You can find our paper Author's sentiment prediction
Mohaddeseh Bastan, Mahnaz Koupaee, Youngseo Son, Richard Sicoli, Niranjan Balasubramanian. COLING2020
We introduce PerSenT, a crowd-sourced dataset that captures the sentiment of an author towards the main entity in a news article. This dataset contains annotation for 5.3k documents and 38k paragraphs covering 3.2k unique entities.
In the following example we see a 4-paragraph document about an entity (Donald Trump). Each paragraph is labeled separately and finally the author's sentiment towards the whole document is mentioned in the last row.

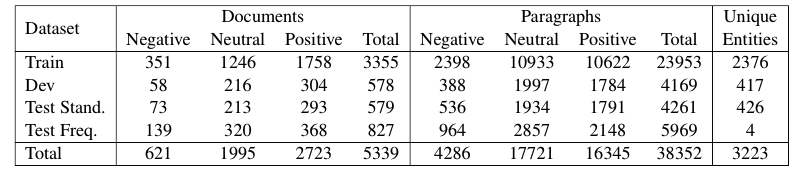
To split the dataset, we separated the entities into 4 mutually exclusive sets. Due to the nature of news collections, some entities tend to dominate the collection. In our collection,there were four entities which were the main entity in nearly 800 articles. To avoid these entities from dominating the train or test splits, we moved them to a separate test collection. We split the remaining into a training, dev, and test sets at random. Thus our collection includes one standard test set consisting of articles drawn at random (Test Standard), while the other is a test set which contains multiple articles about a small number of popular entities (Test Frequent).
You can download the data set URLs from here
The processed version of the dataset which contains used paragraphs, document-level, and paragraph-level labels can be download separately as train, dev, random test, and fixed test.
To recreat the results from the paper you can follow the instructions in the readme file from the source code.
Please use the following bibtex entry:
@inproceedings{bastan-etal-2020-authors,
title = "Author{'}s Sentiment Prediction",
author = "Bastan, Mohaddeseh and
Koupaee, Mahnaz and
Son, Youngseo and
Sicoli, Richard and
Balasubramanian, Niranjan",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2020.coling-main.52",
doi = "10.18653/v1/2020.coling-main.52",
pages = "604--615",
}