-
Notifications
You must be signed in to change notification settings - Fork 550
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
78ab865
commit ecedc32
Showing
8 changed files
with
197 additions
and
173 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -91,19 +91,24 @@ Step-by-step: | |
|
|
||
| ```shell | ||
| $ cd ${HOME}/project/tensorrt_demos | ||
| $ python3 trt_googlenet.py --usb --vid 0 --width 1280 --height 720 | ||
| $ python3 trt_googlenet.py --usb 0 --width 1280 --height 720 | ||
| ``` | ||
|
|
||
| Here's a screenshot of the demo (JetPack-4.2.2, i.e. TensorRT 5). | ||
|
|
||
| 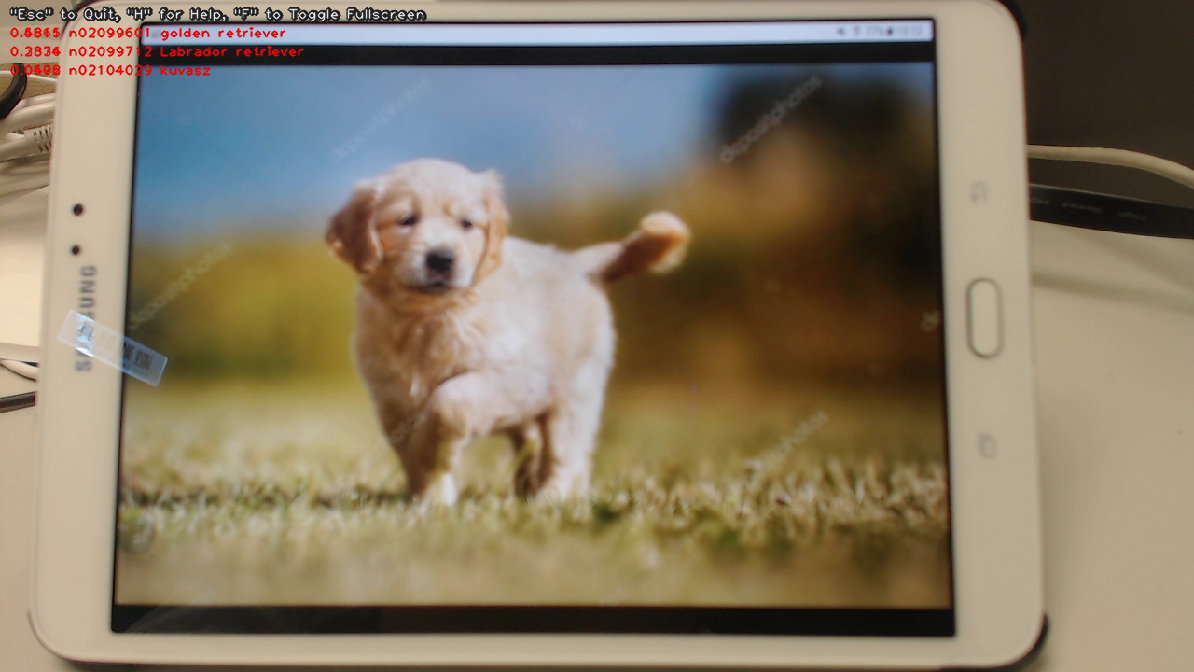 | ||
|
|
||
| 5. The demo program supports a number of different image inputs. You could do `python3 trt_googlenet.py --help` to read the help messages. Or more specifically, the following inputs could be specified: | ||
| 5. The demo program supports 5 different image/video inputs. You could do `python3 trt_googlenet.py --help` to read the help messages. Or more specifically, the following inputs could be specified: | ||
|
|
||
| * `--file --filename test_video.mp4`: a video file, e.g. mp4 or ts. | ||
| * `--image --filename test_image.jpg`: an image file, e.g. jpg or png. | ||
| * `--usb --vid 0`: USB webcam (/dev/video0). | ||
| * `--rtsp --uri rtsp://admin:[email protected]/live.sdp`: RTSP source, e.g. an IP cam. | ||
| * `--image test_image.jpg`: an image file, e.g. jpg or png. | ||
| * `--video test_video.mp4`: a video file, e.g. mp4 or ts. An optional `--video_looping` flag could be enabled if needed. | ||
| * `--usb 0`: USB webcam (/dev/video0). | ||
| * `--rtsp rtsp://admin:[email protected]/live.sdp`: RTSP source, e.g. an IP cam. An optional `--rtsp_latency` argument could be used to adjust the latency setting in this case. | ||
| * `--onboard 0`: Jetson onboard camera. | ||
|
|
||
| In additional, you could use `--width` and `--height` to specify the desired input image size, and use `--do_resize` to force resizing of image/video file source. | ||
|
|
||
| The `--usb`, `--rtsp` and `--onboard` video sources usually produce image frames at 30 FPS. If the TensorRT engine inference code runs faster than that (which happens easily on a x86_64 PC with a good GPU), one particular image could be inferenced multiple times before the next image frame becomes available. This causes problem in the object detector demos, since the original image could have been altered (bounding boxes drawn) and the altered image is taken for inference again. To cope with this problem, use the optional `--copy_frame` flag to force copying/cloning image frames internally. | ||
|
|
||
| 6. Check out my blog post for implementation details: | ||
|
|
||
|
|
@@ -131,7 +136,7 @@ Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", fo | |
|
|
||
| ```shell | ||
