Using RDFunit with Bamboo
Testing your ontology and data projects with RDFunit in Bamboo is very easy. Bamboo has an integrated JUnit parser which you can use for that. So the steps you need to do:
- create an new plan with a testing stage and a single rdfunit job
- create three tasks in this job
- task 1: Source Code Checkout (as usual, prepare everything for the test)
- task 2: Command (here you start rdfunit)
- task 3: JUnit Parser
RDFunit needs to be started with the -o junitxml parameter. Here is how we start our rdfunit:
rdfunit -v -d /data/combined-source.ttl -s ${VOCABS}/data/combined-source.ttl -o junitxml -C -f /data/
/data is the main directory here and combined-source.ttl is a generated file of all data to test in the project (typical a concatenation of turtle files which is generated for bamboo in a first step).
One specific problem is, how to create the list of used vocabularies for rdfunit, since this is specific of each project. We decided to use the information from the project itself, specifically the values from the void:vocabulary property of the ontology (fetched by jena's sparql command line tool).
## get the vocabularies, turn them into one comma-separated string
define VOCABS
$(shell sparql --data /data/combined-source.ttl --results=CSV
'SELECT ?vocab WHERE {?s a <http://www.w3.org/2002/07/owl#Ontology>; <http://rdfs.org/ns/void#vocabulary> ?vocab}' | tail -n+2 | tr -s '\r\n' ',')
endef
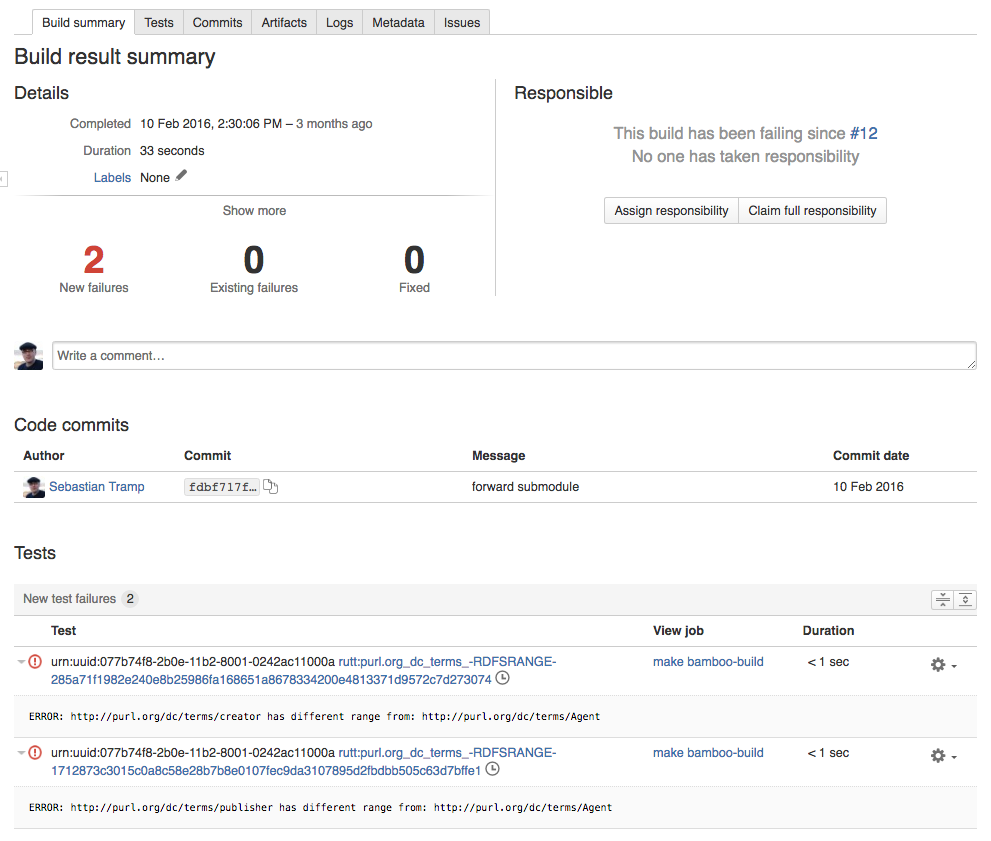
The rdfunit task produces an XML result file in .../results/_data_.all.ttl.aggregatedTestCaseResult.xml . The JUnit parser task then just needs to parse this xml file by parsing the complete results directory **/results/*.xml.
This produces nice overviews about errors in your bamboo report.