Azure Monitoring # home | next
クラウドやオンプレミス、利用しているサービスにかかわらず、システムを維持する上で監視は重要な要素の1つです。あらためてなぜ監視が必要かを考えてみましょう。
システムの設計から構築において、全体のアーキテクチャーを始めとして、ネットワークの経路やシステムの冗長化、アプリケーションの機能実装を検討する流れはよくあるシステム開発の手法です。それぞれのフェーズで、レビューやテストを実施することで、設計や機能的な不具合を検出することも一般的です。
同様に、システム運用のフェーズにおいても、システムが正しく動作しているか継続的な確認が必要です。システムはユーザー数の変化や設定変更、ハードウェアの経年劣化によって変化し続けています。また、一般的にシステムは複数のコンポーネントで構成されています。日々変化している複雑なシステムはもはや何が起こるか予測することは困難です。
監視とは、運用フェーズにおいて継続的にシステムの動作をテストすることであり、継続的にサービスを提供するための不可欠な技術領域です。
監視の重要性と意味を理解し、効率的、効果的なシステム監視をしましょう。
多くのシステム設計では、監視設計として、監視対象のコンポーネントやそれぞれの監視項目、しきい値、アラートのトリガー条件を設計します。しかし、それらを設計する前に、監視戦略を立てることをお勧めします。

戦略がない監視は以下のような問題に直面することがあります。
- 障害が起きてから監視項目を追加する
- 監視ができていないサーバーが出てくる
- 監視ツールが多すぎる
- 監視ツールの制約によってできない(実装しにくい)監視がある
- 監視しかできない人がいる
- アラートを無視している
- サービスが停止していることに気付けない
監視の戦略は、ビジネスの視点で計画します。対象のシステムでどのような状態がビジネスとして正しい状態であるかを考えます。
以下は正しい状態の一例です。
- ユーザーがアプリケーションやサービスを利用できる状態である
- 利益が出せている状態である
- ユーザーの満足度が高い状態である
この正しい状態から、具体的な指標を決め、その指標をベースに監視の項目やアラートのトリガーを決定します。
以下は指標と指標から決定できる項目の一例です。
- ユーザーのログイン
- ログインの失敗率
- ログインまでの遅延時間
- アプリケーションの起動
- 起動にかかる時間
- アプリケーションの使用
- ファイルの保存にかかる時間
- クラッシュ率
- 品物の購入
- 購入の失敗率
これらの指標はシステムのアーキテクチャーやそのシステムを利用する組織・ユーザーによって大きく異なるため、それぞれのシステムで個別かつ具体的に検討する必要があります。この指標を決めるうえでベストプラクティスや汎用的に利用できるチェックリスト、指標等はありません。
次節以降で監視の戦略を立てる際のポイントを解説します。
監視戦略を計画したうえで、システムを構成するコンポーネントの特性を理解し、何を監視できるのかどのように監視すべきか監視の結果をどのようにとらえるかを考えます。
ここでは以下のカテゴリで説明します。
- アプリケーション
- サーバー
- ネットワーク
- セキュリティ
クラウドを利用している場合、これらのコンポーネントはクラウドプロバイダーによって管理されているケースがあります。しかしそれはあくまでも管理主体がクラウドプロバイダーとなるだけで、それぞれのサービスでサーバーやネットワーク等が利用されていないわけではありません。
クラウドを利用する場合であってもそれぞれの特性を理解することで監視設計に活かすことができます。

アプリケーションは、大きく Web アプリケーションと 非 Web アプリケーションがあり、持っている特性や監視の方法も大きく異なります。ここでは、前提として Web アプリケーションを対象として説明しますが、非 Web アプリケーションであっても考え方は参考にできる部分があります。
