-
Notifications
You must be signed in to change notification settings - Fork 8
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
8 changed files
with
343 additions
and
16 deletions.
There are no files selected for viewing
Some generated files are not rendered by default. Learn more about how customized files appear on GitHub.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Some generated files are not rendered by default. Learn more about how customized files appear on GitHub.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,9 @@ | ||
| --- | ||
| title: 2024山东省网络安全技能大赛九州信泰杯wp | ||
| tags: [] | ||
| categories: [] | ||
| cover: 'https://t.mwm.moe/fj?20241027222243818' | ||
| abbrlink: 36d0dbb | ||
| date: 2024-10-27 22:22:43 | ||
| --- | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,206 @@ | ||
| --- | ||
| title: Python实验——曲阜师范大学新闻内容爬取 | ||
| tags: | ||
| - Python | ||
| categories: | ||
| - Python | ||
| cover: >- | ||
| https://th.bing.com/th/id/OIP.dJToM1TiZiJA0GYwzDHwjQHaHY?w=179&h=180&c=7&r=0&o=5&pid=1.7 | ||
| abbrlink: 6d67d75 | ||
| date: 2024-11-06 08:59:32 | ||
| --- | ||
|
|
||
| ## 心得体会(随便说几句) | ||
|
|
||
| 核心就是利用 requests 和 BeautifulSoup 库,通过定位标签来获取新闻内容。 | ||
|
|
||
| 其实关键点就在于定位标签,通过观察网页源码,可以发现新闻内容和标题等都是在一个个的 `div` 标签中,因此我们可以通过 `find` 方法来定位这些标签,然后通过 `find_all` 方法来获取所有符合条件的标签。 | ||
|
|
||
| 灵活运用 `print` 语句,方便调试,慢慢就写出来了。 | ||
|
|
||
| 还有个问题就是,获取到的链接是形如 `../` 的相对链接,需要进行转换再进行拼接,可以用切片或者 `replace` 方法来实现。 | ||
|
|
||
| 还遇到一个问题就是,浏览器 F12 看到的标签和网页源码中的标签有时候会不一致,这里需要 `print` 调试才能找到正确的标签。 | ||
|
|
||
| ## 源码 | ||
|
|
||
| ```py | ||
| import requests | ||
| from bs4 import BeautifulSoup | ||
|
|
||
|
|
||
| def scrape_news(url): | ||
|
|
||
| response = requests.get(url) | ||
| response.encoding = "utf-8" | ||
|
|
||
| soup = BeautifulSoup(response.text, "html.parser") | ||
| # 定位body | ||
| body = soup.body | ||
| if body is not None: | ||
| # 定位div | ||
| div = body.find("div", class_="wrap") | ||
| if div is not None: | ||
| # 定位div | ||
| div_container = div.find("div", class_="container clearfix") | ||
| if div_container is not None: | ||
| # 定位li | ||
| div_pull_right = div_container.find( | ||
| "div", class_="pull-right list-right" | ||
| ) | ||
| if div_pull_right is not None: | ||
| # 定位lb-ul | ||
| lb_ul = div_pull_right.find("ul", class_="lb-ul") | ||
| if lb_ul is not None: | ||
| # 定位li | ||
| li = lb_ul.find_all("li") | ||
| result = "" | ||
| for item in li: | ||
| title = item.find("div", class_="lb-ul-tt txt-elise").text | ||
| date = item.find("div", class_="lb-ul-date").text | ||
| content = item.find("div", class_="lb-ul-p").text | ||
| link = item.find("a", class_="clearfix img-hide").get( | ||
| "href" | ||
| ) | ||
| link = ( | ||
| f"https://www.qfnu.edu.cn{link[2:].replace("../", "")}" | ||
| ) | ||
| result += f"标题: {title}\n日期: {date}\n内容: {content}\n链接: {link}\n\n" | ||
| return result | ||
| else: | ||
| print(f"未找到 class 为 'lb-ul' 的 ul,获取到的值是:{lb_ul}") | ||
| return | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'pull-right list-right' 的 div,获取到的值是:{div_pull_right}" | ||
| ) | ||
| return | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'container clearfix' 的 div,获取到的值是:{div_container}" | ||
| ) | ||
| return | ||
| else: | ||
| print(f"未找到 class 为 'wrap' 的 div,获取到的值是:{div}") | ||
| return | ||
| else: | ||
| print(f"未找到 body,获取到的值是:{body}") | ||
| return | ||
|
|
||
|
|
||
| # 获取新闻页数 | ||
| def get_news_page_count(url): | ||
|
|
||
| response = requests.get(url) | ||
| response.encoding = "utf-8" | ||
|
|
||
| soup = BeautifulSoup(response.text, "html.parser") | ||
| # 定位body | ||
| body = soup.body | ||
| if body is not None: | ||
| # 定位div | ||
| div = body.find("div", class_="wrap") | ||
| if div is not None: | ||
| # 定位div | ||
| div_container = div.find("div", class_="container clearfix") | ||
| if div_container is not None: | ||
| # 定位div | ||
| div_pull_right = div_container.find( | ||
| "div", class_="pull-right list-right" | ||
| ) | ||
| # print(div_pull_right) | ||
| if div_pull_right is not None: | ||
| # 定位div | ||
| div_page_box = div_pull_right.find( | ||
| "div", class_="page-box text-center wow fadeInUp" | ||
| ) | ||
| if div_page_box is not None: | ||
| div_pb_sys_common = div_page_box.find( | ||
| "div", class_="pb_sys_common" | ||
| ) | ||
| if div_pb_sys_common is not None: | ||
| span_p_pages = div_pb_sys_common.find( | ||
| "span", class_="p_pages" | ||
| ) | ||
| if span_p_pages is not None: | ||
| span_p_no = span_p_pages.find("span", class_="p_no") | ||
| if span_p_no is not None: | ||
| a = span_p_no.find("a") | ||
| if a is not None: | ||
| return int( | ||
| a.get("href") | ||
| .replace(".htm", "") | ||
| .replace("xxyw/", "") | ||
| ) | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'pb_sys_common' 的 div,获取到的值是:{div_pb_sys_common}" | ||
| ) | ||
| return 0 | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'page-box text-center wow fadeInUp animated' 的 div,获取到的值是:{div_page_box}" | ||
| ) | ||
| return 0 | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'pull-right list-right' 的 div,获取到的值是:{div_pull_right}" | ||
| ) | ||
| return 0 | ||
| else: | ||
| print( | ||
| f"未找到 class 为 'container clearfix' 的 div,获取到的值是:{div_container}" | ||
| ) | ||
| return 0 | ||
