有些课程的资源实在太多,难得手动去下载,再整理,故写了一个简单实用的爬虫程序,自动下载所有课程资源,保持文件(夹)的层级关系。 为了各位同学方便,贴出此博客,介绍如何下载使用。
本机上测试环境:
- python 3.7.x(估计3.5以上都没问题)
- selenium (在控制台输入
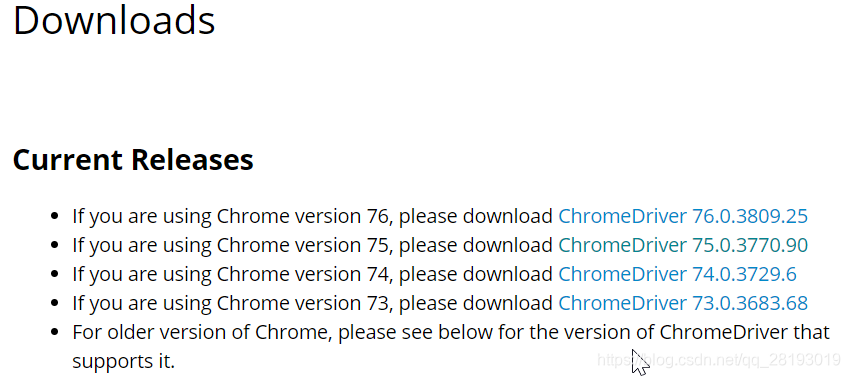
pip install selenium安装即可) - ChromeDriver.exe + Chrome浏览器,ChromeDriver.exe驱动下载地址:http://chromedriver.chromium.org/downloads 必须保证驱动与浏览器版本对应!!
- 最后就是必备的国科大教务网账号