Web アプリケーション は主に、フロントエンドとバックエンドで構成されています。
フロントエンドはユーザーのクライアントアプリケーションやクライアントのパフォーマンス、ネットワーク帯域によって大きく左右されます。たとえば、「ブラウザで Web ページを表示する」と一言で言っても、アプリケーションのリクエストの開始から始まり、名前解決、レスポンスまでの時間、DOM の表示開始から読み込み完了、JavaScript の実行等の処理が行われます。
以下は、W3C によって作成された Web アプリケーションのナビゲーションの処理モデルです。
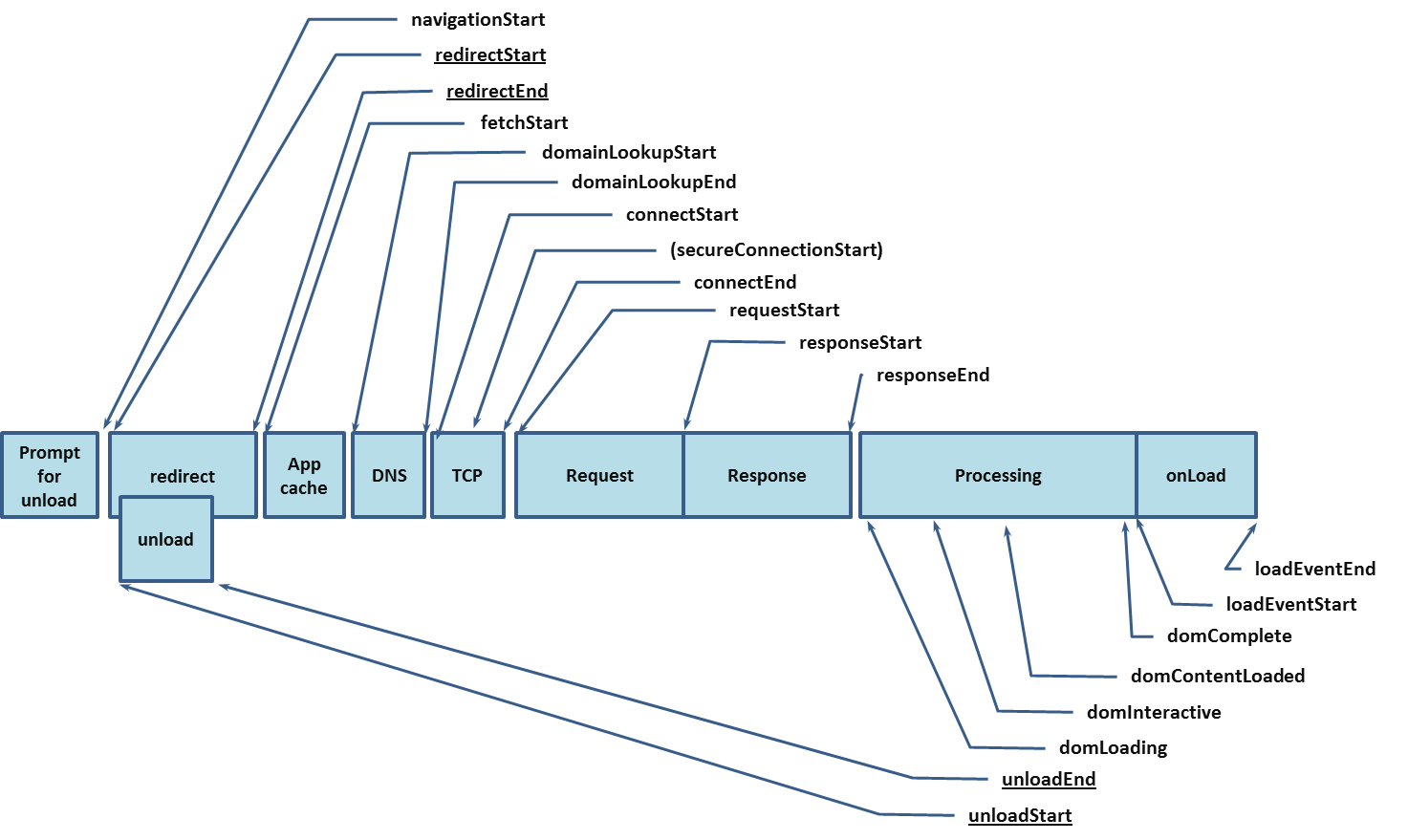
こちらの図を見ると、ブラウザのナビゲーションが開始されてからページの読み込みが完了するまでに、さまざまな処理が行われていることがわかります。
フロントエンドの監視は、Real User Monitoring と Synthetic Monitoring があります。Real User Monitoring は、実際のユーザーのクライアントアプリケーションからパフォーマンスを測定します。主な手法としては、Web ページに JavaScript を埋め込み、アプリケーションの読み込み速度を測定します。ページに JavaScript を埋め込む必要がありますが、詳細なパフォーマンスが測定できます。
一方で Synthetic Monitoring は、外部から見たときの読み込み開始から完了までのパフォーマンスを測定します。手法としては擬似的なクライアントを用意し、Web ページの読み込み速度を測定します。JavaScript の埋め込み等アプリケーションへの影響を与えることがないため簡単に実装できますが、詳細なパフォーマンス測定はできません。
バックエンド(サーバーサイド)のアプリケーションは以下の特性を持っています。
- アプリケーションの処理には時間がかかる
- DB へのアクセス等ほかのコンポーネントも影響する
- 高負荷時には処理が遅延する
- アプリケーションはログを出力する
- ログレベルを変更できるアプリケーションがある
- ログの出力先を選択できるアプリケーションがある
- アプリケーションは異常系や想定しない動作(例外)が起きる
- ユーザーの入力不正、DB アクセスのタイムアウト等
- バグがある
サーバーサイドのアプリケーションは以下の観点で監視します。
- ヘルスエンドポイント
- Web アプリケーションにエンドポイントを用意し、アプリケーションの実行、DB の書き込み、キャッシュへの書き込み等一連の処理を行う
- それによってフロントエンドからバックエンドまで通しの監視ができる
- パフォーマンスの監視
- コードに組み込むことで、DBへのアクセス時間、ログイン処理にかかった時間等を計測する
- アプリケーションロギング
- アプリケーションが出力するログを監視し、異常ログの発生数・率を監視する

サーバーサイドのアプリケーションは、Application Performance Management(APM) を活用すると監視に必要なデータを収集しやすくなります。APM はアプリケーションへコードを埋め込み、パフォーマンスやログ、例外を取得し可視化するツールです。Azure では Application Insights が APM として利用できます。
サーバーはサービスを提供する一番基盤となるコンポーネントです。クラウドのマネージドサービスを利用していてもそのサービスの下ではサーバーが存在します。サーバーは以下の特性を持っています。
- さまざまなサービスを提供している
- Web サービス、データベース、ファイル共有、etc...
- OS 上のプロセスとして実現されている
