Releases: Terry-Su/blogs
邮件订阅最后一篇:彻底搞懂React源码调度原理(Concurrent模式)
首先感谢各位朋友的订阅,尽管我无法通过github知道各位姓谁名谁。
之前咨询了github官方是否支持查看"release-only" watch有哪些用户或有多少用户,遗憾的是官方回复并不支持此功能。
所以这次对订阅博客方式做了调整,不再支持“watch release-only”发邮件订阅模式,不过各位可通过下面任一方式订阅:
- 知乎
- 微信公众号:苏溪云的博客
自上一篇写关于diff的文章到现在已经过了二十天多,利用业余时间和10天婚假的闲暇,终于搞懂了React源码中的调度原理。当费劲一番周折终于调试到将更新与调度任务连接在一起的核心逻辑那一刻,忧愁的嘴角终于露出欣慰的微笑。

最早之前,React还没有用fiber重写,那个时候对React调度模块就有好奇。而现在的调度模块对于之前没研究过它的我来说更是带有一层神秘的色彩,色彩中朦胧浮现出两个字:“困难”。
截至目前react的Concurrent(同时)调度模式依然处在实验阶段(期待中),还未正式发布,但官网已有相关简单介绍的文档,相信不久之后就会发布(参考hooks)。
在研究的时候也查阅了网上的相关资料,但可参考的不多。原因一个是调度模块源码变动较大,之前的一些文章和现在的源码实现对不上(不过很多文章对时间切片和优先级安排的概念讲解很到位),另一个是现在可参考的列出调度流程相应源码的文章几乎没有。
所以本文主要是通过字自己对源码的阅读,推理和验证,加上大量时间作为催化剂,将React源码中的调度原理展现给各位读者。
React使用当前最新版本:
16.13.1今年会写一个“搞懂React源码系列”,把React最核心的内容用最易懂的方式讲清楚。2020年搞懂React源码系列:
- React Diff原理
- (当前)React 调度原理
- 搭建阅读React源码环境-支持React所有版本断点调试细分文件
- React Hooks原理
同步调度模式
React目前只有一种调度模式:同步模式。只有等Concurrent调度模式正式发布,才能使用第两种模式。
没有案例的讲解是没有灵魂的。我们先来看一个此处和后续讲优先级都将用到的案例:
假设有一个按钮和有8000个包含同样数字的文本标签,点击按钮后数字会加2。(使用8000个文本标签是为了加长react单次更新任务的计算时间,以便直观观察react如何执行多任务)
我们用类组件实现案例。
渲染内容:
<div>
<button ref={this.buttonRef} onClick={this.handleButtonClick}>增加2</button>
<div>
{Array.from(new Array(8000)).map( (v,index) =>
<span key={index}>{this.state.count}</span>
)}
</div>
</div>添加按钮点击事件:
handleButtonClick = () => {
this.setState( prevState => ({ count: prevState.count + 2 }) )
}并在componentDidMount中添加如下代码:
const button = this.buttonRef.current
setTimeout( () => this.setState( { count: 1 } ), 500 )
setTimeout( () => button.click(), 500 )ReactDOM初始化组件:
ReactDOM.render(<SyncSchedulingExample />, document.getElementById("container"));添加2个setTimeout是为了展示同步模式的精髓: 500毫秒后有两个异步的setState的任务,由于react要计算和渲染8000个文本标签,那么任何一个任务光计算的时间都要几百毫秒,那么react会如何处理这两个任务?
