A benchmark to evaluate articulatory speech synthesis systems. This benchmark uses the VocalTractLab [1] as its articulatory speech synthesis simulator.
Warning
This package is not complete yet and will be hopefully released in March 2023 alongside the ESSV 2023. If you are interested in the current status get in touch with @derNarr or @paulovic96.
pip install articubench
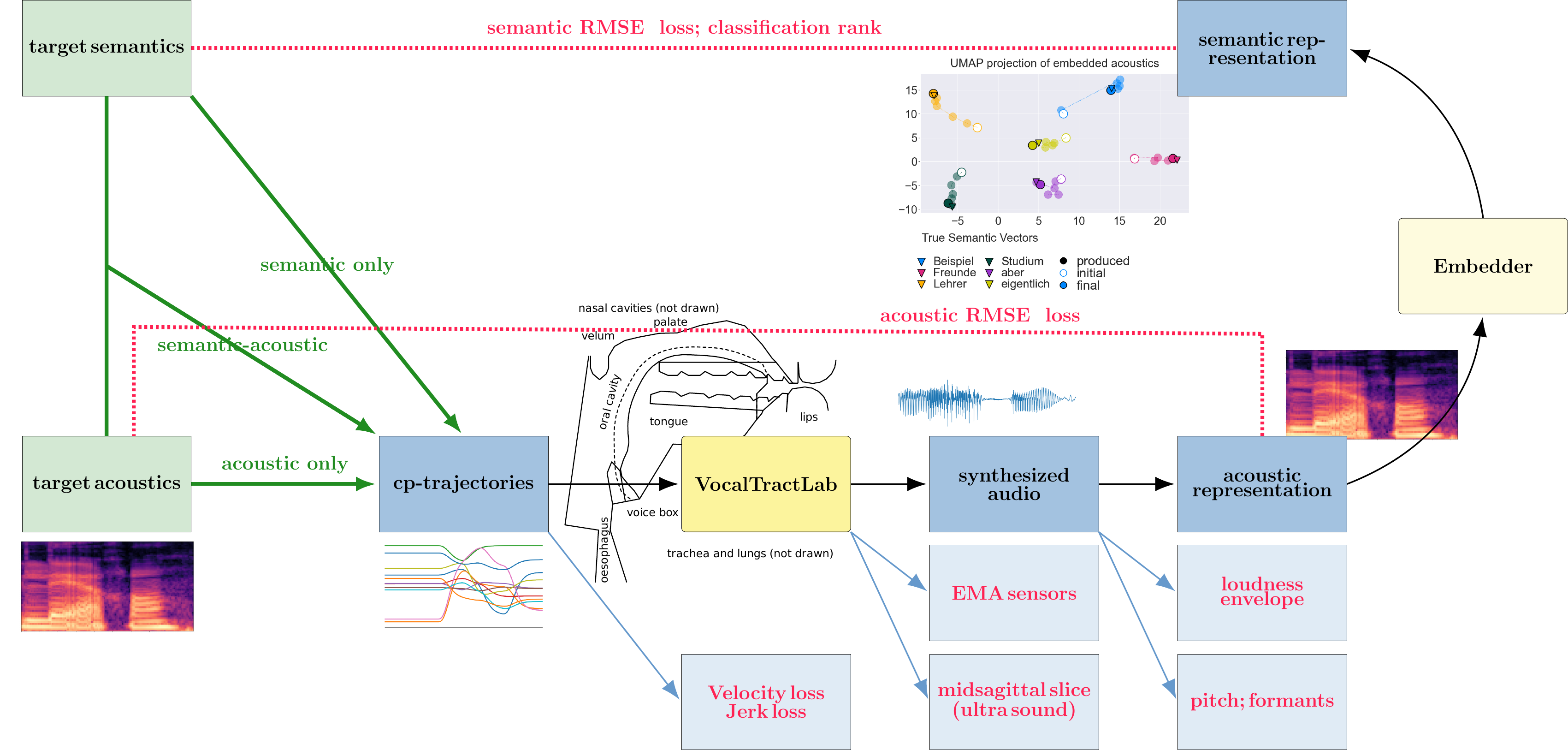
The benchmarks defines three tasks: acoustic only (copy-synthesis), semantic-acoustic and semantic only.
Comparing the PAULE, inverse, segment-based and baseline control models along different model properties. The memory demand includes the python binaries (200 MB). The segment model needs an embedder and the MFA in its pipeline, for which the data is given in parenthesis.
| Property | PAULE | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|
| Trainable parameters [million] | 15.6 | 2.6 | 0 (6.6 + MFA) | 0 |
| Execution time [seconds] | 200 | 0.2 | 0.5 (0.3 + MFA) | < 0.0001 |
| Memory demand [MB] | 5600 | 5000 | 2 (5100 + MFA) | 200 |
| Energy used for Training [kWh] | 393 | 1.9 | 0.0 (7.6 + MFA) | 0.0 |
Results will be published when they are available.