- ハードの性能に依存する
- 必ず壊れる
以下はサーバー監視のポイントです。
- OS が提供する標準的なメトリック・ログを活用する
- CPU 使用率、ロードアベレージ、メモリ使用率、ディスク使用率、etc...
- サーバーの役割ごとにメトリックやログが提供されていることがある
- データベース: コネクション数、クエリ数、スロークエリログ
- Web サーバー: リクエスト数、レイテンシー、HTTP ステータスコード、エラーログ
- ロギングの方法を確認する
- OS 標準のしくみを使うサービス、独自のロギング機構を持つサービスがある
システム全体の監視として、OS のメトリックやログを利用することが効果的な監視ではないことがあります。CPU 使用率やロードアベレージが高くてもユーザーがストレスなくサービスを利用できているのであればただちに問題視する必要はありません。ただし、OS のメトリックやログの異常値は、障害につながることがあるため、データを収集しておくことは重要です。
ネットワークはサーバーどうしやサーバーとクライアントを接続するためのコンポーネントです。アプリケーションやサーバーへアクセスするときに必ず使用されるコンポーネントでもあります。ネットワークは以下の特性を持っています。
- アプリケーションやサーバーの可用性は、ネットワークの可用性以上にはならない
- ネットワークがダウンすると、アプリケーション・サーバーへのアクセスもできなくなるため、システムとしての サービスレベルが下がる
- アプリケーションの動作に影響
- レイテンシーやジッターはユーザーの体感に大きく影響する
- 特に音声や動画を扱う場合は高品質なネットワークが求められる
- ブラックボックスになることが多い
- ハードウェア(もしくはクラウド) で提供されるため、ユーザーがモニタリングできる範囲は少なくなる
- ハードウェア、ファームウェア、プロトコルに関する専門の知識が必要
- 複数の機器で構成されることが一般的
- いつの間にか障害が発生していることがある
- 設定変更の影響が大きい
- 思いもよらない箇所・タイミングで大規模障害が発生する
- 必ずしも管理範囲内の設定変更のみとは限らない
以下はネットワーク監視のポイントです。
- 機器単体を監視する
- CPU 使用率/ メモリ使用量
- インターフェースのトラフィック量/エラー量/ドロップ率
- ブロードキャストパケット率
- 設定変更
- ネットワーク全体を監視する
- ネットワークフロー(送信元先のIPアドレス/ポート番号/プロトコル)
- ジッター
- レイテンシー
- トポロジー
ネットワーク監視で重要なポイントは、ネットワーク全体を見ることです。ネットワークは複数の機器で構成されており、機器単体の監視では障害の検知までに時間がかかります。また、通常ネットワーク機器や経路は冗長化されていることが多く、サービス監視をするためにはサーバーからクライアントまでエンドツーエンドで監視します。
セキュリティは技術領域の幅が非常に広いトピックです。従ってセキュリティの監視はセキュリティの専門家、専任のエンジニアで行う必要があります。以下はセキュリティ監視の一例です。
- OS の重要な設定の変更検知
- DDoS やbot等の振る舞いによるネットワークトラフィックの監視
- ウィルス検知
- 認証基盤に対するアクセス、変更の検知
- アクセスログの監視
- バックアップの状態監視
セキュリティ監視はバランスを取る必要があります。すべてのサーバーの挙動を見るためにすべてのサーバーでネットワークパケットを取得することは現実的ではありません。一方で必要な情報が取得できないセキュリティ監視はセキュリティホールとなります。対象のシステムに対して考えられる脅威とその脅威に対する対処を検討したうえで監視を検討する必要があります。
