+
+
+
+
+
+Update Imports Workflow
+This page discusses how to update the contents of your imports, like adding or removing terms. If you are looking to customise imports, like changing the module type, see here.
+Importing a new term
+Note: some ontologies now use a merged-import system to manage dynamic imports, for these please follow instructions in the section title "Using the Base Module approach".
+Importing a new term is split into two sub-phases:
+
+- Declaring the terms to be imported
+- Refreshing imports dynamically
+
+Declaring terms to be imported
+There are three ways to declare terms that are to be imported from an external ontology. Choose the appropriate one for your particular scenario (all three can be used in parallel if need be):
+
+- Protégé-based declaration
+- Using term files
+- Using the custom import template
+
+Protégé-based declaration
+This workflow is to be avoided, but may be appropriate if the editor does not have access to the ODK docker container.
+This approach also applies to ontologies that use base module import approach.
+
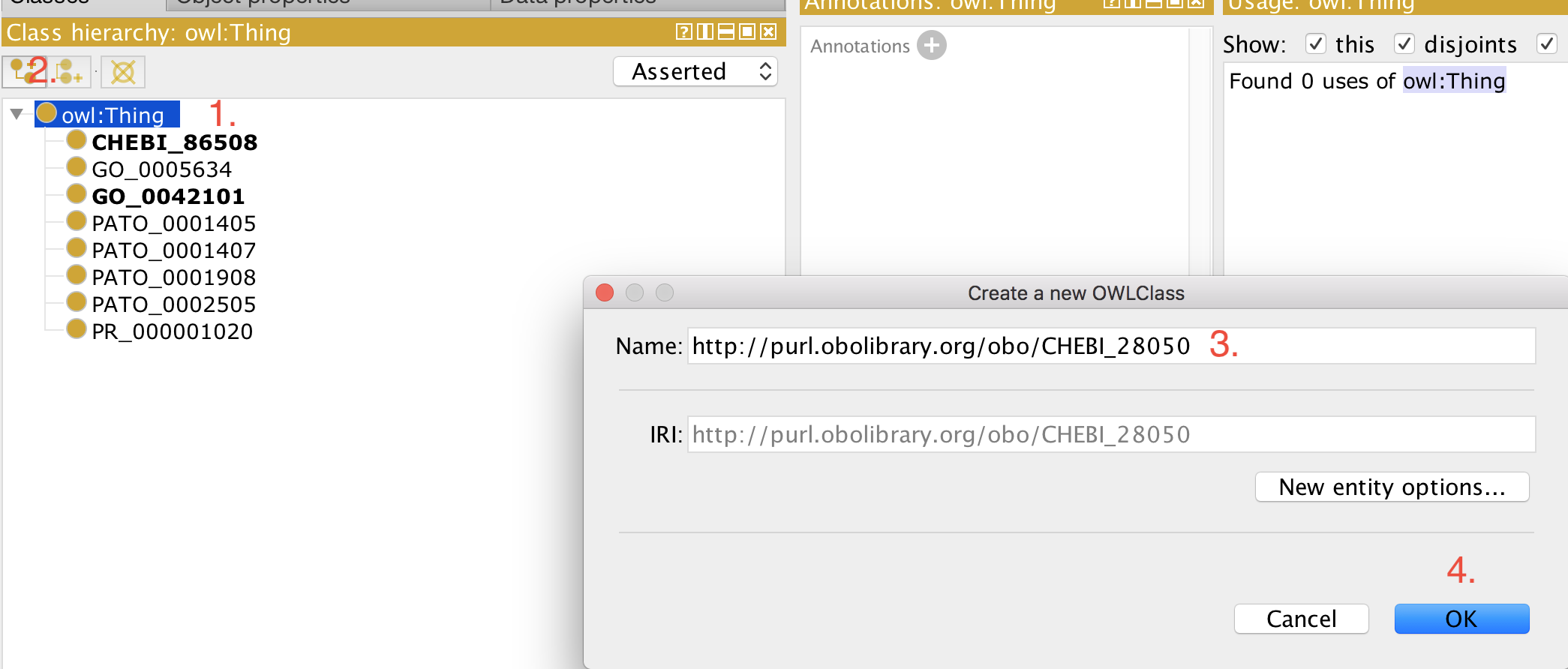
+- Open your ontology (edit file) in Protégé (5.5+).
+- Select 'owl:Thing'
+- Add a new class as usual.
+- Paste the full iri in the 'Name:' field, for example, http://purl.obolibrary.org/obo/CHEBI_50906.
+- Click 'OK'
+
+
+Now you can use this term for example to construct logical definitions. The next time the imports are refreshed (see how to refresh here), the metadata (labels, definitions, etc.) for this term are imported from the respective external source ontology and becomes visible in your ontology.
+Using term files
+Every import has, by default a term file associated with it, which can be found in the imports directory. For example, if you have a GO import in src/ontology/go_import.owl, you will also have an associated term file src/ontology/go_terms.txt. You can add terms in there simply as a list:
+GO:0008150
+GO:0008151
+
+Now you can run the refresh imports workflow) and the two terms will be imported.
