{kind=link}
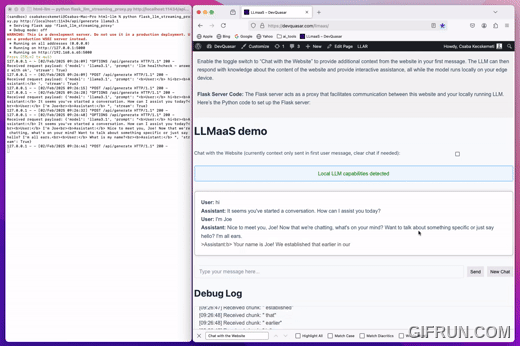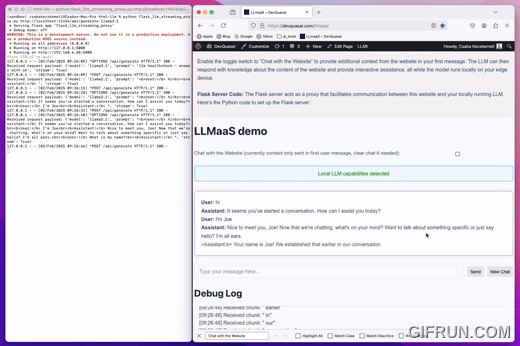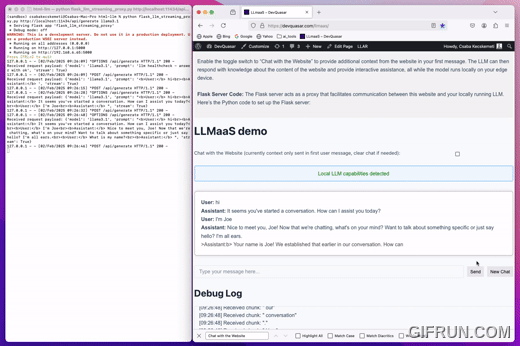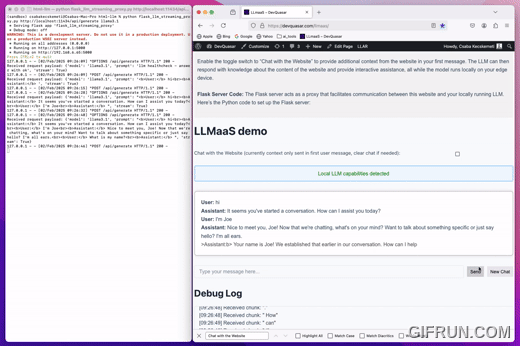
Local LLM as a Service
+----------------------------+
| Web Browser |
| - Renders HTML |
| - Handles message history |
| - Displays chat messages |
+------------+---------------+
|
v
+----------------------------+
| LLmaaS Proxy Server |
| - Enables browser access |
| to local LLM resource |
+------------+---------------+
|
v
+----------------------------+
| Local LLM Service |
| (e.g., Ollama, Llama.cpp) |
| - Processes requests |
| - Generates responses |
+----------------------------+
The proxy takes 2 optional parameters 1 - local Ollama generate URL 2 - model name (The default values are the same as seen in the example call)
python llmaas_proxy.py http://localhost:11434/api/generate llama3.1
Note current LLmaaS proxy only implemented and tested with Ollama local LLM service!
- Install Ollama local LLM service
- Start serving a local model with Ollama (demo has used Llama 3.1)
- Download and start LLmaaS proxy as seen above
- Load demo page or use the provided html file locally
Join me an develop the LLmaaS proxy to make this a generic purpose tool to leverage local LLMs on web. Introduce security to avoid resource exploitation. Move to FastAPI? I'm looking for help to make the proxy more generic support multiple local LLM services without any change on the HTML side. Also looking for ideas how to make the HTML par more modular and easy to use.
![]()
'Make knowledge free for everyone'