| $ cd ${HOME}/project/tensorrt_demos | ||
| $ python3 trt_mtcnn.py --image --filename ${HOME}/Pictures/avengers.jpg | ||
| $ python3 trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg | ||
| ``` | ||
|
|
||
| Here's the result (JetPack-4.2.2, i.e. TensorRT 5). | ||
|
|
@@ -169,9 +174,8 @@ Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", fo | |
|
|
||
| ```shell | ||
| $ cd ${HOME}/project/tensorrt_demos | ||
| $ python3 trt_ssd.py --model ssd_mobilenet_v1_coco \ | ||
| --image \ | ||
| --filename ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg | ||
| $ python3 trt_ssd.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \ | ||
| --model ssd_mobilenet_v1_coco | ||
| ``` | ||
|
|
||
| Here's the result (JetPack-4.2.2, i.e. TensorRT 5). Frame rate was good (over 20 FPS). | ||
|
|
@@ -187,9 +191,8 @@ Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", fo | |
| I also tested the "ssd_mobilenet_v1_egohands" (hand detector) model with a video clip from YouTube, and got the following result. Again, frame rate was pretty good. But the detection didn't seem very accurate though :-( | ||
|
|
||
| ```shell | ||
| $ python3 trt_ssd.py --model ssd_mobilenet_v1_egohands \ | ||
| --file \ | ||
| --filename ${HOME}/Videos/Nonverbal_Communication.mp4 | ||
| $ python3 trt_ssd.py --video ${HOME}/Videos/Nonverbal_Communication.mp4 \ | ||
| --model ssd_mobilenet_v1_egohands | ||
| ``` | ||
|
|
||
| (Click on the image below to see the whole video clip...) | ||
|
|
@@ -202,9 +205,8 @@ Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", fo | |
|
|
||
| ```shell | ||
| $ cd ${HOME}/project/tensorrt_demos | ||
| $ python3 trt_ssd_async.py --model ssd_mobilenet_v1_coco \ | ||
| --image \ | ||
| --filename ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg | ||
| $ python3 trt_ssd_async.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \ | ||
| --model ssd_mobilenet_v1_coco | ||
| ``` | ||
|
|
||
| 5. To verify accuracy (mAP) of the optimized TensorRT engines and make sure they do not degrade too much (due to reduced floating-point precision of "FP16") from the original TensorFlow frozen inference graphs, you could prepare validation data and run "eval_ssd.py". Refer to [README_mAP.md](README_mAP.md) for details. | ||
|
|
@@ -278,8 +280,8 @@ Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", fo | |
|
|
||
| ```shell | ||
| $ wget https://raw.githubusercontent.com/pjreddie/darknet/master/data/dog.jpg -O ${HOME}/Pictures/dog.jpg | ||
| $ python3 trt_yolo.py -m yolov4-416 \ | ||
| --image --filename ${HOME}/Pictures/dog.jpg | ||
| $ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \ | ||
| -m yolov4-416 | ||
| ``` | ||
|
|
||
| This is a screenshot of the demo against JetPack-4.4, i.e. TensorRT 7. | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.