运行案例后,查看Chrome性能分析图:
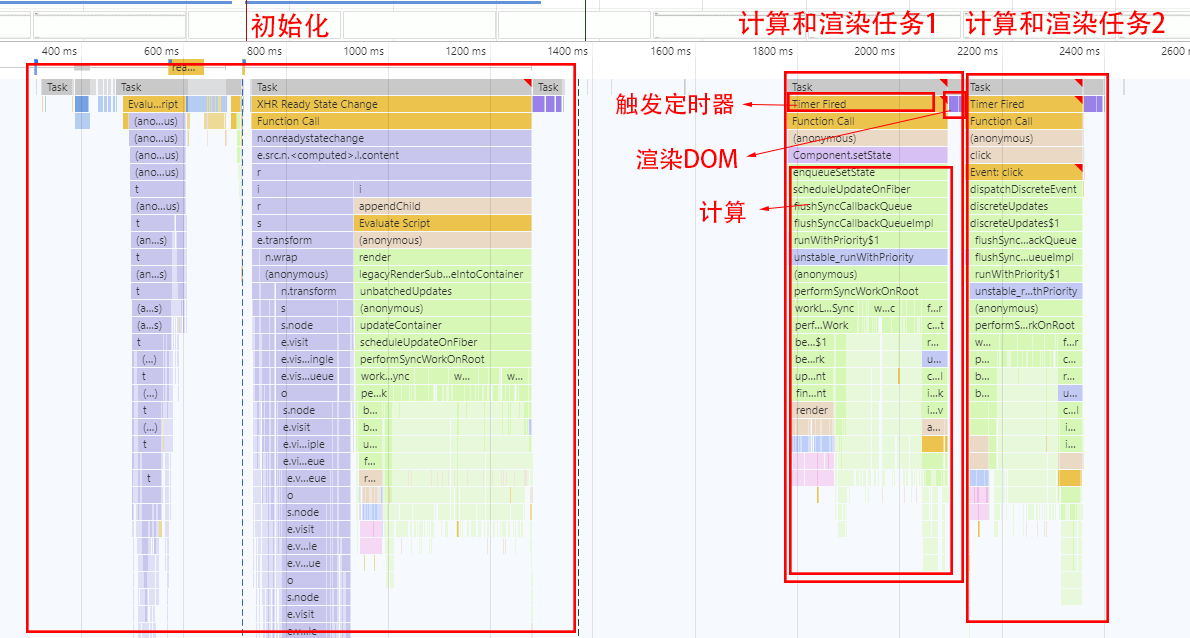
从结果可知,尽管两个任务理应“同时”运行,但react会先把第一个任务执行完后再执行第二个任务,这就是react同步模式:
多个任务时,react都会按照任务顺序一个一个执行,它无法保证后面的任务能在本应执行的时间执行。(其实就是JS本身特性EventLoop的展现。比如只要一个while循环足够久,理应在某个时刻执行的方法就会被延迟到while循环结束后才运行。)
Concurrent(同时)调度模式
Concurrent调度模式是一种支持同时执行多个更新任务的调度模式。
它的特点是任何一个更新任务都可以被更高优先级中断插队,在高优先级任务执行之后再执行。
很重要的一点,"同时执行多个更新任务"指的是同时将多个更新任务添加到React调度的任务队列中,然后React会一个个执行,而不是类似多线程同时工作那种方式。
如何理解模式名字:Concurrent(同时)?
React官网用了一个很形象的版本管理案例来形容“同时”模式。
当我们没有版本管理软件的时候,若一个人要修改某个文件,需要通知其他人不要修改这个文件,只有等他修改完之后才能去修改。无法做到多个人同时修改一个文件。
但有了版本管理软件,我们每个人都可以拉一个分支,修改同一个文件,然后将自己修改的内容合并到主分支上,做到多人“同时”修改一个文件。
所以,如果React也能做到“同时”执行多个更新任务,做到每一个更新任务的执行不会阻塞其他更新任务的加入,岂不是很方便。
这可以看作是“同时”模式名字的由来。
同时调度模式的应用场景
下方为React团队成员Dan在做同时模式分享时用的DEMO。同样的快速输入几个数字,在同步模式和同时模式可发现明显区别。
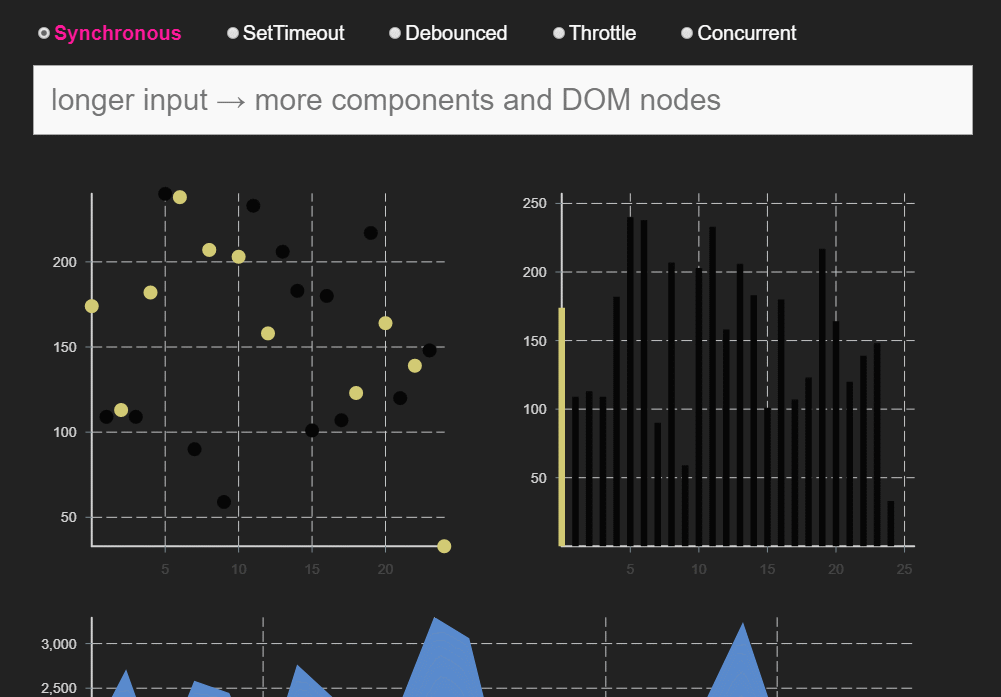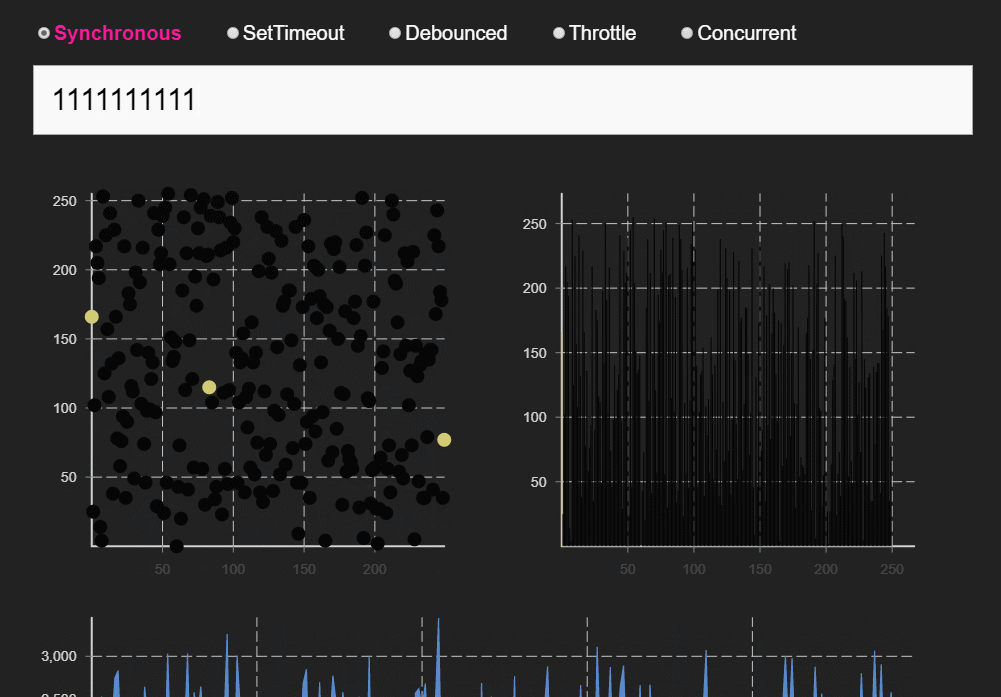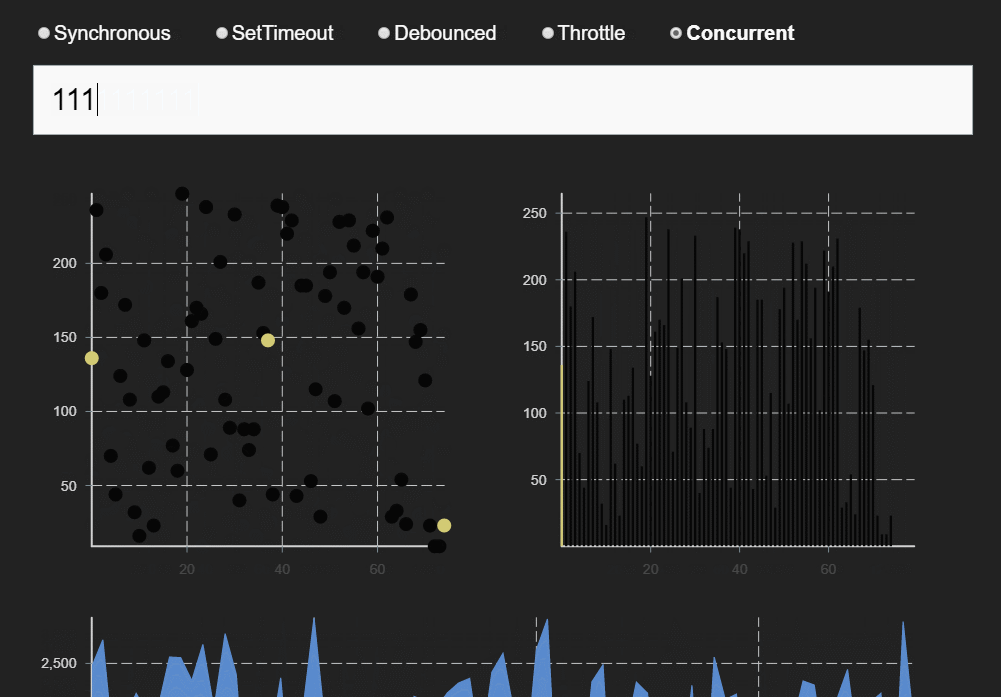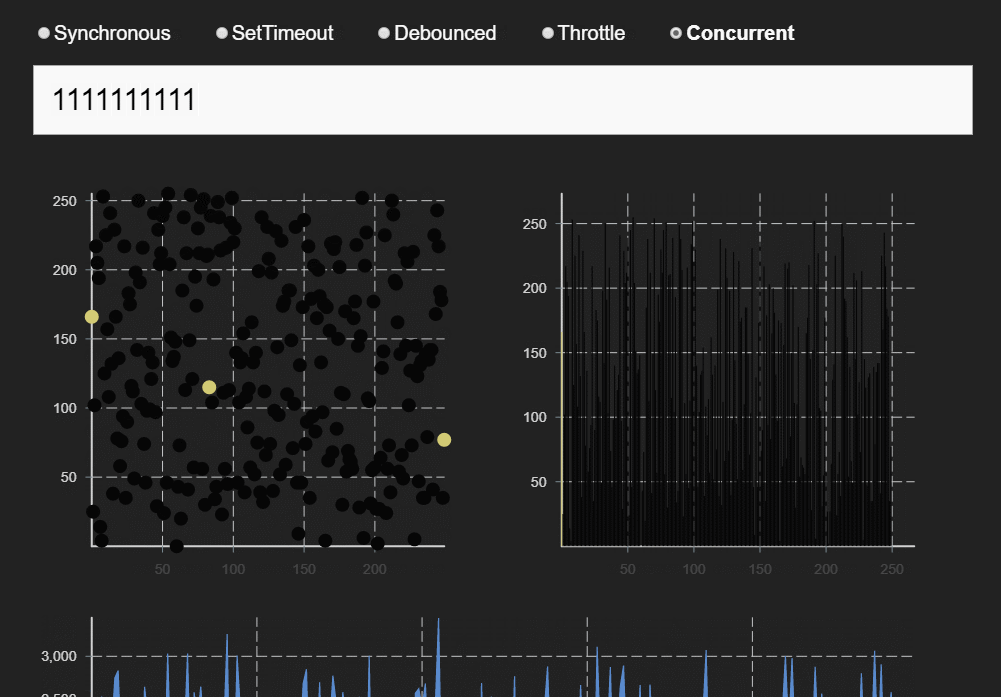
同步模式下,卡顿现象明显,并且会出现UI阻塞状态:Input中的光标不再闪烁,而是卡住。
同时模式下,只有输入内容较长才会出现稍微的卡顿情况和UI阻塞。性能得到明显改善。
同时模式很好的解决了连续频繁更新状态场景下的卡顿和UI阻塞问题。当然,同时模式下还有其他实用功能,比如Suspense,因为本文主要讲调度原理和源码实现,所以就不展开讲Suspense了。
同步调度模式如何实现
React是如何实现同步调度模式的?这也是本文的核心。接下来将先讲时间切片模式,以及React如何实现时间切片模式,然后再讲调度中的优先级,以及如何实现优先级插队,最后讲调度的核心参数:expirationTime(过期时间)。
时间切片
什么是时间切片
最早是从Lin Clark分享的经典Fiber演讲中了解到的时间切片。时间切片指的是一种将多个粒度小的任务放入一个个时间切片中执行的一种方法。
时间切片的作用
在刚执行完一个时间切片准备执行下一个时间切片前,React能够:
-
判断是否有用户界面交互事件和其他需要执行的代码,比如点击事件,有的话则执行该事件
-
判断是否有优先级更高的任务需要执行,如果有,则中断当前任务,执行更高的优先级任务。也就是利用时间前片来实现高优先级任务插队。
即时间切片有两个作用:
-
在执行任务过程中,不阻塞用户与页面交互,立即响应交互事件和需要执行的代码
-
实现高优先级插队
React源码如何实现时间切片
- 首先在这里引入当前React版本中的一段注释说明:
// Scheduler periodically yields in case there is other work on the main
// thread, like user events. By default, it yields multiple times per frame.