| Tiny / copy-synthesis | PAULE-fast | PAULE-full | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|---|
| Total Score | 324.57 | 380.34 | 213.84 | 114.58 | |
| Articulatory Scores | 50 | ||||
| Semantic Scores | 64.58 | ||||
| Acoustic Scores | 0 | ||||
| Tongue Height | 51.71 | 61.67 | 43.05 | 0 | |
| EMA sensors | 30.89 | 30.30 | 26.94 | 0 | |
| Max Velocity | (0.0) | (0.43) | (19.80) | ||
| Max Jerk | (0.0) | (0.43) | (19.80) | ||
| loudness envelope | 49.82 | 48.32 | -5.35 | 0 | |
| spectrogram RMSE | 48.77 | 48.95 | 0.07 | 0 | |
| semantic RMSE | 67.79 | 90.67 | 54.25 | 0 | |
| Classification | 75.60 | 100 | 75.08 | 64.58 |
| Tiny / semantic-acoustic | PAULE-fast | PAULE-full | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|---|
| Total Score | 143.91 | 319.51 | 212.08 | 114.58 | |
| Articulatory Scores | 50 | ||||
| Semantic Scores | 64.58 | ||||
| Acoustic Scores | 0 | ||||
| Tongue Height | 42.51 | 23.59 | 38.72 | 0 | |
| EMA sensors | 28.00 | 28.20 | 28.29 | 0 | |
| Max Velocity | (0.0) | (0.0) | (19.80) | ||
| Max Jerk | (0.0) | (0.0) | (19.80) | ||
| loudness envelope | 7.09 | 43.65 | -6.20 | 0 | |
| spectrogram RMSE | 9.82 | 43.13 | 0.64 | 0 | |
| semantic RMSE | 11.56 | 80.94 | 55.74 | 0 | |
| Classification | 44.93 | 100 | 75.08 | 64.58 |
| Tiny / semantic-only | PAULE-fast | PAULE-full | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|---|
| Total Score | 195.3 | 250.90 | 259.65 | 114.58 | |
| Articulatory Scores | 50 | ||||
| Semantic Scores | 64.58 | ||||
| Acoustic Scores | 0 | ||||
| Tongue Height | 41.23 | 47.31 | 20.75 | 0 | |
| EMA sensors | 28.84 | 28.74 | 28.62 | 0 | |
| Max Velocity | (0.0) | (0.0) | (22.60) | ||
| Max Jerk | (0.0) | (0.0) | (22.60) | ||
| loudness envelope | 2.76 | -10.41 | -5.54 | 0 | |
| spectrogram RMSE | 8.53 | -2.31 | -2.25 | 0 | |
| semantic RMSE | 39.27 | 87.78 | 100 | 0 | |
| Classification | 74.72 | 99.98 | 95.47 | 64.58 |
| Small / copy-synthesis | PAULE-fast | PAULE-full | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|---|
| Total Score | 91.81 | 63.21 | |||
| Articulatory Scores | 50 | ||||
| Semantic Scores | 13.21 | ||||
| Acoustic Scores | 0 | ||||
| Tongue Height | -1.64 | 0 | |||
| EMA sensors | 16.04 | 0 | |||
| Max Velocity | (0.0) | ||||
| Max Jerk | (0.0) | ||||
| loudness envelope | 35.72 | 0 | |||
| spectrogram RMSE | 29.12 | 0 | |||
| semantic RMSE | -0.36 | 0 | |||
| Classification | 12.94 | 13.21 |
| Small / semantic-only | PAULE-fast | PAULE-full | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|---|
| Total Score | -91.83 | 63.21 | |||
| Articulatory Scores | 50 | ||||
| Semantic Scores | 13.21 | ||||
| Acoustic Scores | 0 | ||||
| Tongue Height | 5.60 | 0 | |||
| EMA sensors | 17.50 | 0 | |||
| Max Velocity | (0.0) | ||||
| Max Jerk | (0.0) | ||||
| loudness envelope | -71.68 | 0 | |||
| spectrogram RMSE | -55.50 | 0 | |||
| semantic RMSE | -1.52 | 0 | |||
| Classification | 13.78 | 13.21 |
| Nomal | PAULE | Inverse | Seg-Model* | Baseline-Model |
|---|---|---|---|---|
| Total Score | ||||
| Articulatory Scores | ||||
| Semantic Scores | ||||
| Acoustic Scores | ||||
| Tongue Height | ||||
| EMA sensors | ||||
| Max Velocity | ||||
| Max Jerk | ||||
| Classification | ||||
| semantic RMSE | ||||
| loudness envelope | ||||
| spectrogram RMSE |
First ideas about the articubench benchmark were presented at the ESSV2022:
https://www.essv.de/paper.php?id=1140
@INPROCEEDINGS{ESSV2022_1140,
TITLE = {Articubench - An articulatory speech synthesis benchmark},
AUTHOR = {Konstantin Sering and Paul Schmidt-Barbo},
YEAR = {2022},
PAGES = {43--50},
KEYWORDS = {Articulatory Synthesis},
BOOKTITLE = {Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2022},
EDITOR = {Oliver Niebuhr and Malin Svensson Lundmark and Heather Weston},
PUBLISHER = {TUDpress, Dresden},
ISBN = {978-3-95908-548-9}
}
Data used here comes from the following speech corpora:
- KEC (EMA data, acoustics)
- baba-babi-babu speech rate (ultra sound; acoustics)
- Mozilla Common Voice
- GECO (only phonetic transscription; duration and phone)
For running the benchmark:
- python >=3.8
- praat
- VTL API 2.5.1quantling (included in this repository)
Additionally, for creating the benchmark:
- mfa (Montreal forced aligner)
- VTL is GPLv3.0+ license
This research was supported by an ERC advanced Grant (no. 742545) and the University of Tübingen.