This repository contains a simple Khmer Automatic Speech Recognition (ASR) project from scratch. Feel free to fork this repository, submit pull requests, or send us suggestions on what should be improved! I just do it for fun and celebrating my bd :D
-
YouTube Videos
- We crawl YouTube videos using
yt_dlpandffmpeg. - Instructions: Just follow the links to download the tools and refer to the given channel names for crawling.
- yt_dlp: Download yt_dlp
- ffmpeg: Download ffmpeg
- We crawl YouTube videos using
-
OpenSLR Dataset
- Alternatively, you can use the OpenSLR dataset, which is open-source.
- OpenSLR Dataset Link
-
Background Noise Removal
- We use Ultimate Vocal Remover for background noise removal.
- Ultimate Vocal Remover
- Separate code and model's files are provided in the folder
Background_Noise.
-
Chunking
- Automated chunking is performed using Python. For non-stratified results, manual checking with Audacity is recommended.
- Download Audacity
- Transcribe_New.py
- The script outputs three folders:
1_word,UNK(unknown), andnon-transcript. - Manual checking is recommended for perfect transcription accuracy.
- The script outputs three folders:
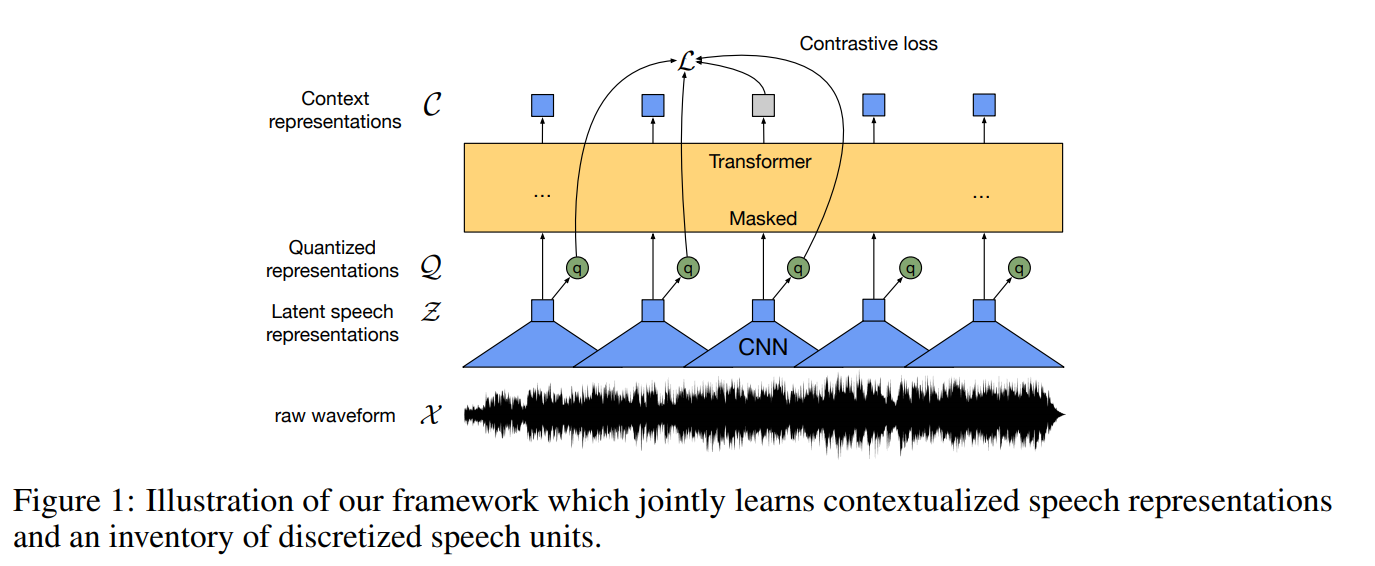
- About Wav2Vec2
- Wav2Vec2 is a state-of-the-art model developed by Facebook AI (now Meta AI) for ASR. It converts raw audio waveforms into meaningful text.
- The model was trained using connectionist temporal classification (CTC), so the output has to be decoded using
Wav2Vec2CTCTokenizer.
- WER (Word Error Rate)
- WER is a metric used to evaluate the quality of transcriptions produced by ASR systems.
- In many applications, it is of interest to estimate WER given a pair of a speech utterance and a transcript.

- This application records voice or inputs a file and returns the transcript text!
- If you face any problems about the model weight, this might help :
- Seanghay Yath
- Vituo Phy 1
- Vituo Phy 2