git clone https://github.com/hrishikeshshekhar/curiosity-learning/
pip install -r requirements.txt
pip install torch===1.7.0 torchvision===0.8.1 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
- Fork this repository throught Github.
- Make changes to the required modules
- Lint the code using pylint
- Create a pull request with specified changes
- Make the requested changes to the code
- Merge the PR :)
Generalization remains as one of the most fundamental challenges in deep reinforcement learning. Recent evidence points to the fact that reinforcement learning agents are able to overfit large training datasets. They allow reinforcement learning agents to memorize an optimal policy for the given environment as they always encounter near identical states. However, these methods do not ensure that the agent learns generalizable policies. For example, an agent trained on Mario Level 1 might be able to complete level 1 in super human times. However, it might miserably fail on level 2 since it hasn't been trained on level 2 at all. This shows that the policy learnt by the agent is simply through memorization of the optimal action given a state without any generalizable learning. Hence, the main motivation of this project is to be able to build more generalizable reinforcement learning agents.
Curiosity driven self exploration is an approach adopted for to solve the issue of sparse rewards in an environment. This is achieved by formulating the agent's curiosity as the error in an agent’s ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. This approach has shown great promise in learning generalizable policies. Hence, the objective of this project is to evaluate curiosity driven self supervised learning on procedurally generated environments. This can be split into the following experiments which will utilize the 16 proc-gen environments :
- Evaluating performance of state of the art algorithms like : A3C, PPO without the curiosity reward
- Evaluating an agent with only the curiosity reward without using extrinsic rewards
- Building state of the art algorithms which use both extrinsic rewards and curiosity reward.
In many real-world scenarios, rewards extrinsic to the agent are extremely sparse, or absent altogether. In such cases, curiosity can serve as an intrinsic reward signal to enable the agent to explore its environment and learn skills that might be useful later in its life. This curiosity is formulated as the error in an agent's ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. They combine extrinsic and intrinsic rewards and together call their model as an Intrinsic Curiosity Module.
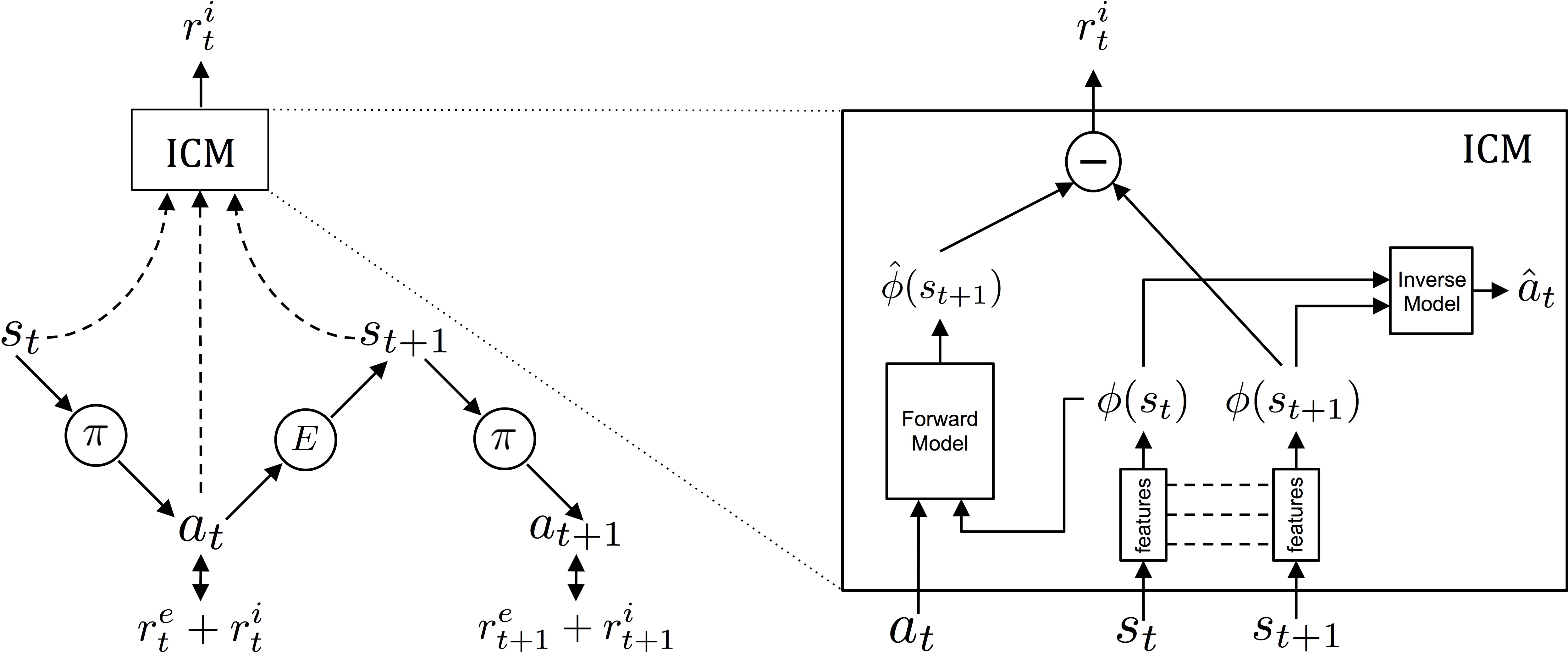
In the paper, three broad settings are investigated: 1) sparse extrinsic reward, where curiosity allows for far fewer interactions with the environment to reach the goal; 2) exploration with no extrinsic reward, where curiosity pushes the agent to explore more efficiently; and 3) generalization to unseen scenarios (e.g. new levels of the same game) where the knowledge gained from earlier experience helps the agent explore new places much faster than starting from scratch. The results shown are very encouraging towards learning generalizable policies rather than memorized policies.
Procgen Benchmark is a suite of 16 procedurally generated game-like environments designed to benchmark both sample efficiency and generalization in reinforcement learning. The use of procedural generation ensures that the states that reinforcement learning agents see is almost always different. This forces the reinforcement learning agent to learn generalizable policies.

Some of the key features of the proc-gen benchmark include :
- High Diversity
- Fast Evaluation
- Tunable Difficulty
- Level Solvability
- Emphasis on Visual Recognition and Motor Control
- Shared Action and Observation Space
- Tunable Dependence on Exploration
- Tunable Dependence on Memory
You can read the paper here and read more about it on Open AI's blog post