-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
GITBOOK-198: item 48. 스트림 병렬화는 주의해서 적용하라
- Loading branch information
1 parent
6e2c855
commit b07c1bf
Showing
3 changed files
with
308 additions
and
0 deletions.
There are no files selected for viewing
.png){kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
307 changes: 307 additions & 0 deletions
307
developLog/programming-lanuage/java/effective-java/7/item-48.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,307 @@ | ||
| # item 48 : 스트림 병렬화는 주의해서 적용하라 | ||
|
|
||
| ## 1. 자바의 동시성 프로그래밍의 역사 | ||
|
|
||
| > 주류 언어 중, 동시성 프로그래밍 측면에서 자바는 항상 앞서갔다 | ||
| ### **1) 릴리스** | ||
|
|
||
| 스레드, 동기화, wait/notify를 지원했다. | ||
|
|
||
| 1. `wait` : 갖고 있던 고유 락을 해제하고, 스레드를 잠들게 한다. | ||
| 2. `notify` :잠들어 있던 스레드 중 임의로 하나를 골라 깨운다. | ||
|
|
||
| ### **2) 자바 5 이후** | ||
|
|
||
| 동시성 컬렉션인 `java.util.concurrent` 라이브러리와 실행자(Executor) 프레임워크 지원했다. | ||
|
|
||
| ### **3) 자바 7 이후** | ||
|
|
||
| 고성능 병렬 분해 프레임워크인 포크-조인(fork-join) 패키지를 추가했다. | ||
|
|
||
| ### **4) 자바 8 이후** | ||
|
|
||
| `parallel` 메서드만 한 번 호출하면 파이프라인을 병렬 실행할 수 있는 스트림을 지원했다. | ||
|
|
||
| 이처럼 동시성 프로그램을 작성하기 점점 쉬워지고 있지만, **동시성 프로그래밍을 할때는 항상 안전성(safety)와 응답 가능(liveness) 상태를 유지** 해야 하는 것에 주의해야 한다. | ||
|
|
||
|
|
||
|
|
||
| ## 2. 동시성 프로그래밍 주의점 | ||
|
|
||
| ### **1) 스트림 병렬화를 사용하면 안되는 경우** | ||
|
|
||
| > 스트림을 사용해 처음 20개의 메르센 소수를 생성하는 프로그램  | ||
| > | ||
| > **메르센 소수**란? **2의 거듭제곱에서 1을 뺀 형태의 수**로, 소수인 수를 의미한다. | ||
| ```java | ||
| import java.math.BigInteger; | ||
| import java.util.stream.Stream; | ||
|
|
||
| public class MersennePrimes { | ||
| public static void main(String[] args) { | ||
| // 소수를 생성하고, 메르센 소수인지 확인 후 상위 20개를 출력하는 스트림 파이프라인 | ||
| primes() // 소수 스트림 생성 | ||
| .map(p -> TWO.pow(p.intValueExact()).subtract(ONE)) // 메르센 수 계산: 2^p - 1 | ||
| .filter(mersenne -> mersenne.isProbablePrime(50)) // 메르센 수가 소수인지 검사 | ||
| .limit(20) // 상위 20개의 메르센 소수만 가져오기 | ||
| .forEach(System.out::println); // 각 메르센 소수 출력 | ||
| } | ||
|
|
||
| // 무한 소수 스트림을 생성하는 메서드 | ||
| static Stream<BigInteger> primes() { | ||
| return Stream.iterate(TWO, BigInteger::nextProbablePrime); // 2부터 시작하여 다음 소수를 계속 생성 | ||
| } | ||
|
|
||
| // 상수 정의 | ||
| private static final BigInteger TWO = BigInteger.valueOf(2); | ||
| private static final BigInteger ONE = BigInteger.ONE; | ||
| } | ||
|
|
||
| ``` | ||
|
|
||
| 이 프로그램을 내 컴퓨터에서 실행하면 즉각 소수를 찍기 시작해서 12.5초 만에 완료된다. | ||
|
|
||
| > 속도를 높이고 싶어 스트림 파이프라인의 parallel()을 호출하겠다는생각을 하고 사용시, 성능은 어떻게 변할까? | ||
| ```java | ||
| @Test | ||
| public void mersenne() { | ||
| primes() | ||
| .parallel() | ||
| .map(p -> TWO.pow(p.intValueExact()).subtract(ONE)) | ||
| .filter(mersenne -> mersenne.isProbablePrime(50)) | ||
| .limit(20) | ||
| .forEach(mp -> System.out.println(mp.bitLength() + ": " + mp)); | ||
| } | ||
| ``` | ||
|
|
||
| 무작정 성능을 향상시키기 위해 `parallel()` 를 사용하면<mark style="color:red;">, 위와 같이 아무것도 출력하지 못하면서 CPU는</mark> <mark style="color:red;"></mark><mark style="color:red;">`90%`</mark> <mark style="color:red;"></mark><mark style="color:red;">나 잡아먹는 상태가 무한히 계속되는 문제가 발생할 수 있다.</mark> 스트림 라이브러리가 이 파이프라인을 **병렬화하는 방법을 찾아내지 못했기 때문**이다 | ||
|
|
||
| > 🔖 **파이프라인 병렬화로 성능 개선을 할 수 없는 경우**\ | ||
| > 1\. 데이터 소스가 `Stream.iterate`인 경우\ | ||
| > 2\. 중간 연산으로 `limit` 을 사용하는 경우 | ||
| 위의 코드는 2가지의 문제 모두를 지니고 있다. | ||
|
|
||
| * 파이프라인 병렬화는 limit 이 있을 때, CPU 코어가 남는다면 원소를 몇개 더 처리한 후 제한된 개수 이후의 결과를 버려도 아무런 해가 없다고 가정한다. | ||
| * 계속 버려지기 때문에 계속 이전까지의 값을 다시 구해야 한다. | ||
|
|
||
| > 스트림 파이프라인을 마구잡이로 병렬화하면 성능이 오히려 끔찍하게 나빠질 수 있다. | ||
| **스트림 병렬화 + forEach** | ||
|
|
||
| 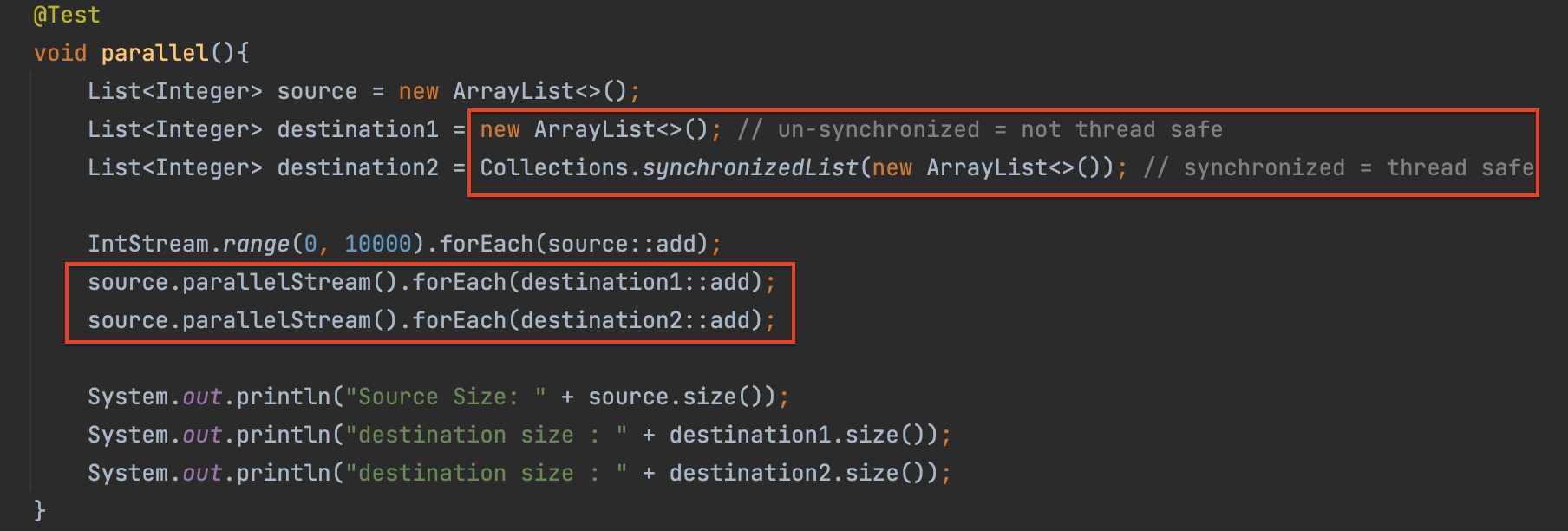 | ||
|
|
||
|  | ||
|
|
||
| ### 2) 스트림 병렬화는 어떤 경우 사용해야 할까? <a href="#undefined" id="undefined"></a> | ||
|
|
||
| {% hint style="success" %} | ||
| 대체로 스트림의 소스가 `ArrayList`, `HashMap`, `HashSet`, `ConcurrentHashMap`의 인스턴스거나 `배열`, `int 범위`, `long 범위`일 때 병렬화의 효과가 가장 좋다. | ||
| {% endhint %} | ||
|
|
||
| 해당 자료구조들은 아래와 같은 두 가지 공통점을 지닌다. | ||
|
|
||
| **1. 정확성** | ||
|
|
||
| 모두 데이터를 원하는 크기로 정확하고 손쉽게 나눌 수 있어 다수의 스레드에 일을 분배하기에 좋다. 나누는 작업은 `Spliterator` 를 통해 이루어지며, `Iterable` 과 `Stream` 에서 얻을 수 있다. | ||
|
|
||
|
|
||
|
|
||
| **2. 참조 지역성(locality of reference) 뛰어남** | ||
|
|
||
| 참조 지역성은, 다음과 같이 세가지로 나누어진다. | ||
|
|
||
| 1. 시간 지역성 : 최근에 참조된 주소는 **빠른 시간 내에 다시 참조**되는 특성 | ||
| 2. 공간 지역성 : 참조된 주소와 **인접한 주소의 내용이 다시 참조**되는 특성 | ||
| 3. 순차 지역성 : 데이터가 **순차적으로 엑세스** 되는 특성(공간 지역성) | ||
|
|
||
| <figure><img src="../../../../.gitbook/assets/napkin-selection (3).png" alt=""><figcaption></figcaption></figure> | ||
|
|
||
| > 🔖 **참조 지역성**\ | ||
| > 1\. `높음` : <mark style="color:red;">이웃한 원소의 참조들이 메모리에 연속해서 저장</mark>되어 있는 경우\ | ||
| > 2\. `낮음` : 참조들이 가리키는 실제 객체가 메모리에서 서로 떨어져 있는 경우 | ||
| 참조 지역성은, 요청할 데이터를 캐시 메모리에서 찾을 확률인 `Cache Hit Rate` 과도 비례한다. **참조 지역성이 높으면 캐시에서 데이터를 바로 찾을 수 있으므로 속도가 빨라지지만**, 낮다면 주 메모리에서 캐시로 다시 로드하는 과정이 필요하기 때문에 전송되어 오기만을기다리며, 대부분의 시간이 비어, 성능이 낮아진다. | ||
|
|
||
| **기본 타입의 배열**과 같은 경우, 데이터 자체가 메모리에 연속해서 저장되기 때문에, 참조 지역성 중에서도 공간 지역성이 좋아 `Cache Hit Rate` 이 가장 높다. | ||
|
|
||
| `ArrayList` 나 `Hash` 자료구조 또한 내부적으로 배열(해시 테이블)을 사용하기 때문에, 참조 지역성이 높다. | ||
|
|
||
| ```java | ||
| public class HashMap<K,V> extends AbstractMap<K,V> | ||
| implements Map<K,V>, Cloneable, Serializable { | ||
|
|
||
| transient Node<K,V>[] table; | ||
| } | ||
| ``` | ||
|
|
||
| 결론적으로, **다량의 데이터를 처리하는 벌크 연산을 병렬화 할 때는 반드시 참조 지역성을 고려**하도록 하자. | ||
|
|
||
|
|
||
|
|
||
| ## 3. 종단 연산과 병렬화 <a href="#undefined" id="undefined"></a> | ||
|
|
||
| > 종단 연산에서 수행하는 작업량이 파이프라인 전체 작업에서 상당 비중을 차지하면서 순차적인 연산이라면, 파이프라인 병렬 수행의 효과가 떨어진다. | ||
| 병렬화는 작업을 여러 스레드로 분할하여 동시에 처리함으로써 **성능 향상**을 도모하는 기법이다. 하지만 모든 스트림 작업이 병렬화에 적합하지는 않기 때문에, 병렬화를 적용할 때는 작업의 특성을 고려해야 한다. | ||
|
|
||
| ### **1) 병렬 수행에 적합한 연산들** | ||
|
|
||
| #### **축소(reduction) 연산** | ||
|
|
||
| **축소(reduction)** 연산은 여러 값을 하나로 줄이는 작업으로, **병렬화에 매우 적합하**다. 데이터의 일부분을 각각 다른 스레드에서 처리한 후 결합하기가 쉬운 작업들이 병렬화의 효과를 극대화할 수 있다. | ||
|
|
||
| * **적합한 축소 연산**: | ||
| * **`min()`**, **`max()`**: 최솟값, 최댓값 찾기. | ||
| * **`count()`**, **`sum()`**: 원소의 개수나 합을 계산하는 연산. | ||
| * 이들 연산은 쉽게 **쪼개서 각 부분을 처리**하고, 그 결과를 다시 **결합**하는 방식으로 성능을 높일 수 있습니다. | ||
|
|
||
| #### **조건부 반환 연산** | ||
|
|
||
| * 조건에 맞으면 바로 반환하는 **단락(short-circuiting) 연산**도 병렬화에 적합하다. | ||
| * **`anyMatch()`**: 조건을 만족하는 **하나의 요소라도** 찾으면 바로 종료. | ||
| * **`allMatch()`**, **`noneMatch()`**: 모든 요소가 특정 조건을 만족하는지 확인. | ||
|
|
||
| 이들 메서드는 조건이 만족되면 **즉시 종료**할 수 있어, 데이터 분할 후 일부만 확인해도 성능 향상이 가능하다. | ||
|
|
||
| #### **병렬화의 적용 예시 코드** | ||
|
|
||
| 다음은 **2부터 n까지의 소수를 구하는** 병렬화 코드이다. 숫자를 범위별로 나누고 각각의 스레드에서 소수인지 판별한 후 결과를 결합한다. | ||
|
|
||
| ```java | ||
| public long pi(long n) { | ||
| return LongStream.range(2, n) // 2부터 n-1까지의 숫자를 생성 | ||
| .parallel() // 병렬 처리 (성능 향상을 위해 사용) | ||
| .mapToObj(BigInteger::valueOf) // 각 숫자를 BigInteger로 변환 | ||
| .filter(i -> i.isProbablePrime(50)) // 소수인지 확률적으로 확인 (50번 테스트) | ||
| .count(); // 소수의 개수를 반환 | ||
| } | ||
| ``` | ||
|
|
||
| * **`parallel()`**: 스트림을 병렬 스트림으로 변환하여 병렬 처리를 수행한다. | ||
| * **효과**: | ||
| * 병렬화가 잘 적용되면 여러 숫자를 동시에 소수 판별하므로, 성능이 약 **5배 이상 향상**될 수 있다. | ||
| * 위 코드는 **쪼개기 쉬운 작업**이기 때문에 병렬화가 효과적이다. | ||
|
|
||
| ### **2) 병렬화의 조건과 주의사항** | ||
|
|
||
| #### **Spliterator와 병렬화 테스트** | ||
|
|
||
| * **Spliterator 재정의**: 커스텀 데이터 구조를 스트림으로 병렬 처리하려면, 데이터의 쪼개기와 탐색을 효율적으로 하기 위해 **Spliterator**를 재정의하는 것이 중요하다. | ||
| * **Spliterator**는 데이터를 분할(splitting)하고, 탐색(iteration)하는 인터페이스로, 병렬화를 잘 수행할 수 있도록 데이터를 분할하는 역할을 한다. | ||
| * **병렬화 성능 테스트**: 병렬 스트림으로 처리하는 경우, 항상 **성능 테스트**를 통해 실제로 병렬화가 효율적인지 검증해야 한다. 잘못된 병렬화는 성능을 **오히려 저하시킬 수 있다**. | ||
|
|
||
| #### **결합 법칙과 안전 실패 방지** | ||
|
|
||
| * **결합 법칙(Associativity)**: | ||
| * 병렬화에서는 여러 스레드가 작업한 결과를 최종적으로 **결합**해야 한다. 이때 사용되는 **accumulator**와 **combiner** 함수가 결합 법칙을 지켜야 병렬화된 작업의 결과가 정확하다. | ||
| * **간섭(Interference)**: | ||
| * 스트림 작업 중간에 **외부 상태**를 참조하거나 변경하는 것은 병렬화에서 안전 실패(safety failure)를 유발할 수 있다. 병렬화된 스트림 작업에서 외부 상태와의 간섭은 **예상치 못한 동작**을 초래하므로 피해야 한다. | ||
| * **상태를 갖지 않아야 함**: | ||
| * 병렬 연산에 사용되는 함수는 **상태를 갖지 않아야** 한다. 즉, 공유된 가변 상태를 사용하면 안 됩니다. 이를 지키지 않으면 병렬 스트림의 결과가 잘못될 수 있다. | ||
|
|
||
| ### **3) 잘못된 병렬화와 해결책** | ||
|
|
||
| #### **잘못된 병렬화의 문제점** | ||
|
|
||
| * **성능 저하**: 작업이 병렬화에 적합하지 않거나, 작업 간의 **경쟁 조건**이 발생하면 성능이 오히려 더 나빠질 수 있다. | ||
| * **예상치 못한 동작**: | ||
| * 병렬화된 작업에서 **공유 자원에 동기화 없이 접근**하면 잘못된 결과나 데이터 오염이 발생할 수 있다. | ||
| * 예를 들어, `Random` 클래스를 사용하면 내부적으로 **동기화**가 되어 있어 병렬화 성능이 나빠질 수 있다. | ||
|
|
||
| #### **병렬화에 적합한 Random 사용: `SplittableRandom`** | ||
|