可以去我的GitHub Crawl_UCAS_Course_2019 repository: https://github.com/tp-yan/Crawl_UCAS_Course_2019 ,clone or download zip压缩包,欢迎fork和star。
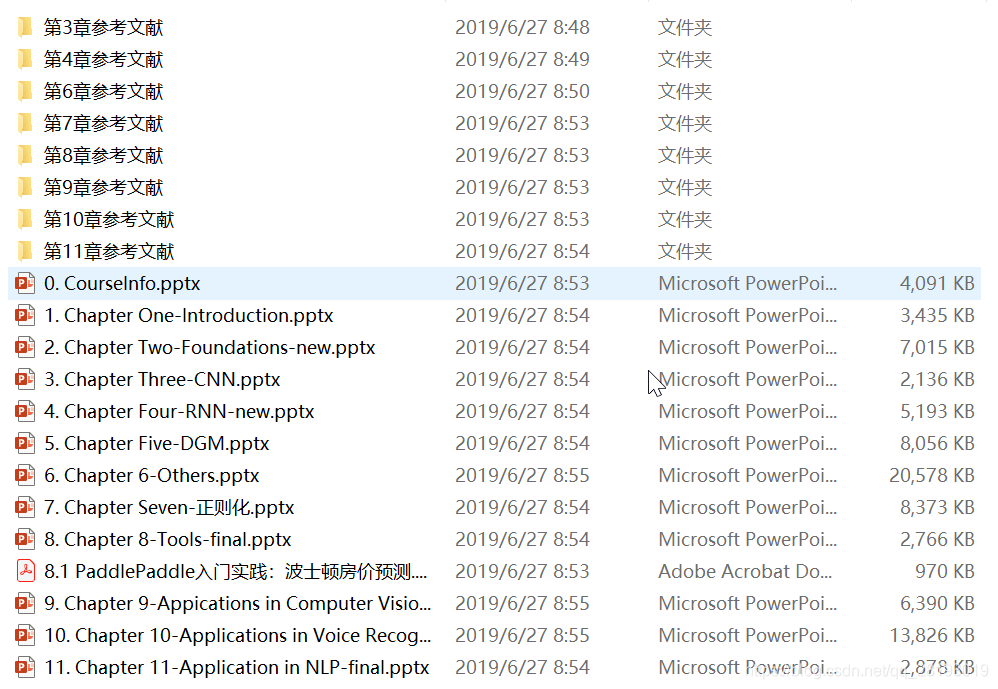
- 进入Crawl_UCAS_Course_2019文件夹下,内容应该如下(一定要注意把chromedriver.exe换成你自己下载的,必须与你本机Chrome浏览器版本一致):
- 开打控制台,输入
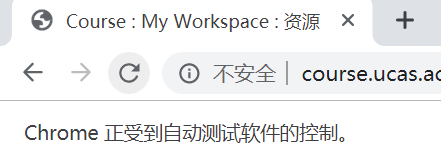
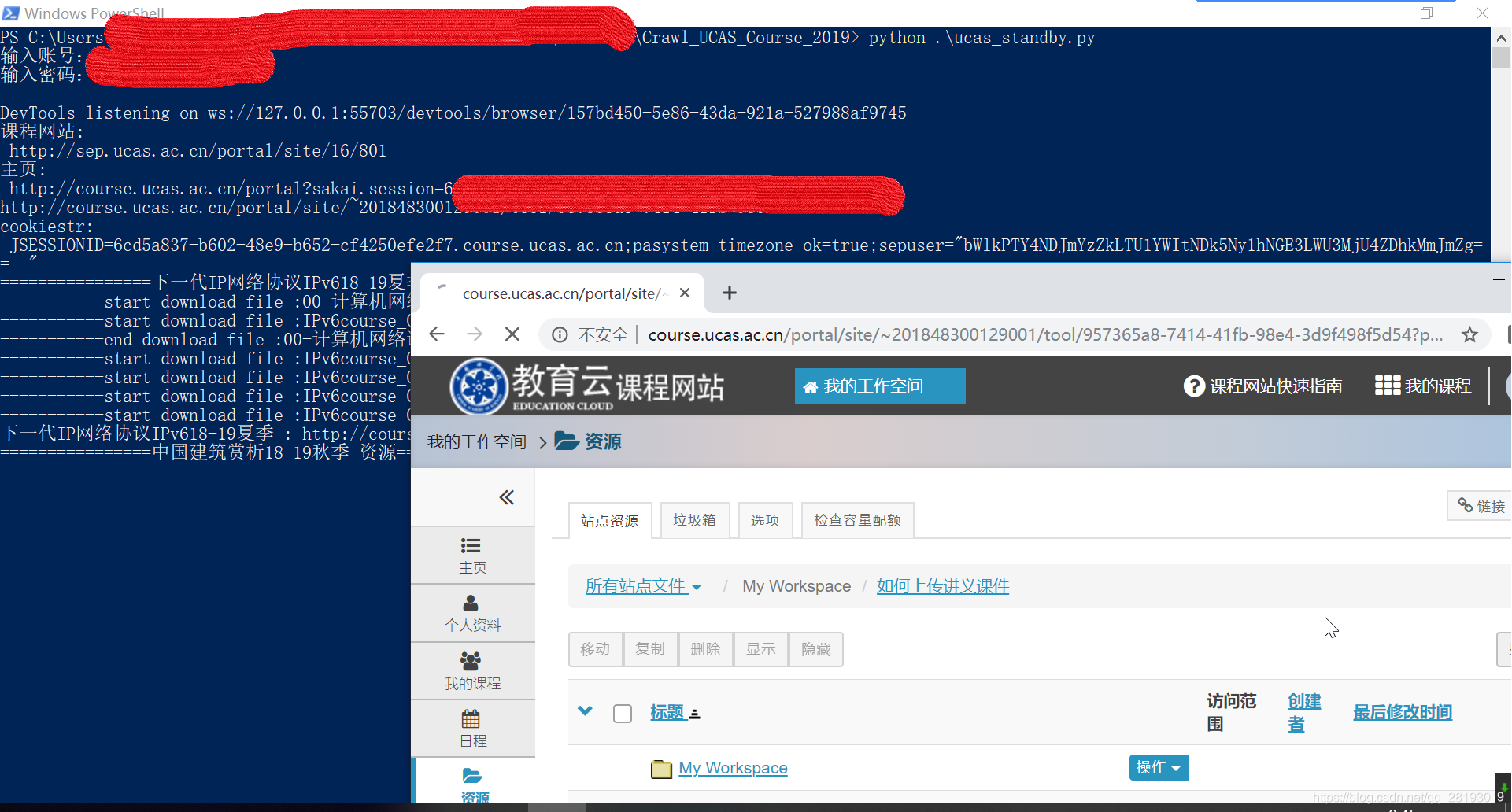
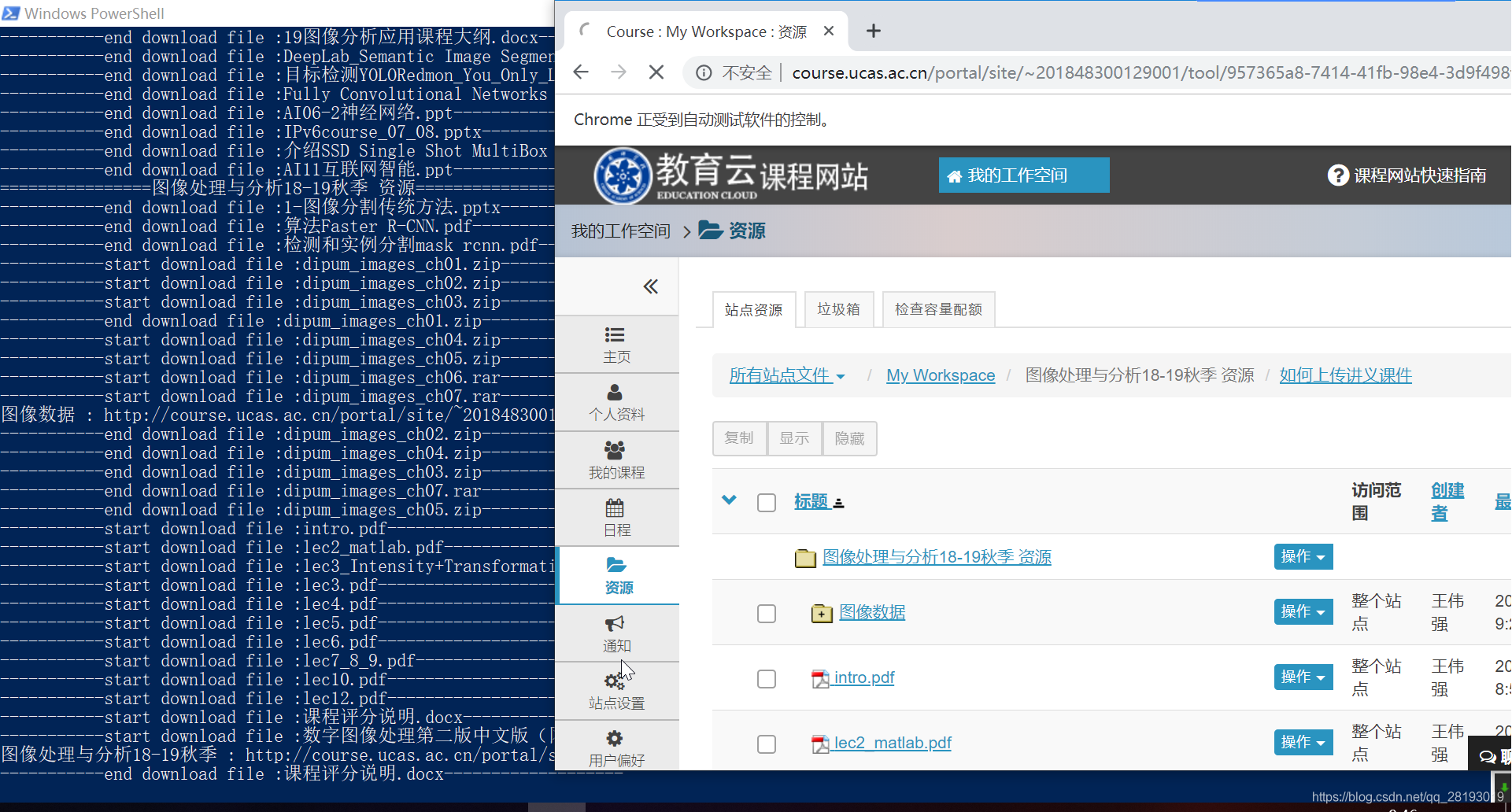
