Byte Array Benchmarks
The benchmarks were done to improve performance of getting values for keys via Java API of RocksDB database.
Benchmarks were run on Windows 10 Home with Intel(R) Core(™) i7-6700K CPU with 4 cores and clock speed of 4GHz. The JVM version was as follows:
openjdk version "11.0.8" 2020-07-14
OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1)
OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1, mixed mode)
JMH Java harness was used to run the benchmarks. The benchmarks were running in SampleTime mode with a time unit set to nanosecond. There were 100 warm up iterations and 500 measurement iterations. The process of running all the benchmarks with above settings was repeated separately 10 times, which produced 10 CSV result files. The files were processed and the results were visualized using Python script with Pandas and Matplotlib libraries.
There were two benchmark classes implemented: ByteArrayFromNativeBenchmark - to compare different options for writing byte arrays on native side and returning it to Java and ByteArrayToNativeBenchmark - to compare different options for passing byte array. There is a common part of code for all the benchmarks, which mocks getting data for the returned byte array:
std::string value = GetByteArrayInternal(key);
The function GetByteArrayInternal() copies the first 38 bytes of the input byte array and finds the return byte array in an std::unordered_map structure. Depending on the key, one of 6 different values can be returned with sizes as follows: 10, 50, 512, 1024, 4096 or 16384 bytes.
This part presents performance of writing byte array data in native methods and returning it. There were 9 approaches compared, in each of them key is passed as Java byte array (byte[]) and read using JNI function GetByteArrayRegion unless otherwise stated:
- basicGetByteArray - Java byte array for value is allocated and written using JNI functions: NewByteArray and SetByteArrayRegion
- preallocatedGetByteArray - byte array for value is allocated in Java and then passed to native method for writing using SetByteArrayRegion JNI function
- bufferGetByteArray - ByteBuffer is instantiated in native method, its array() method is called to get its underlying byte array, finally GetPrimitiveArrayCritical and memcpy is used to write
- directBufferGetByteArray - direct ByteBuffer is instantiated with value using JNI function NewDirectByteBuffer and returned
- directKeyAndValueBuffersPreallocatedGetByteArray - there is a direct ByteBuffer allocated for key and a direct ByteBuffer allocated for value on Java side; in native method GetDirectBufferAddress JNI function is used to get native pointer to array and memcpy is used to write to it
- directValueBufferOnlyPreallocatedGetByteArray - there is a direct ByteBuffer allocated for value on Java side; in native method GetDirectBufferAddress JNI function is used to get native pointer to array and memcpy is used to write to it
- bufferValueOnlyPreallocatedGetByteArray - there is a ByteBuffer allocated for value on Java side; in native method ByteArray.array() is called to get underlying byte array and then GetPrimitiveArrayCritical and memcpy are called to write to it
- preallocatedGetByteArrayWithGetPrimitiveArrayCritical - similar to preallocatedGetByteArray, but GetPrimitiveArrayCritical and memcpy are used for writing
- unsafeAllocatedGetByteArray - byte array is allocated using sun.misc.Unsafe class in Java, then the memory address is passed to native method as long primitive data type
This part presents the performance of passing byte array data to native method for reading. There were 6 approaches compared, in each of them value is written to Java byte array, which is allocated in native method via JNI:
- passKeyAsByteArray - Java byte array is passed to native method
- passKeyAsByteArrayCritical - Java byte array is passed to native method and read using GetPrimitiveArrayCritical JNI function
- passKeyAsDirectByteBuffer - direct ByteBuffer is passed to native method for reading
- passKeyAsDirectByteBufferWithAllocate - direct ByteBuffer is allocated in Java and passed to native method for reading
- passKeyAsUnsafe - byte buffer is passed as address to off-heap memory allocated with sun.misc.Unsafe outside of the benchmark
- passKeyAsUnsafeWithAllocate - byte buffer is allocated using sun.misc.Unsafe and passed as address to memory
Results for all approaches per byte array size were plotted with error as vertical segment.

For getting 10 bytes arrays, preallocatedGetByteArrayWithGetPrimitiveArrayCritical proved to be the fastest method, just slightly better than unsafeAllocatedGetByteArray and preallocatedGetByteArray.

For getting 50 bytes arrays, preallocatedGetByteArrayWithGetPrimitiveArrayCritical, unsafeAllocatedGetByteArray and preallocatedGetByteArray.seems to be equally fast.