監視の最終的な目的はシステムを継続することです。「監視の戦略を立てる」で記述した、それぞれのビジネス要件を満たすための指標が一定以上のレベルを維持することを監視します。この指標をサービスレベル指標(Service Level Indicator)と言い、その目標値をサービスレベル目標(Service Level Objective)と言います。
この指標は、CPU 使用率やディスク使用量、エラー数等の OS やハードウェア、クラウドサービスが提供するプリミティブな値ではありません。ビジネス要件に合ったディスカッションの結果としてそのような値を利用することもありますが、これらの値は効果的な監視をするための指標としては不足しているケースがあります。
SLI/SLO を決める上で必要なことは、あくまでもビジネスの視点から決められた指標である(ユーザーのエクスペリエンスに直結している)ことです。SLO は SLA の指標として利用されることがあるため、ビジネスチームと完全に合意したうえで決定する必要があります。以下にいくつか SLI/SLO の例を挙げます。
- 可用性
- ダウンタイムやメンテナンスの平均間隔等のサービスを継続できている時間を割合で示す
- キャパシティー
- ネットワークの帯域幅、ストレージ使用量、レイテンシー等のキャパシティーを割合で示す
- スループット
- 単位時間当たりのトランザクション数等の一定期間における処理量を示す
- エラー率
- 購入ボタンを押した際の 5xx 等エラー数の割合を示す
- コスト
- コンポーネント毎の単位時間当たりのコストを示す
SLI/SLO の決定については以下のドキュメントも参照してください。
監視の方法はさまざまありますが、効率的な監視をするためには要件に合った適切な監視方法を選択する必要があります。たとえば、サーバーの監視は OS にエージェントをインストールしそのエージェントがデータを送信するプッシュ型と、エージェントをインストールしなくても外部からデータを取得するプル型があります。
また、収集したデータをオンプレミス環境に展開したサーバーへ保存するオンプレミスベースの製品と、クラウドのマネージドサービスを利用したクラウドベースの製品があります。どちらを採用するかは要件とそれぞれの製品、サービスの機能を検討し決定します。併用することも検討します。
SRE チームのような監視を専門に行っているエンジニアやチームがない場合、なるべく構築や設定、運用が簡単な方法を検討します。
監視に必要なデータを取捨選択し、効率のよいデータ収集と効果のあるデータ活用をします。一般的に、データの保存にはコストがかかります。すべてのデータを満遍なく収集する方法は、データの保持にコストがかかるだけでなく、活用する際の障壁にもなり得ます。
収集するデータは活用方法の観点から個別に決定し、必要最小限にデータを収集し保存します。たとえば、アラートを発報させるために必要なデータは、対象が限定的で保持期間も短くても問題ありません。サインインログのような監査に必要なデータは簡単にデータにアクセス・参照できるよりも長期的かつ安価に保持する必要があります。CPU 使用率のようなアラートに利用しないもののサーバーのキャパシティープランに利用できるデータは数ヵ月間保持する必要があります。
保存するログ、保存する期間、保存する場所を検討します。
監視基盤は継続的に見直していく必要があります。監視は運用と密接に連携しており、障害の発生時やコストの最適化によって、監視も見直していきます。
運用は主にプロアクティブとリアクティブの2つのタイプがあり、プロアクティブな運用は、障害が発生する前に障害を予防するための運用です。インシデントを分析し、障害が再発しないように対策を講じます。たとえば、サーバーのスケールアップ、スケールインやネットワーク帯域の追加、アプリケーションへのリトライ機構の実装などがあります。これらのプロアクティブな運用の中で監視を改善していきます。