| else: | ||
| print(f"未找到 class 为 'wrap' 的 div,获取到的值是:{div}") | ||
| return 0 | ||
| else: | ||
| print(f"未找到 body,获取到的值是:{body}") | ||
| return 0 | ||
|
|
||
|
|
||
| # 保存为txt | ||
| def save_to_txt(data, filename): | ||
| with open(filename, "w", encoding="utf-8") as f: | ||
| f.write(data) | ||
|
|
||
|
|
||
| print("即将开始爬取新闻首页") | ||
|
|
||
| news_index = scrape_news("https://www.qfnu.edu.cn/news/xxyw.htm") | ||
| save_to_txt(news_index, "news_index.txt") | ||
|
|
||
| print("新闻首页爬取完成") | ||
|
|
||
| print("即将开始爬取新闻第二页及以后") | ||
|
|
||
| page_count = get_news_page_count("https://www.qfnu.edu.cn/news/xxyw.htm") | ||
|
|
||
| if page_count: | ||
| print(f"获取到的新闻页数为:{page_count}") | ||
| else: | ||
| print("未获取到新闻页数") | ||
| exit() | ||
|
|
||
| if page_count > 0: | ||
| for i in range(page_count, 0, -1): | ||
| print(f"即将爬取第 {i} 页") | ||
| news = scrape_news(f"https://www.qfnu.edu.cn/news/xxyw/{i}.htm") | ||
| save_to_txt(news, f"news_{i}.txt") | ||
|
|
||
| ``` | ||
|
|
||
| ## 实现截图 | ||
|
|
||
| 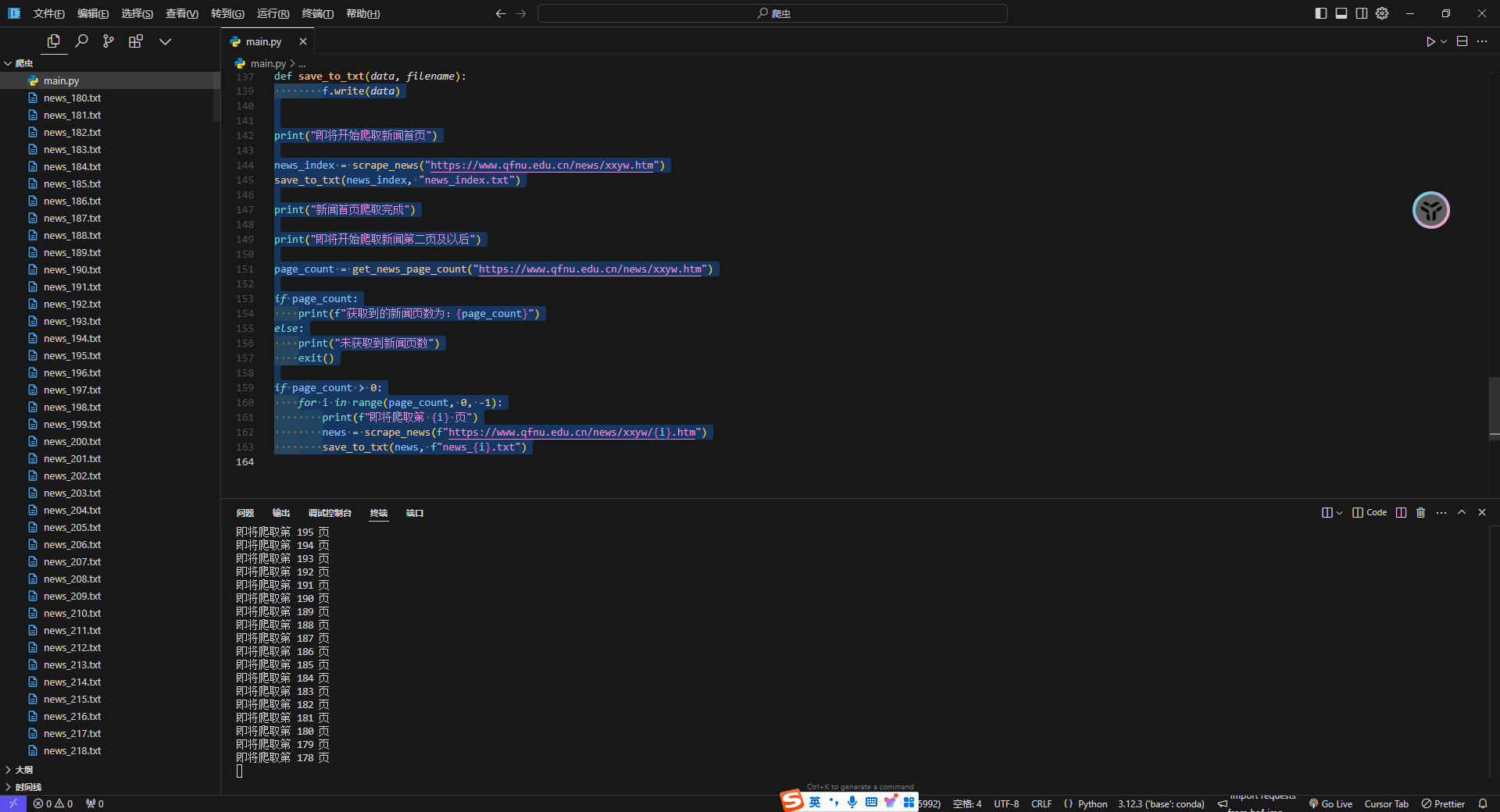 | ||
|
|
||
| 可以看到七百多页全爬完了,大约用了几分钟 | ||
|
|
||
| 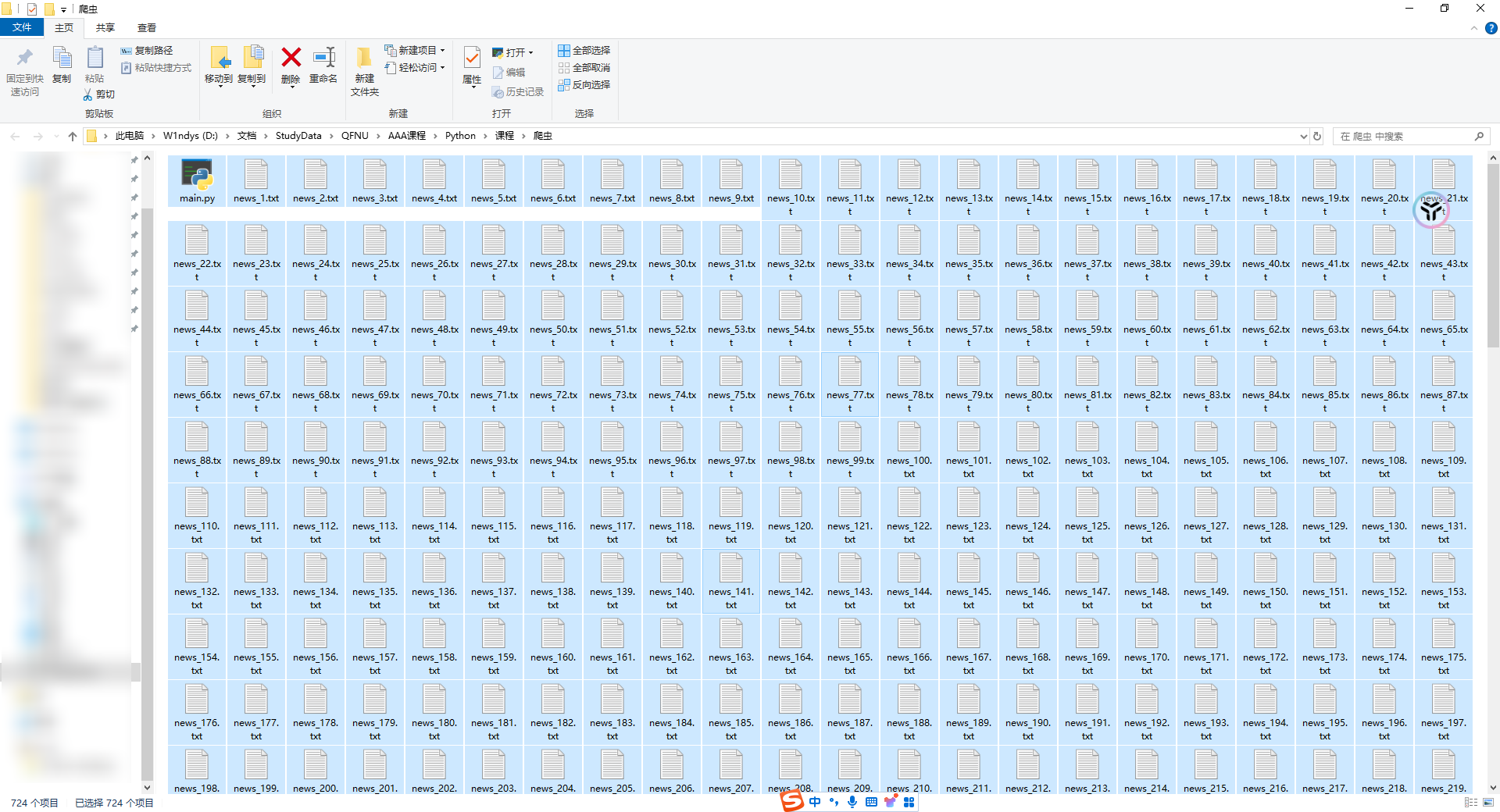 | ||
|
|
||
| 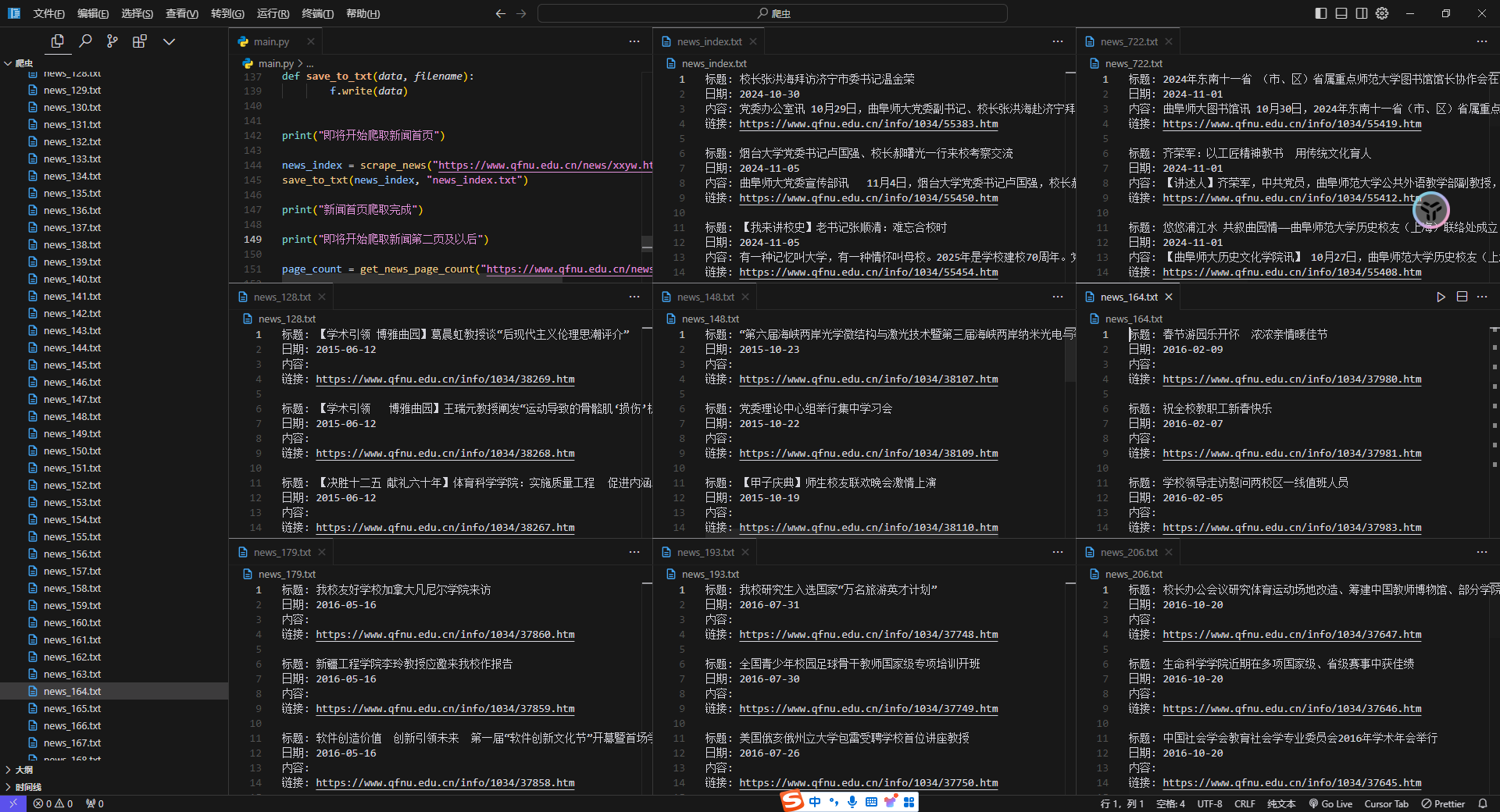 | ||
|
|
||
| 随便点开几个看看 | ||
|
|
||
| 我是以一页为一个单位爬的,如果要用的话,直接 Python 脚本合并起来即可 |
Oops, something went wrong.