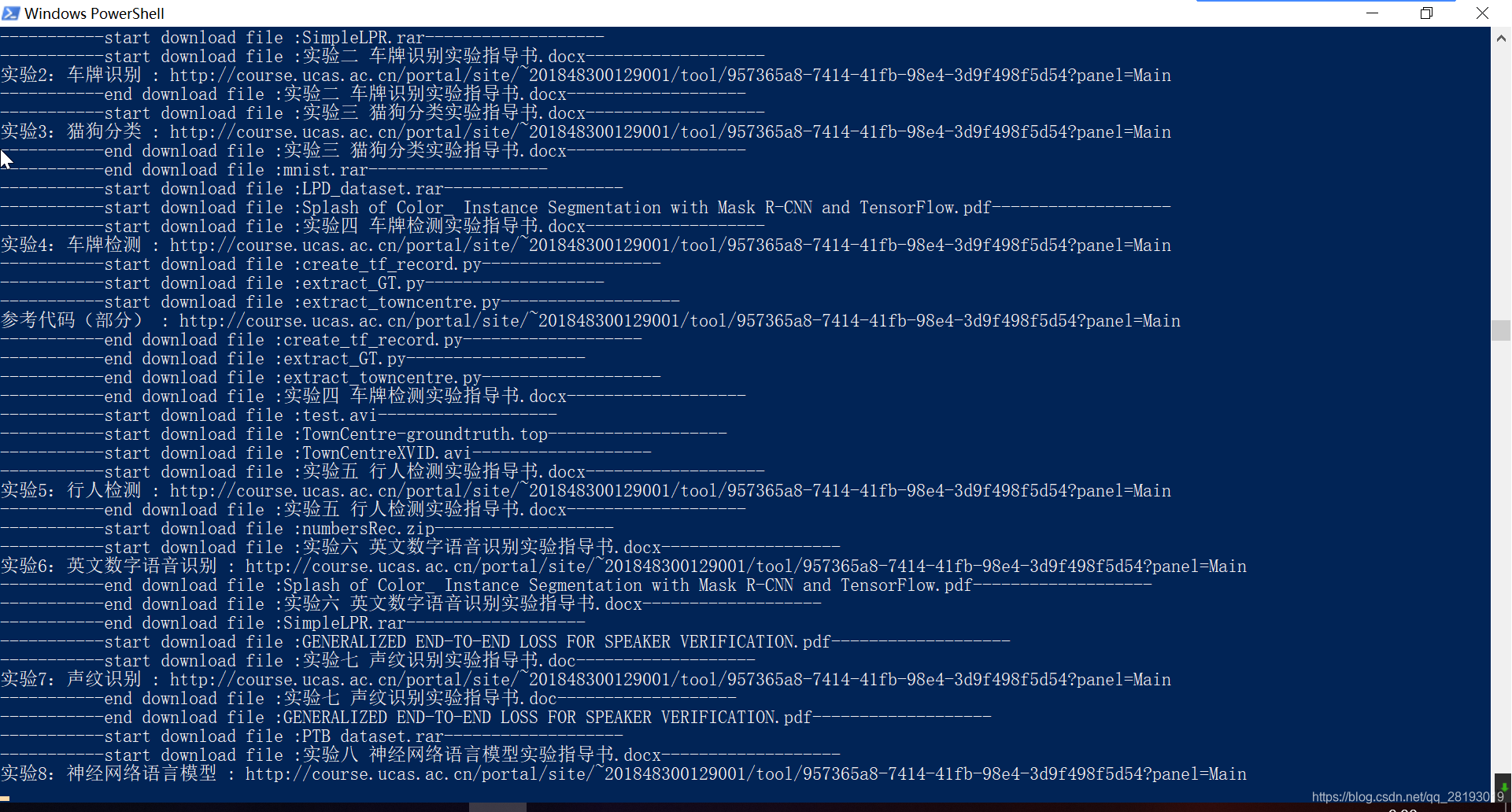
python ucas_standby.py(推荐使用这个版本),只要网络流畅,此版本执行效果不错。 - 自动打开Chrome浏览器,然后登录输入的账号,开始自动爬取课程资源,看到如下图表示selenium已经启动浏览器
- 注:若在爬虫途中页面停止,控制台没有报错,也许是网络阻塞了,可以手动去刷新一下该页面,爬虫程序应该会继续执行,若多次尝试后无法继续,请重新执行程序!
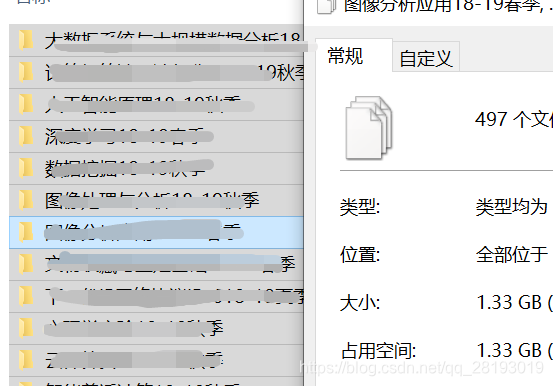
- 说明:每次启动程序,若原文件夹下存在已下载资源,则会清空该文件下所有文件后重新下载!!

- 如果觉得输入账号麻烦,可在这里直接写入账号:
def setUp(url,showBrowser=True):
'''默认打开浏览器'''
# myNo = "" # 也可以在这儿直接输入,
# myPwd = "" # 然后注释下面两行
myNo = input("输入账号:")
myPwd = input("输入密码:")
- 保存下载资源的根目录:
#保存资源的根目录
dir_name = "xxx_courses"
由于此爬虫是定向爬虫,若课程网站的页面布局发生了改变,也许可能出现问题,2019年6月份测试,可以使用。若使用过程中,出现问题,大半是由于网络原因,可以尝试刷新页面,或者多爬几次。为了顺利爬取,请在网络条件较好的情况下使用。另外,由于技术有限,不能保证程序都能正常执行,难免会存在一些错误,若有问题,大家可以评论商讨下,一起改善程序。
博客:https://blog.csdn.net/qq_28193019/article/details/93843206