|
||
| * **`SplittableRandom`**: | ||
| * 병렬화된 작업에서 난수를 생성할 때는 `SplittableRandom`을 사용하는 것이 좋다. | ||
| * <mark style="color:red;">**`Random`**</mark> <mark style="color:red;"></mark><mark style="color:red;">클래스는 내부적으로</mark> <mark style="color:red;"></mark><mark style="color:red;">**동기화**</mark><mark style="color:red;">를 사용하기 때문에, 병렬 처리를 할 경우</mark> <mark style="color:red;"></mark><mark style="color:red;">**경쟁 조건**</mark><mark style="color:red;">이 발생하여 최악의 성능을 보일 수 있다.</mark> | ||
| * `SplittableRandom`은 **병렬 환경에서 난수를 생성**하는 데 최적화된 클래스 | ||
|
|
||
| #### **코드 예제: SplittableRandom 사용** | ||
|
|
||
| ```java | ||
| import java.util.SplittableRandom; | ||
| import java.util.stream.IntStream; | ||
|
|
||
| public class ParallelRandomStream { | ||
| public static void main(String[] args) { | ||
| SplittableRandom random = new SplittableRandom(); | ||
|
|
||
| // 병렬 스트림을 사용하여 무작위 숫자 생성 및 출력 | ||
| IntStream.generate(() -> random.nextInt(100)) // 0부터 99 사이의 무작위 숫자 생성 | ||
| .parallel() // 병렬 처리 | ||
| .limit(10) // 10개의 숫자만 생성 | ||
| .forEach(System.out::println); | ||
| } | ||
| } | ||
| ``` | ||
|
|
||
| * **설명**: | ||
| * `SplittableRandom`은 병렬 처리에 최적화된 난수 생성기이므로, **병렬 스트림**에서 사용해도 성능 저하 없이 안전하게 난수를 생성할 수 있다. | ||
|
|
||
| #### **SplittableRandom과 Random 비교** | ||
|
|
||
| | 특성 | `Random` | `SplittableRandom` | | ||
| | ------------- | -------------------- | ----------------------- | | ||
| | **병렬 처리 최적화** | 동기화를 사용하여 병렬 처리에 부적합 | 병렬 처리에 최적화 (독립적인 분할 가능) | | ||
| | **동기화** | 내부 상태 보호를 위해 동기화 필요 | 동기화 불필요 | | ||
| | **난수 생성 방식** | 선형 합동 생성기 (LCG) | 분할 가능한 난수 생성기 | | ||
| | **병렬 스트림 사용** | 성능 저하 발생 가능 | 성능 저하 없이 사용 가능 | | ||
|
|
||
| ### **4) 요약 및 결론** | ||
|
|
||
| **적합한 종단 연산** | ||
|
|
||
| >  **축소(reduction) 연산** (`min()`, `max()`, `count()` 등)과 **조건부 반환 연산** (`anyMatch()`, `allMatch()`)은 **병렬화에 적합하다.** | ||
| 1. `reduce` | ||
| 2. `anyMatch`, `allMatch`, `noneMatch` | ||
| 3. **데이터를 쪼개고 결합하기 쉬운 작업**일수록 병렬화의 효과가 크다. | ||
|
|
||
| **나쁜 종단 연산** | ||
|
|
||
| `collect` 와 같이 컬렉션들을 합치는 부담이 큰 메서드는 병렬화에 적합하지 않다. | ||
|
|
||
| **병렬화 적용 시 주의사항**: | ||
|
|
||