// It does not attempt to align with frame boundaries, since most tasks don't
// need to be frame aligned; for those that do, use requestAnimationFrame.
let yieldInterval = 5;
注释对象是声明yieldInterval变量的表达式,值为5,即5毫秒。其实这就是React目前的单位时间切片长度。
注释中说一个帧中会有多个时间切片(显而意见,一帧~=16.67ms,包含3个时间切片还多),切片时间不会与帧对齐,如果要与帧对齐,则使用requestAnimationFrame。
从2019年2月27号开始,React调度模块移除了之前的requestIdleCallback腻子脚本相关代码。
所以在一些之前的调度相关文章中,会提到React如何使用requestAnimationFrame实现requestIdleCallback腻子脚本,以及计算帧的边界时间等。因为当时的调度源码的确使用了这些来实现时间切片。不过现在的调度模块代码已精简许多,并且用新的方式实现了时间切片。
- 了解时间切片实现方法前需掌握的知识点:
Message Channel:浏览器提供的一种数据通信接口,可用来实现订阅发布。其特点是其两个端口属性支持双向通信和异步发布事件(port.postMessage(...))。
const channel = new MessageChannel()
const port1 = channel.port1
const port2 = channel.port2
port1.onmessage = e => { console.log( e.data ) }
port2.postMessage('from port2')
console.log( 'after port2 postMessage' )
port2.onmessage = e => { console.log( e.data ) }
port1.postMessage('from port1')
console.log( 'after port1 postMessage' )
// 控制台输出:
// after port2 postMessage
// after port1 postMessage
// from port2
// from port1Fiber: Fiber是一个的节点对象,React使用链表的形式将所有Fiber节点连接,形成链表树,即虚拟DOM树。
当有更新出现,React会生成一个工作中的Fiber树,并对工作中Fiber树上每一个Fiber节点进行计算和diff,完成计算工作(React称之为渲染步骤)之后,再更新DOM(提交步骤)。
- 下面让我们来看React究竟如何实现时间切片。
首先React会默认有许多微小任务,即所有的工作中fiber节点。
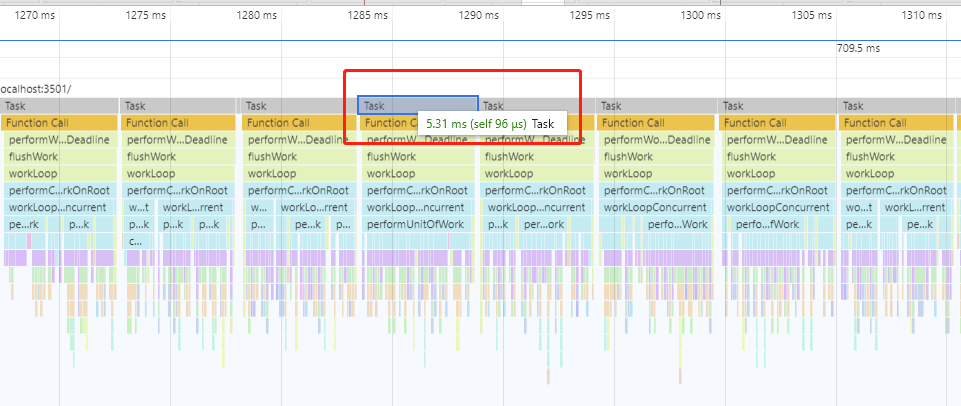
在执行调度工作循环和计算工作循环时,执行每一个工作中Fiber。但是,有一个条件是每隔5毫秒,会跳出工作循环,运行一次异步的MessageChannel的port.postMessage(...)方法,检查是否存在事件响应、更高优先级任务或其他代码需要执行,如果有则执行,如果没有则重新创建工作循环,执行剩下的工作中Fiber。
但是,为什么性能图上显示的切片不是精确的5毫秒?
因为一个时间切片中有多个工作中fiber执行,每执行完一个工作中Fiber,都会检查开始计时时间至当前时间的间隔是否已超过或等于5毫秒,如果是则跳出工作循环,但算上检查的最后一个工作中fiber本身执行也有一段时间,所以最终一个时间切片时间一定大于或等于5毫秒。
时间切片和其他模块的实现原理对应源码位于本文倒数第二章节“源码实探”。
将描述和实际源码分开,是为了方便阅读。先用大白话把原理实现流程讲出来,不放难懂的源码,最后再贴出对应源码。
如何调度一个任务
讲完时间切片,就可以了解React如何真正的调度一个任务了。

requestIdleCallback(callback, { timeout: number })是浏览器提供的一种可以让回调函数执行在每帧(上图2个vsync之间即为1帧)末尾的空闲阶段的方法,配置timeout后,若多帧持续没有空闲时间,超过timeout时长后,该回调函数将立即被执行。
现在的React调度模块虽没有使用requestIdleCallback,但充分吸收了requestIdleCallback的理念。其unstable_scheduleCallback(priorityLevel, callback, { timeout: number })就是类似的实现,不过是针对不同优先级封装的一种调度任务的方法。
在讲调度流程前先简单介绍调度中用到的相关参数:
-
当前Fiber树的root:拥有属性“回调函数”
-
React中的调度模块的任务: 拥有属性 “优先级,回调函数,过期时间”
-
过期时间标记:源码中expirationTime有两种类型,一种是标记类型:一个极大值,大小与时长成反比,可以用来作优先级标记,值越大,优先级越高,比如:
1073741551;另一种是从网页加载开始计时的具体过期时间:比如8000毫秒)。具体内容详见后面的expirationTime章节 -
DOM调度配置: 因为react同时支持web端dom和移动端native两种,核心算法一致,但有些内容是两端独有的,所以有的模块有专门的DOM配置和Native配置。我们这里将用到调度模块的DOM配置
-
requestHostCallback:DOM调度配置中使用Message Channel异步执行回调函数的方法
接下来看React如何调度一个任务。
初始化
-
当出现新的更新,React会运行一个确保root被安排任务的函数。
-
当root的回调函数为空值且新的更新对应的过期时间标记是异步类型,根据当前时间和过期时间标记推断出优先级和计算出timeout,然后根据优先级、timeout, 结合执行工作的回调函数,新建一个任务(这里就是
scheduleCallback),将该任务放入任务队列中,调用DOM调度配置文件中的requestHostCallback,回调函数为调度中心的清空任务方法。
运行任务
requestHostCallback调用MessageChannel中的异步函数:port.postMessage(...),从而异步执行之前另一个端口port1订阅的方法,在该方法中,执行requestHostCallback的回调函数,即调度中心的清空任务方法。
2.清空任务方法中,会执行调度中心的工作循环,循环执行任务队列中的任务。
有趣的是,工作循环并不是执行完一次任务中的回调函数就继续执行下一个任务的回调函数,而是执行完一个任务中的回调函数后,检测其是否返回函数。若返回,则将其作为任务新的回调函数,继续进行工作循环;若未返回,则执行下一个任务的回调函数。
并且工作循环中也在检查5毫秒时间切片是否到期,到期则重新调port.postMessage(...)。
- 任务的回调函数是一个执行同时模式下root工作的方法。执行该方法时将循环执行工作中fiber,同样使用5毫秒左右的时间切片进行计算和diff,5毫秒时间切片过期后就会返回其自身。
完成任务
-
在执行完所有工作中fiber后,React进入提交步骤,更新DOM。
-
任务的回调函数返回空值,调度工作循环因此(运行任务步骤中第二点:若任务的回调函数执行后返回为空,则执行下一个任务)完成此任务,并将此任务从任务队列中删除。
如何实现优先级
目前有6种优先级(从高到低排序):
| 优先级类型 | 使用场景 |
|---|---|
| 立即执行ImmediatePriority | React内部使用:过期任务立即同步执行;用户自定义使用 |
| 用户与页面交互UserBlockingPriority | React内部使用:用户交互事件生成此优先级任务;用户自定义使用 |
| 普通NormalPriority | React内部使用:默认优先级;用户自定义使用 |
| 低LowPriority | 用户自定义使用 |
| 空闲IdlePriority | 用户自定义使用 |
| 无NoPriority | React内部使用:初始化和重置root;用户自定义使用 |
| 表格中列出了优先级类型和使用场景。React内部用到了除低优先级和空闲优先级以外的优先级。理论上,用户可以自定义使用所有优先级,使用方法: |
React.unstable_scheduleCallback(priorityLevel, callback, { timeout: <number> })不同优先级的作用就是让高优先级任务优先于低优先级任务执行,并且由于时间切片的特性(每5毫秒执行一次异步的port.postMessage(...),在执行相应回调函数前会执行检测到的需要执行的代码)高优先级任务的加入可以中断正在运行的低优先级任务,先执行完高优先级任务,再重新执行被中断的低优先级让任务。
高优先级插队也是同时调度模式的核心功能之一。
高优先级插队
接下来,使用类似同步模式代码的插队案例。
渲染内容:
<div>
<button ref={this.buttonRef} onClick={this.handleButtonClick}>增加2</button>
<div>
{Array.from(new Array(8000)).map( (v,index) =>
<span key={index}>{this.state.count}</span>
)}
</div>
</div>添加按钮点击事件:
handleButtonClick = () => {
this.setState( prevState => ({ count: prevState.count + 2 }) )
}并在componentDidMount中添加如下代码(不同之处,第二次setTimeout的时间由500改为600):
const button = this.buttonRef.current
setTimeout( () => this.setState( { count: 1 } ), 500 )
setTimeout( () => button.click(), 600)ReactDOM初始化组件(不同之处,使用React.createRoot开启Concurrent模式):
ReactDOM.createRoot( document.getElementById('container') ).render( <ConcurrentSchedulingExample /> )为什么第二次setTimeout的时间由500改为600?
因为是为了展示高优先级插队。第二次setTimeout使用的用户交互优先级更新,晚100毫秒,可保证第...
搞懂React源码系列-React Diff原理