For getting 512 bytes arrays, unsafeAllocatedGetByteArray proved to be the best method with directBufferGetByteArray being second.

See “Byte array with 512 bytes” above.
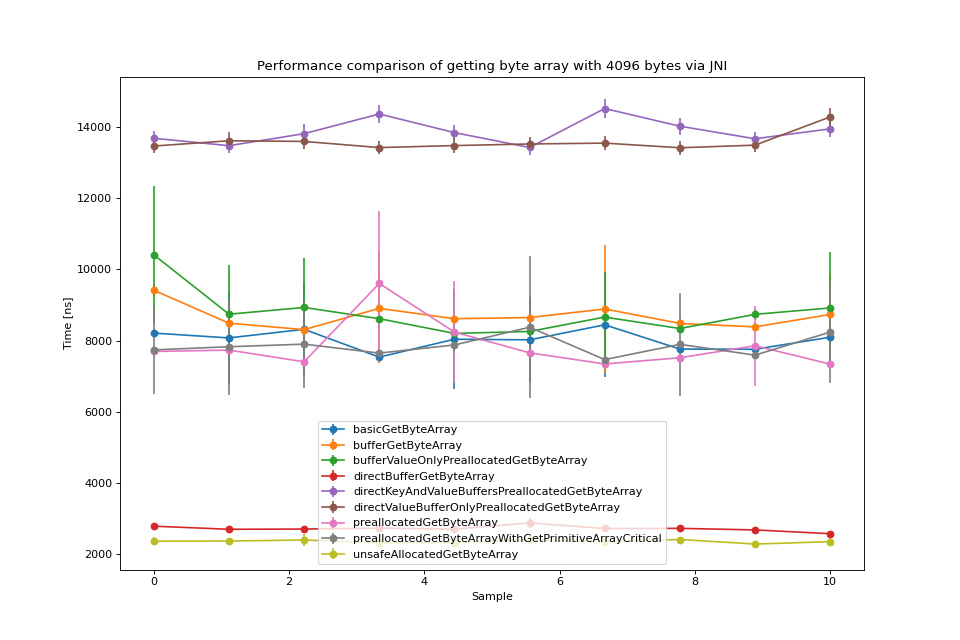
See “Byte array with 512 bytes” above.

For getting 16384 bytes arrays, unsafeAllocatedGetByteArray and directBufferGetByteArray are significantly better than the rest methods. Also, the difference between their performances seems to be less significant. Approach from unsafeAllocatedGetByteArray is slightly better.

For getting 38 bytes arrays, passKeyAsUnsafe, passKeyAsUnsafeWithAllocate, passKeyAsByteArrayCritical and passKeyAsDirectByteBuffer has all similarly good performance. passKeyAsByteArray is slightly worse and passKeyAsDirectByteBufferWithAllocate is significantly worse than the other methods.

For getting 128 bytes arrays, passKeyAsUnsafe seems to be slightly better than the other methods.

See “Byte array with 128 bytes” above.
The charts show results' errors as vertical segments. It is noticed that outliers usually have bigger errors, which leads to the conclusion that these samples should be discarded. The methods with more outliers or rather with samples that are more scattered along y axis (time) should be treated as less stable and possibly more affected by JVM or system state.
In the case of getting native byte array through native Java method the fastest approach depends on array size. For small arrays, allocating a byte array in Java and using GetPrimitiveArrayCritical JNI function and memcpy to write to the array seems the best option. The same method, but using SetByteArrayRegion seems to be almost as good together with using sun.misc.Unsafe to allocate the memory and memcpy to write to it. For bigger arrays, using sun.misc.Unsafe and memcpy becomes the better choice. For arrays with 16 kilobytes both sun.misc.Unsafe and direct ByteArray are almost equally good.
Benchmarks for reading byte arrays from different sources could be performed to better measure and compare sun.misc.Unsafe fitness for getting byte arrays.
In the case of passing native byte array to native Java method the fastest approach also depends on array size, but to a lesser degree. The results are also more unstable across benchmarking runs. For smaller arrays the results seem to favor getting data from a Java byte array using GetPrimitiveArrayCritical. For larger arrays (over 512) passing a byte array in memory allocated by sun.misc.Unsafe seems better. At the same time if overhead of copying data from a Java byte array to off-heap memory is taken into account, then sun.misc.Unsafe is a worse option.