Graphical representation for the users #51
Comments
|
Add graphics for "simple" linear dependence between variables. |
|
We need to investigate whether this library indeed solves PDP, in which case we should reuse it rather than reimplement. |
|
Do you want to include PDP as a model in the library? |
|
I find that scikit-learn has already implemented it but their graphical representation is quite limited. |
|
We should start with a nice graphical example showcasing it. Note that you should talk to the sklearn team (e.g. @glemaitre ), they want to rework the variable importance part. |
|
https://github.com/marcotcr/lime |
Currently, for the partial dependence we have a graphical representation that show the average and option to show the individual line and also a bar plot representation for categorical variable. @lionelkusch I'm wondering which graphical representation would you suggest to add. I think that we have more or less the one presented in Christopher Molnar book.
When it comes to a broader scope regarding variable importance, we indeed want to add or rework some part of scikit-learn:
|
|
Another possibility is, instead, to plot each point of the dataset; it's to plot the histogram. You can find some examples in the library shap: I found another library, which proposes a more complex representation but I like it. [alePython][https://github.com/blent-ai/ALEPython] |
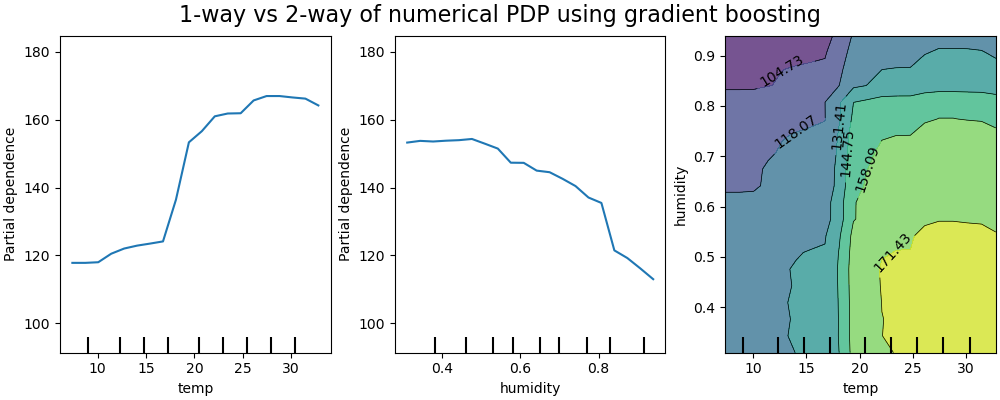


|
Thanks for the example, I see what you mean now. We need to go back to the following PR but I think that it partially address some the first remarks: scikit-learn/scikit-learn#27388. Maybe merging the quantile information on the marginal plot would be a way that:
|
|
@glemaitre As I understand it, feature_importances_ is only implemented for trees, based on Gini importance. If you want to generalize feature_importances_ to all models, from my point of view, it's not possible because some models don't have a human-understandable way of handling data, such as nonlinear models or high-dimensional predictor models. If we use the definition that feature importance provides a measure of the impact of a feature on the mean prediction of an estimator. In this case, extracting feature importance is non-trivial, as some features do not have a constant overall effect (especially with non-linear models) that may be difficult to summarize by a value. In addition, there is a trade-off between the importance of a variable in a sub-domain of the data and its overall importance, which is quite complex to induce. |
It is criterion agnostic, meaning if you use entropy, it will be based on this criterion. Basically it is called mean decrease in impurity (MDI) and so a more generic name. If we go with a renaming, then we need to take the opportunity to be able to compute different importances and not provide a single one (furthermore on the training set only).
Actually, we want to go against generalizing. We think that there is not one suitable for all models. However, we want to provide a common programmatic entry point for those methods such that are user can choose. For instance, the API should be enough flexible to let our user choose between the MDI or permutation importance (or SHAP) and we should not choose a |
|
We just started a discussion on the API for library in this issue #104. If you follow the conversation, it will probably give you some additional hints. |
|
It can be interesting to include graphic like Manhattan plot: https://en.wikipedia.org/wiki/Manhattan_plot |
|
This corresponds to marginal tests, but you're right this is part of the picture. |
|
This is a interesting tutorial with nice representation: https://github.com/monte-flora/scikit-explain/blob/master/tutorial_notebooks/accumulated_local_effect_tutorial.ipynb |
|
Nice indeed. |
|
This is nice paper on representation for representing the result: https://arxiv.org/pdf/1610.00290 |
|
I found this library in R which is specialised in representations of variables of importance: https://alaninglis.github.io/vivid/articles/vividVignette.html |
|
I found an example of PDP based on alluvial plots and with interactive examples: https://github.com/erblast/easyalluvial#partial-dependence-alluvial-plots |
|
An other way is to use Parallel Coordinate Plot: https://github.com/simonpradel/visualize-hyperparameter |
|
I think it does not scale really well when you increase the #variables... |
My summarise of the discussion with @AngelReyero and @jpaillard:
For basic users:
For more advanced users: (not yet finalised)
The text was updated successfully, but these errors were encountered: