swoole是一个多进程模式的框架(可以类比nginx的进程模型),当启动一个swoole应用时,一共会创建2+n+m个进程,其中n为worker进程数,m为taskWorker进程数,2为一个master进程和一个manager进程
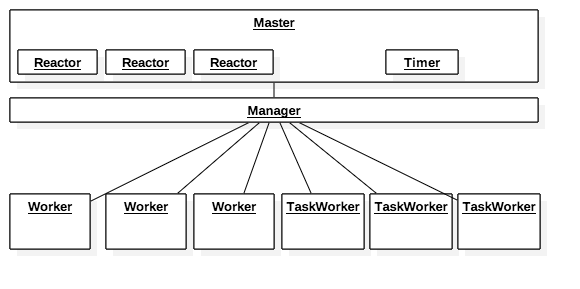
其中,master进程为主进程,该进程会创建manager进程,reactor线程等工作进/线程
- reactor线程实际运行epoll实例,用户accept客户端连接以及接收客户端数据
- manager 进程为管理进程,该进程的作用是创建,管理所有的Worker进程和TaskWorker进程。
Worker进程作为swoole的工作进程,所有的业务逻辑代码均在此进程上运行。当Reactor线程接收到来自客户端的数据后,会将数据打包通过管道发送给某给Worker进程
当一个Worker进程被成功创建后,会调用OnWorkerStart回调,随后进入事件循环等待数据。当通过回调函数接收到数据后,开始处理数据。如果处理数据过程中出现严重错误导致进程退出,或者Worker进程处理总请求达到指定上限,则Worker进程调用OnWorkerStop回调并结束进程
Task Worker是swoole中一种特殊的工作进程,该进程的作用是处理一些耗时较长的任务,以达到释放Worker进程的目的。Worker进程可以通过swoole_server对象的task方法投递一个任务到Task Worker进程。
Worker进程通过Unix Sock管道将数据发送给Task Worker,这样Worker进程就可以继续处理新的逻辑,无需等待耗时任务的执行。
协程是一种轻量级的线程,由用户代码来调度和管理,而不是由操作系统内核来进行调度,也就是在用户态进行。可以直接理解为就是一个非标准的线程实现,但什么时候切换有用户自己来实现,而不是由操作系统分配CPU时间来决定。具体来说,swoole的每个worker进程会存在一个协程调度器来调度协程,协程切换的时机就是遇到I/O操作或代码显性切换时,进程内以单线程的形式运行协程,也就意味着一个进程内同一时间内只会有一个协程在运行且切换时机明确,也就无需处理像多线程编程下的各种同步锁的问题。
单个协程内的代码运行仍是穿行的,放在一个HTTP协程服务上来理解就是每一个请求就是一个协程,举个例子,假设为请求A创建了协程A,为了请求B创建了协程B,那么在处理协程A的代码的时候代码跑到了查询MYSQL的语句上,这个时候协程A则会触发协程切换,协程A就等待I/O设备返回结果,那么此时就会切换到协程B,开始处理协程B的逻辑,当又遇到一个I/O操作,便又触发协程切换,再回到从协程A刚才切走的地方继续执行,如此反复,遇到I/O操作就切换到另一个协程去继续执行而非一直阻塞等待。
协程与普通线程区别。在同一时间内可以有多个线程,但对于swoole协程只能有一个,其他的协程都处于暂停的状态。此外,普通线程是抢占式,哪个线程都能得到资源由操作系统决定,而协程是协作式的,执行权由用户态自行分配
- 不能存在阻塞代码
- 不能通过全局变量存储状态
在swoole的持久化应用下,一个worker内的全局变量是worker内共享的。一个worker内还会存在多个协程并存在协程切换,也就意味着一个worker会在一个时间周期内同时处理多个协程的代码,也就意味着如果使用了全局变量来存储状态可能会被多个协程所使用,也就是不同请求之间可能会混淆数据。
协程内代码的阻塞会导致协程调度器无法切换到另一个协程继续执行代码,所以我们绝不能在协程内存在阻塞代码,假设我们启动了 4 个 Worker 来处理 HTTP 请求(通常启动的 Worker 数量与 CPU 核心数一致或 2 倍),如果代码中存在阻塞,暂且理论的认为每个请求都会阻塞 1 秒,那么系统的 QPS 也将退化为 4/s ,这无疑就是退化成了与 PHP-FPM 类似的情况,所以我们绝对不能在协程中存在阻塞代码。