时隔2年,重新看React源码,很多以前不理解的内容现在都懂了。本文将用实际案例结合相关React源码,集中讨论React Diff原理。使用当前最新React版本:16.13.1。
另外,今年将写一个“搞懂React源码系列”,把React最核心内容用最通俗易懂地方式讲清楚。2020年搞懂React源码系列:
-
React Diff原理
-
React 调度原理
-
搭建阅读React源码环境-支持所有版本断点调试
-
React Hooks原理
在讨论Diff算法前,有必要先介绍React Fiber,因为React源码中各种实现都是基于Fiber,包括Diff算法。当然,熟悉React Fiber的朋友可跳过Fiber介绍。
Fiber简介
Fiber并不复杂,但如果要全面理解,还是得花好一段时间。本文主题是diff原理,所以这里仅简单介绍下Fiber。
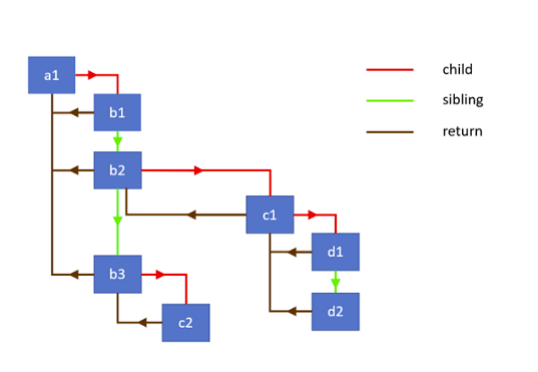
Fiber是一个抽象的节点对象,每个对象可能有子Fiber(child)和相邻Fiber(child)和父Fiber(return),React使用链表的形式将所有Fiber节点连接,形成链表树。
Fiber还有副作用标签(effectTag),比如替换Placement(替换)和Deletion(删除),用于之后更新DOM。
值得注意的是,React diff中,除了fiber,还用到了基础的React元素对象(如: 将<div>foo</div>编译后生成的对象: { type: 'div', props: { children: 'foo' } } )。
Diff 过程
React源码中,关于diff要从reconcileChildren(...)说起。
总流程:

流程图中, 显示源码中用到的函数名,省略复杂参数。“新内容”即被比较的新内容,它可能是三种类型:
-
对象: React元素
-
字符串或数字: 文本
-
数组:数组元素可能是React元素或文本
新内容为React元素
我们先以新内容为React元素为例,全面的调试一遍代码,将之后会重复用到的方法在此步骤中讲解,同时以一张流程图作为总结。
案例:
function SingleElementDifferentTypeChildA() { return <h1>A</h1> }
function SingleElementDifferentTypeChildB() { return <h2>B</h2> }
function SingleElementDifferentType() {
const [ showingA, setShowingA ] = useState( true )
useEffect( () => {
setTimeout( () => setShowingA( false ), 1000 )
} )
return showingA ? <SingleElementDifferentTypeChildA/> : <SingleElementDifferentTypeChildB/>
}
ReactDOM.render( <SingleElementDifferentType/>, document.getElementById('container') )从第一步reconcileChildren(...)开始调试代码,无需关注与diff不相关的内容,比如renderExpirationTime。左侧调试面板可看到对应变量的类型。

此处:
-
workInProgress: 父级Fiber -
current.child: 处于比较中的旧内容对应fiber -
nextChildren: 即处于比较中的新内容, 为React元素,其类型为对象。
在Diff时,比较中的旧内容为Fiber,而比较中的新内容为React元素、文本或数组。其实从这一步已经可以看出,React官网的diff算法说明和实际代码是实现差别较大。

因为新内容为对象,所以继续执行reconcileSingleElement(...)和placeSingleChild(...)。
我们先看placeSingleChild(...):
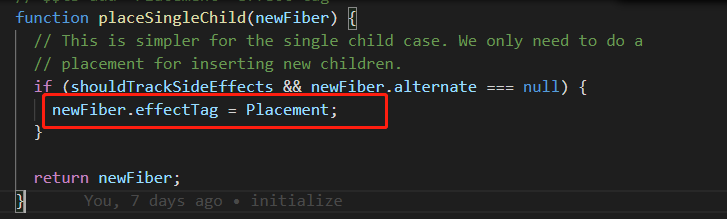
placeSingleChild(...)的作用很简单,给differ后的Fiber添加副作用标签:Placement(替换),表明在之后需要将旧Fiber对应的DOM元素进行替换。
继续看 reconcileSingleElement(...):

此处正式开始diff(比较),child为旧内容fiber,element为新内容,它们的元素类型不同。


因为类型不同,React将“删除”旧内容fiber以及其所有相邻Fiber(即给这些fiber添加副作用标签 Deletion(删除)), 并基于新内容生成新的Fiber。然后将新的Fiber设置为父Fiber的child。
到此,一个新内容为React元素的且新旧内容的元素类型不同的Diff过程已经完成。
那如果新旧内容的元素类型相同呢?
编写类似案例,我们可以得到结果

userFiber(...):

userFiber(...)的主要作用是基于旧内容fiber和新内容的属性(props)克隆生成一个新内容fiber,这也是所谓的fiber复用。
所以当新旧内容的元素类容相同,React会复用旧内容fiber,结合新内容属性,生成一个新的fiber。同样,将新的fiber设置位父fiber的child。
新内容为React元素的diff流程总结:

新内容为文本
当新内容为文本时,逻辑与新内容为React元素时类似:

新内容为数组
使用案例:
function ArrayComponent() {
const [ showingA, setShowingA ] = useState( true )
useEffect( () => {
setTimeout( () => setShowingA( false ), 1000 )
} )
return showingA ? <div>
<span>A</span>
<span>B</span>
</div> : <div>
<span>C</span>
D
</div>
}
ReactDOM.render( <ArrayComponent/>, document.getElementById('container') )
若新内容为数组,需reconcileChildrenArray(...):

for循环遍历新内容数组,伪代码(用于理解):
for ( let i = 0, oldFiber; i < newArray.length; ) {
...
i++
oldFiber = oldFiber.sibling
}遍历每个新内容数组元素时:

updateSlot(...):