+Using the custom import template
+This workflow is appropriate if:
+
+- You prefer to manage all your imported terms in a single file (rather than multiple files like in the "Using term files" workflow above).
+- You wish to augment your imported ontologies with additional information. This requires a cautionary discussion.
+
+To enable this workflow, you add the following to your ODK config file (src/ontology/upheno-odk.yaml), and update the repository:
+use_custom_import_module: TRUE
+
+Now you can manage your imported terms directly in the custom external terms template, which is located at src/templates/external_import.owl. Note that this file is a ROBOT template, and can, in principle, be extended to include any axioms you like. Before extending the template, however, read the following carefully.
+The main purpose of the custom import template is to enable the management off all terms to be imported in a centralised place. To enable that, you do not have to do anything other than maintaining the template. So if you, say currently import APOLLO_SV:00000480, and you wish to import APOLLO_SV:00000532, you simply add a row like this:
+ID Entity Type
+ID TYPE
+APOLLO_SV:00000480 owl:Class
+APOLLO_SV:00000532 owl:Class
+
+When the imports are refreshed see imports refresh workflow, the term(s) will simply be imported from the configured ontologies.
+Now, if you wish to extend the Makefile (which is beyond these instructions) and add, say, synonyms to the imported terms, you can do that, but you need to (a) preserve the ID and ENTITY columns and (b) ensure that the ROBOT template is valid otherwise, see here.
+WARNING. Note that doing this is a widespread antipattern (see related issue). You should not change the axioms of terms that do not belong into your ontology unless necessary - such changes should always be pushed into the ontology where they belong. However, since people are doing it, whether the OBO Foundry likes it or not, at least using the custom imports module as described here localises the changes to a single simple template and ensures that none of the annotations added this way are merged into the base file.
+Refresh imports
+If you want to refresh the import yourself (this may be necessary to pass the travis tests), and you have the ODK installed, you can do the following (using go as an example):
+First, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+cd src/ontology
+
+Then, you regenerate the import that will now include any new terms you have added. Note: You must have docker installed.
+sh run.sh make PAT=false imports/go_import.owl -B
+
+Since ODK 1.2.27, it is also possible to simply run the following, which is the same as the above:
+sh run.sh make refresh-go
+
+Note that in case you changed the defaults, you need to add IMP=true and/or MIR=true to the command below:
+sh run.sh make IMP=true MIR=true PAT=false imports/go_import.owl -B
+
+If you wish to skip refreshing the mirror, i.e. skip downloading the latest version of the source ontology for your import (e.g. go.owl for your go import) you can set MIR=false instead, which will do the exact same thing as the above, but is easier to remember:
+sh run.sh make IMP=true MIR=false PAT=false imports/go_import.owl -B
+
+Using the Base Module approach
+Since ODK 1.2.31, we support an entirely new approach to generate modules: Using base files.
+The idea is to only import axioms from ontologies that actually belong to it.
+A base file is a subset of the ontology that only contains those axioms that nominally
+belong there. In other words, the base file does not contain any axioms that belong
+to another ontology. An example would be this:
+Imagine this being the full Uberon ontology:
+Axiom 1: BFO:123 SubClassOf BFO:124
+Axiom 1: UBERON:123 SubClassOf BFO:123
+Axiom 1: UBERON:124 SubClassOf UBERON 123
+
+The base file is the set of all axioms that are about UBERON terms:
+Axiom 1: UBERON:123 SubClassOf BFO:123
+Axiom 1: UBERON:124 SubClassOf UBERON 123
+
+I.e.
+Axiom 1: BFO:123 SubClassOf BFO:124
+
+Gets removed.
+The base file pipeline is a bit more complex than the normal pipelines, because
+of the logical interactions between the imported ontologies. This is solved by _first
+merging all mirrors into one huge file and then extracting one mega module from it.
+Example: Let's say we are importing terms from Uberon, GO and RO in our ontologies.
+When we use the base pipelines, we
+1) First obtain the base (usually by simply downloading it, but there is also an option now to create it with ROBOT)
+2) We merge all base files into one big pile
+3) Then we extract a single module imports/merged_import.owl
+The first implementation of this pipeline is PATO, see https://github.com/pato-ontology/pato/blob/master/src/ontology/pato-odk.yaml.
+To check if your ontology uses this method, check src/ontology/upheno-odk.yaml to see if use_base_merging: TRUE is declared under import_group
+If your ontology uses Base Module approach, please use the following steps:
+First, add the term to be imported to the term file associated with it (see above "Using term files" section if this is not clear to you)
+Next, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+cd src/ontology
+
+Then refresh imports by running
+sh run.sh make imports/merged_import.owl
+
+Note: if your mirrors are updated, you can run sh run.sh make no-mirror-refresh-merged
+This requires quite a bit of memory on your local machine, so if you encounter an error, it might be a lack of memory on your computer. A solution would be to create a ticket in an issue tracker requesting for the term to be imported, and one of the local devs should pick this up and run the import for you.
+Lastly, restart Protégé, and the term should be imported in ready to be used.
+
+
+
+
+
+
+ 
{kind=link}