This repository contains the reference code for the paper Duel-Level Collaborative Transformer for Image Captioning.
please refer to m2 transformer
- Annotation. Download the annotation file annotation.zip. Extarct and put it in the project root directory.
- Feature. You can download our ResNeXt-101 feature (hdf5 file) here. Access code: 7fhb.
- evaluation. Download the evaluation tools here. Access code: 7fhb. Extarct and put it in the project root directory.
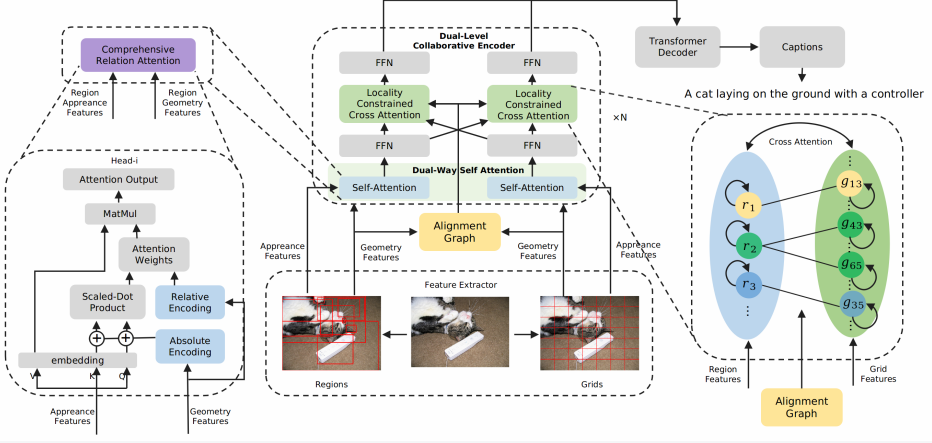
There are five kinds of keys in our .hdf5 file. They are
['%d_features' % image_id]: region features (N_regions, feature_dim)['%d_boxes' % image_id]: bounding box of region features (N_regions, 4)['%d_size' % image_id]: size of original image (for normalizing bounding box), (2,)['%d_grids' % image_id]: grid features (N_grids, feature_dim)['%d_mask' % image_id]: geometric alignment graph, (N_regions, N_grids)
We extract feature with the code in grid-feats-vqa.
The first three keys can be obtained when extracting region features with extract_region_feature.py. The forth key can be obtained when extracting grid features with code in grid-feats-vqa. The last key can be obtained with align.ipynb
python train.py --exp_name dlct --batch_size 50 --head 8 --features_path ./data/coco_all_align.hdf5 --annotation annotation --workers 4 --rl_batch_size 100 --image_field ImageAllFieldWithMask --model DLCT --rl_at 17 --seed 118python eval.py --annotation annotation --workers 4 --features_path ./data/coco_all_align.hdf5 --model_path path_of_model_to_eval --model DLCT --image_field ImageAllFieldWithMask --grid_embed --box_embed --dump_json gen_res.json --beam_size 5Important args:
--features_pathpath to hdf5 file--model_path--dump_jsondump generated captions to
[1] M2
[2] grid-feats-vqa
[3] butd
Thanks the original m2 and amazing work of grid-feats-vqa.