigned int x):X值的parity。
__attribute__
weak & alias
測試是否支援某function
通常會使用__attribute__(weak)是為了避免有函式衝突的狀況,我們看個例子
a.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <stdio.h>
extern void printf_test(void) __attribute__((weak));
int main()
{
printf("This is main function\n");
if(printf_test)
{
printf("Here is printf_test result: \n");
printf_test();
}
else
printf("We don't support printf_test\n");
return 0;
}
|
1
2
3
4
| $ make a
$ ./a
This is main function
We don't support printf_test
|
雖然我們沒有printf_test,但是直接編譯是會通過的,因為printf_test被視為weak,假設在連結時找不到,是會被填0的。
那如果有printf_test的情況呢?我們加上b.c重新編譯看看
1
2
3
4
5
6
| #include <stdio.h>
void printf_test(void)
{
printf("This is b function.\n");
}
|
1
2
3
4
5
| $ gcc a.c b.c
$ ./a.out
This is main function
Here is printf_test result:
This is b function.
|
看起來就會執行printf_test了。這樣的功能對我們要動態看有無支援函式幫助很大。
為函式加上default值
這邊我們會用到alias的attribute,alias的話通常會跟weak一起使用,最常被用到的是幫不確定有無支援的函式加上default值。
a.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #include <stdio.h>
void print_default(void)
{
printf("Not support this function.\n");
}
void print_foo(void) __attribute__((weak, alias("print_default")));
void print_bar(void) __attribute__((weak, alias("print_default")));
int main()
{
printf("This is main function\n");
print_foo();
print_bar();
return 0;
}
|
b.c
1
2
3
4
5
6
| #include <stdio.h>
void print_foo(void)
{
printf("foo function.\n");
}
|
1
2
3
4
5
| $ gcc a.c b.c
$ ./a.out
This is main function
foo function.
Not support this function.
|
可以看到因為print_bar並沒有被宣告,所以最後會執行alias的print_default。
在main前後執行程式
有時候會想要在main的執行前後可以做些事,這時候就會用到下面兩個attribute
- constructor:main前做事
- destructor:main之後做事
讓我們看個範例
test.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include <stdio.h>
__attribute__((constructor))
void before(void)
{
printf("before main\n");
}
__attribute__((destructor))
void after(void)
{
printf("after main\n");
}
int main()
{
printf("This is main function\n");
return 0;
}
|
1
2
3
4
5
| $ make test
$ ./test
before main
This is main function
after main
|
結果的確如我們所料。另外這邊有點要注意,跟前面不一樣的是,__attribute__((constructor))和__attribute__((destructor))必須放在函式前面,不然會有error: attributes should be specified before the declarator in a function definition的錯誤。
其他attribute
剩下還有一些有機會會用到的attribute,這邊就不多談,只列出來參考。
__attribute__((section("section_name"))):代表要把這個symbol放到section_name中__attribute__((used)):不管有沒有被引用,這個symbol都不會被優化掉__attribute__((unused)):沒有被引用到的時候也不會跳出警告__attribute__((deprecated)):用到的時候會跳出警告,用來警示使用者這個函式將要廢棄__attribute__((stdcall)):從右到左把參數放入stack,由callee(被呼叫者)把stack恢復正常__attribute__((cdecl)):C語言預設的作法,從右到左把參數放入stack,由caller把stack恢復正常__attribute__((fastcall)):頭兩個參數是用register來存放,剩下一樣放入stack
參考
]]>
@@ -514,35 +539,6 @@
- <h2 id="簡介"><a href="#簡介"
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-