因为newChild的类型为object, 所以:

updateElement(...):
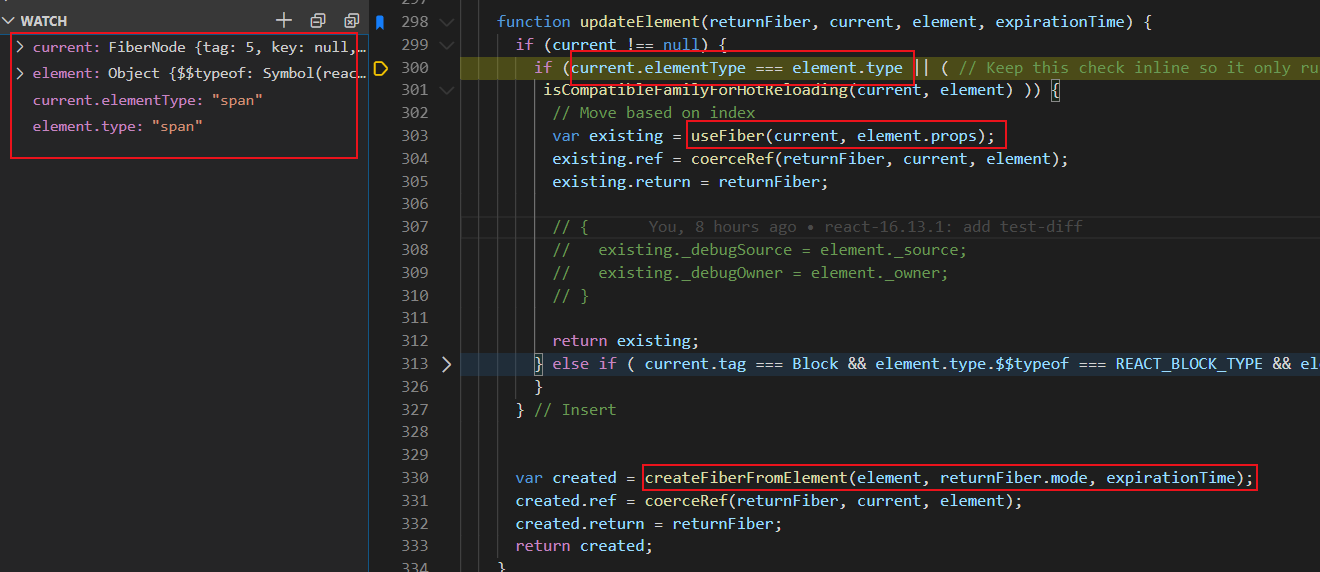
updateElement(...)与reconcileSingleElement(...)核心逻辑一致:
-
若新旧内容元素类型一致,则克隆旧fiber,结合新内容生成新的fiber
-
若不一致,则基于新内容创建新的fiber。
同理,updateTextNode(...):
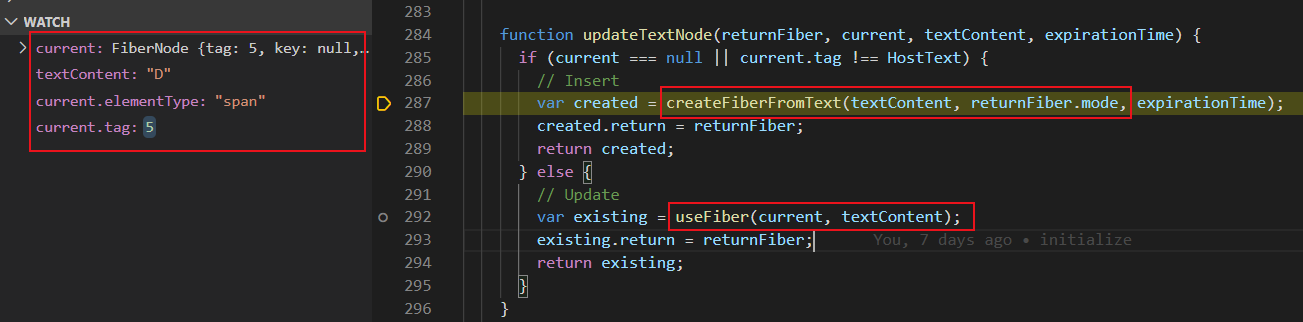
updateTextNode(...)与reconcileSingleTextNode(...)核心逻辑一致:
-
若旧内容fiber的标签不是
HostText,则基于新内容文本创建新的fiber -
若是
HostText, 则克隆旧fiber,结合新内容文本生成新的fiber
在本案例中,新内容数组for循环完成后:

因为新旧内容数组的长度一致,所以直接返回第一个新的fiber。然后同上,React将新的fiber设为父fiber的child。
不过若新内容数组长度与旧内容fiber及其相邻fiber的总个数不一致,React如何处理?
编写类似案例。
若新内容数组长度更短:

React将删除多余的旧内容fiber的相邻fiber。
若新内容数组长度更长:
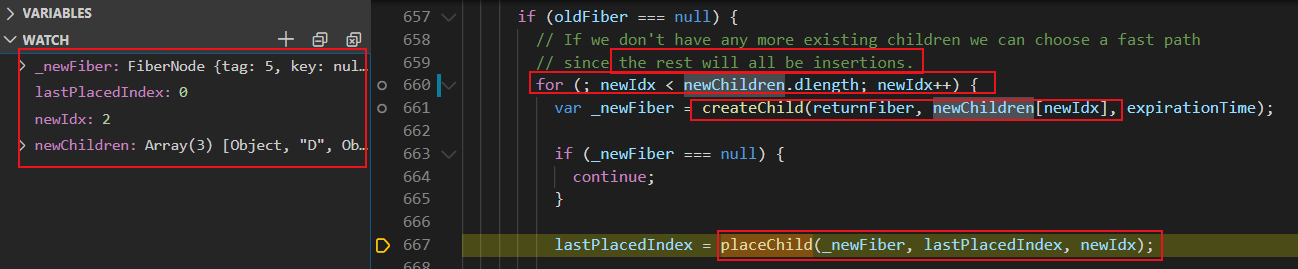
React将遍历多余的新内容数组元素,基于新内容数组元素创建的新的fiber,并添加副作用标签 Placement(替换)。
新内容为数组时的diff流程总结:

总结
通过React源码研究diff算法时,仅调试分析相关代码,能比较容易的得出答案。
Diff的三种情况:
-
新内容为React元素
-
新内容为文本
-
新内容为数组
-
Diff时若比较结果相同,则复用旧内容Fiber,结合新内容生成新Fiber;若不同,仅通过新内容创建新fiber。
-
然后给旧内容fiber添加副作用替换标签,或者给旧内容fiber及其所有相邻元素添加副作用删除标签。
-
最后将新的(第一个)fiber设为父fiber的child。
参考资料
-
The how and why on React’s usage of linked list in Fiber to walk the component’s tree: https://medium.com/react-in-depth/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-67f1014d0eb7
-
[译]深入React fiber架构及源码: https://zhuanlan.zhihu.com/p/57346388
-
Inside Fiber: in-depth overview of the new reconciliation algorithm in React: https://medium.com/react-in-depth/inside-fiber-in-depth-overview-of-the-new-reconciliation-algorithm-in-react-e1c04700ef6e
感谢你花时间阅读这篇文章。如果你喜欢这篇文章,欢迎点赞、收藏和分享,让更多的人看到这篇文章,这也是对我最大的鼓励和支持!
欢迎通过微信(扫描下方二维码)订阅我的博客。

轻松学会HTTP缓存(强缓存,协商缓存)
若读者对“强缓存”,“协商缓存”字眼非常熟悉,但又不知道他们具体是什么,亦或有读者还不了解HTTP缓存,那么本文将为读者一一讲解。
HTTP缓存流程
在介绍什么是强缓存、协商缓存前,让我们先了解HTTP缓存的流程,因为强缓存、协商缓存只是其中2步。

强缓存
“检查缓存是否过期”一步即强缓存。若缓存未过期,直接使用浏览器本地缓存,不用请求服务器。
检查缓存是否过期依据请求报文中的2种首部:过期时间Expires和有效时间Cache-Control:max-age。例子:
Expires: Fri, 05, Jul, 2020, 05:00:00 GMTCache-Control: max-age=60000
前者为缓存具体的过期时间,后者为缓存有效期。Cache-Control: max-age的优先级高于Expires。
协商缓存
“协商缓存”可以理解为一个动作:“与服务器协商是否更新缓存”。
当检查到缓存已过期,缓存端需要与服务器协商是否更新缓存。在请求报文中,用于协商的条件类首部也有2种,时间再验证If-Modified-Since和实体标签再验证If-No-Matched。若条件为真,服务器会返回新文档给缓存。否则,服务器返回304(Not Modified)。它们的格式为:
If-Modified-Since: <date>If-None-Matched: <tags>
日期再验证If-Modified-Since从字面即可理解:如何从某个时间之后文档被修改过。
实体标签再验证If-None-Matched同样可理解为:若缓存端的实体标签Etag(Entity Tag)与服务器不匹配。
实体标签是什么? 这里要从既然有了日期再验证为何还需要实体标签验证说起。
考虑一种特殊情况,若验证时,发现服务器上的文档被重写过文件修改时间,但内容不变,那这个时候日期再验证不通过,但实际并没有必要更新文档。所以引入了实体标签验证。实体标签Etag是为文档提供的特殊标签,格式为字符串,可看作唯一id。
若实体标签再验证不通过,服务器会返回新文档和新的Etag给缓存。
实体标签再验证的优先级高于日期再验证。
客户端刷新和重载
那么客户端的刷新和重载如何影响HTTP缓存?事实上,每个浏览器都由自己的一套处理机制。一般来说,普通刷新不会影响缓存,但强制刷新(重载)会让缓存失效,重新向请求服务器文档。
实践
光有理论没有实践验证肯定不够。此处使用一个案例体验协商缓存。
新建一个文件夹,新建index.html, 内容为“Test Cache”。使用serve将该文件夹静态服务化。打开Chrome,新建标签页,打开开发人员工具,切换到网络模块,然后打开服务化后的地址: http://localhost:5000。

可看到服务返回状态为200。
接下来刷新页面。

服务器返回状态变为304(Not Modified)。

请求首部用的是实体标签再验证If-None-Match:<tag>。

响应首部返回的Etag与请求中的Etag相同。
总结
HTTP缓存的2个要点就是:
- 检查缓存是否过期(强缓存)
- 若缓存过期,与服务器协商是否更新缓存(协商缓存)。
而这2点每个都包含相关的2个报文请求首部:
- 强缓存:过期时间
Expires和有效期Cache-Control: max-age - 协商缓存:日期再验证
If-Modified-Since和实体标签再验证If-Not-Matched
参考资料
- 《HTTP权威指南》 > 第7章 > 缓存
- 强缓存和协商缓存区别和过程
感谢你花时间阅读这篇文章。欢迎通过微信(扫描下方二维码)或Github订阅我的博客。
看完Webpack源码,我学到了这些
继React,Vue,这是第三个着重阅读源码的前端项目-Webpack。本文主要以: WHY: 为何要看Webpack源码 HOW: 如何阅读Webpack源码 WHAT: 看完源码后...
点击阅读
使用React手写一个对话框或模态框

打算用React写对话框已经很长一段时间,现在是时候兑现承诺了。实际上,写起来相当简单。 核心在于使用React的接口React.createPortal(element, domContain...