Prédire le taux de fréquentation de la tour Eiffel avec le réseau social Instagram
Les lieux touristiques de Paris sont souvent bondés et il serait utile de modéliser cette fréquentation afin de savoir à quels moments de la journée, de la semaine, voire de l'année, il est le plus conseillé de s'y rendre. De plus, un tel modèle permettrait de connaître les différents facteurs de fréquentation, leurs dépendances et leurs évolutions. Ici, on s'intéresse dans un premier temps à la tour Eiffel comme un cas d'étude.
L'objectif de ce modèle est de prédire le taux de fréquentation de la tour Eiffel sur une échelle discrète (par exemple de 1 à 5), en se basant sur le nombre de photos prises à cet endroit et postées sur Instagram. On suppose que la proportion de touristes postant des photos sur Instagram est toujours la même et évolue de la même manière que le nombre total de touristes présents à la tour Eiffel.
Le premier jeu de données est obtenu via le réseau social de photos Instagram. Beaucoup de photos sont associées à un lieu par l'utilisateur. On décide de récupérer toutes les photos prises à la tour Eiffel entre le 1er et le 30 juin. Les données sont obtenues via le script fetch_instagram.py et sont disponibles dans le fichier db_june.
On récupère pour chaque photo :
- l'ID
- la date et l'heure où elle a été postée
- le lien de l'image
Au final, seules la date et l'heure seront utilisées dans ce cas d'étude. Etant donné le fonctionnement d'Instagram, on suppose que toutes les photos sont postées immédiatement après avoir été prises.
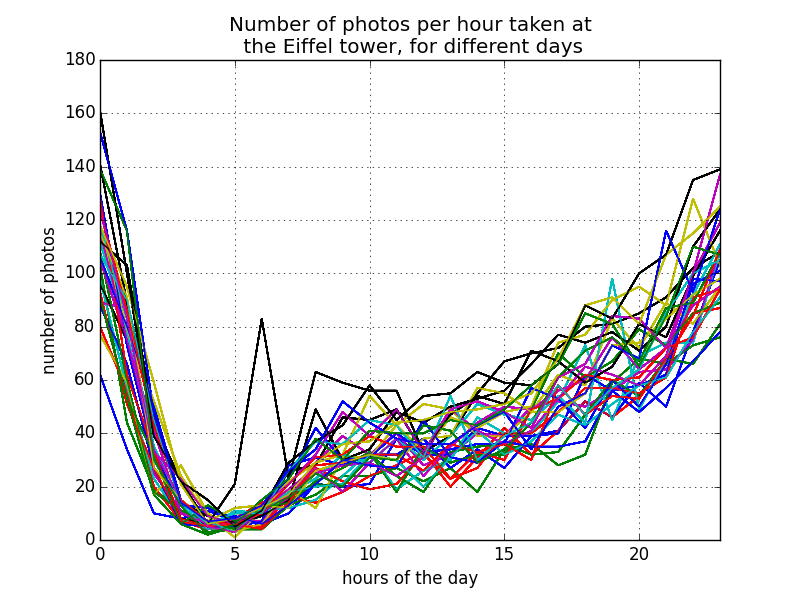
Les données sont pré-traitées afin de grouper les photos et d'établir les fréquences horaires pour chaque jour du mois (fichier preprocess.py). On trace sur un graphique ces fréquences de manière à obtenir un premier aperçu de nos données (figure ci-dessous, où chaque courbe représente un jour du mois). On remarque que l'évolution des fréquences au cours des différents jours est très similaire. Le facteur horaire est, comme on pouvait s'y attendre, très important dans l'évolution des fréquences.
On utilise aussi des données météorologiques depuis l'API http://forecast.io. Dans un souci de simplicité, on se limite à la description du temps (nuages, pluie, soleil etc.) pour chaque heure de chaque jour. Ces données sont obtenues via le script fetch_weather.py et sont disponibles dans le fichier db_weather.
Le problème est vu comme une tâche de classification. On ne consière pas le numéro des jours dans le mois, mais juste le jour de la semaine auquel il correspond. Les heures d'une journée sont considérées individuellement durant la classification, c'est-à-dire qu'on ne s'intéresse pas aux heures précédentes et suivantes.
On décide de réaliser un modèle simple en prenant en compte trois paramètres :
- le jour de la semaine (par exemple "Lundi")
- l'heure du jour (par exemple "22h")
- la description météorologique (par exemple "ensoleillé")
Le modèle est entrainé et testé sur les données du mois de juin. Pour la prédiction, on utilise la méthode machine à vecteurs de support implémentée dans la librairie sk-learn. Quant aux tests, ils sont réalisés par k-fold cross-validation. Le code est disponible dans le script train.py.
On teste la précision pour différentes échelles de fréquentations à 3, 4 et 5 graduations. Les résultats sont disponibles dans le tableau-ci-dessous.
| Echelle | Précision |
|---|---|
| 1 à 3 | 84.7% |
| 1 à 4 | 79.6% |
| 1 à 5 | 74.9% |
Cette expérience montre qu'il est relativement simple d'établir un modèle avec une précision correcte pour répondre à la problématique soulevée dans l'introduction. Plusieurs pistes seraient à suivre dans le futur :
- améliorer le modèle existant en exploitant plus de paramètres (prendre en compte le mois, les périodes de vacances, tester le degré d'influence des différents paramètres etc.)
- étendre à d'autres lieux touristiques parisiens. Il est par exemple possible de filtrer les positions géographiques des photos avec des points d'intérêt touristiques enregistrés dans la base de données ouverte OpenStreetMap. Le principal écueil serait peut-être le manque de données (pas assez de photos prises) pour certains lieux dans Paris.
- utiliser les données d'autres réseaux sociaux, comme par exemple de Foursquare ou Twitter.
- requests
- pandas
- matplotlib
- numpy
- sklearn