| * **Spliterator**를 재정의하고 성능을 충분히 테스트한 후 병렬화를 적용해야 한다. | ||
| * **결합 법칙**과 **간섭 금지** 조건을 지켜야 한다. | ||
| * 병렬 연산에서는 **공유 상태**가 없는 함수만 사용해야 안전하다. | ||
|
|
||
| > **잘못된 병렬화의 문제 해결**: | ||
| * <mark style="color:red;">**Random**</mark> <mark style="color:red;"></mark><mark style="color:red;">대신</mark> <mark style="color:red;"></mark><mark style="color:red;">**SplittableRandom**</mark><mark style="color:red;">을 사용하여</mark> 병렬 환경에서 난수를 안전하게 생성한다. | ||
| * 병렬 스트림을 사용할 때는 항상 **성능 테스트**를 통해 병렬화가 효과적인지 확인해야 한다. | ||
|
|
||
| > **생각해봐야 할 부분** | ||
| * **병렬화가 항상 성능을 향상시키는가?**: | ||
| * 병렬화는 모든 경우에 성능을 향상시키지 않습니다. 작업의 **비용**, **데이터 크기**, **병렬 작업의 분할 용이성** 등을 고려하여 **병렬화 여부를 결정**해야 합니다. | ||
| * 예를 들어, 데이터 크기가 작거나 작업의 **오버헤드**가 클 경우, 병렬화를 적용하면 **성능이 오히려 저하**될 수 있습니다. | ||
| * **데이터의 결합이 잘 이루어지는가?**: | ||
| * 병렬화된 작업에서는 **데이터의 결합**이 정확해야 합니다. 잘못된 결합 방식은 **결과 오류**를 유발할 수 있습니다. 따라서 **결합 법칙**을 항상 준수해야 합니다. | ||
| * **병렬화 테스트**: | ||
| * **병렬화 효과**를 검증하기 위해서는 반드시 **성능 테스트**를 통해 실제 성능이 향상되는지 확인해야 합니다. 이를 통해 병렬화가 효율적인지 판단하고 최적화를 적용해야 합니다. | ||
|
|
||
| ## 📚 **핵심 정리** | ||
|
|
||
| > 무작정 병렬화를 한다고 속도가 빨라질 것이라 생각하지 말자. | ||
| `parallel stream` 의 오버헤드가 `stream` 보다 훨씬 크기 때문에, 이를 뛰어 넘을 정도로 병렬 처리가 효율적인 작업인 경우(ex) 빅데이터) 테스트를 해보고 사용하도록 하자. | ||
|
|
||
| * 병렬화 시 오동작 등의 부작용도 항상 고려해야 한다. | ||
| * 성능지표[^1]를 항상 유심히 관찰하자. | ||
|
|
||
|
|
||
|
|
||
| > 출처 및 참고 | ||
| > | ||
| > * [https://velog.io/@semi-cloud/Effective-Java-%EC%95%84%EC%9D%B4%ED%85%9C-48-%EC%8A%A4%ED%8A%B8%EB%A6%BC-%EB%B3%91%EB%A0%AC%ED%99%94%EB%8A%94-%EC%A3%BC%EC%9D%98%ED%95%B4%EC%84%9C-%EC%A0%81%EC%9A%A9%ED%95%98%EB%9D%BC](https://velog.io/@semi-cloud/Effective-Java-%EC%95%84%EC%9D%B4%ED%85%9C-48-%EC%8A%A4%ED%8A%B8%EB%A6%BC-%EB%B3%91%EB%A0%AC%ED%99%94%EB%8A%94-%EC%A3%BC%EC%9D%98%ED%95%B4%EC%84%9C-%EC%A0%81%EC%9A%A9%ED%95%98%EB%9D%BC) | ||
| > * [https://jake-seo-dev.tistory.com/514?category=906605](https://jake-seo-dev.tistory.com/514?category=906605) | ||
|
|
||
|
|
||
| [^1]: 성능 지표를 관찰하기 위한 다양한 **툴과 기법**이 있다. 이런 툴들은 애플리케이션의 **CPU 사용량**, **메모리 소비**, **응답 시간**, **스레드 상태** 등과 같은 **성능 지표**를 수집하고 분석할 수 있도록 도와준다.\ | ||
| 예시 : 와탭 |