personal project on KG learning for drug discovery (work in progress)
See the notebook in dev for more info.
- Compute embeddings with ProtT5 (up to 4.5k residues due to colab limitations) - currently un-usued.
- Code for cleaning up / preproc of DrugBank (done)
- Sampler for drug/target neighborhoods (done)
- Write an efficient sampler/negative sampler for graph tuples (done)
- Train (done)
- Write a simple explanation of loss functions and training procedure (done).
- Validate
- qualitative first validation (done)
- Quantitative/inductive inference validation [TODO]
Several loss functions are to be implemented. At the moment, an edge-prediction (drug-target interaction) task has been successfully used for training. It is a transductive task - i.e., it returns embeddings only for drugs and proteins already seen in the graph, but it will be extended to an inductive one.
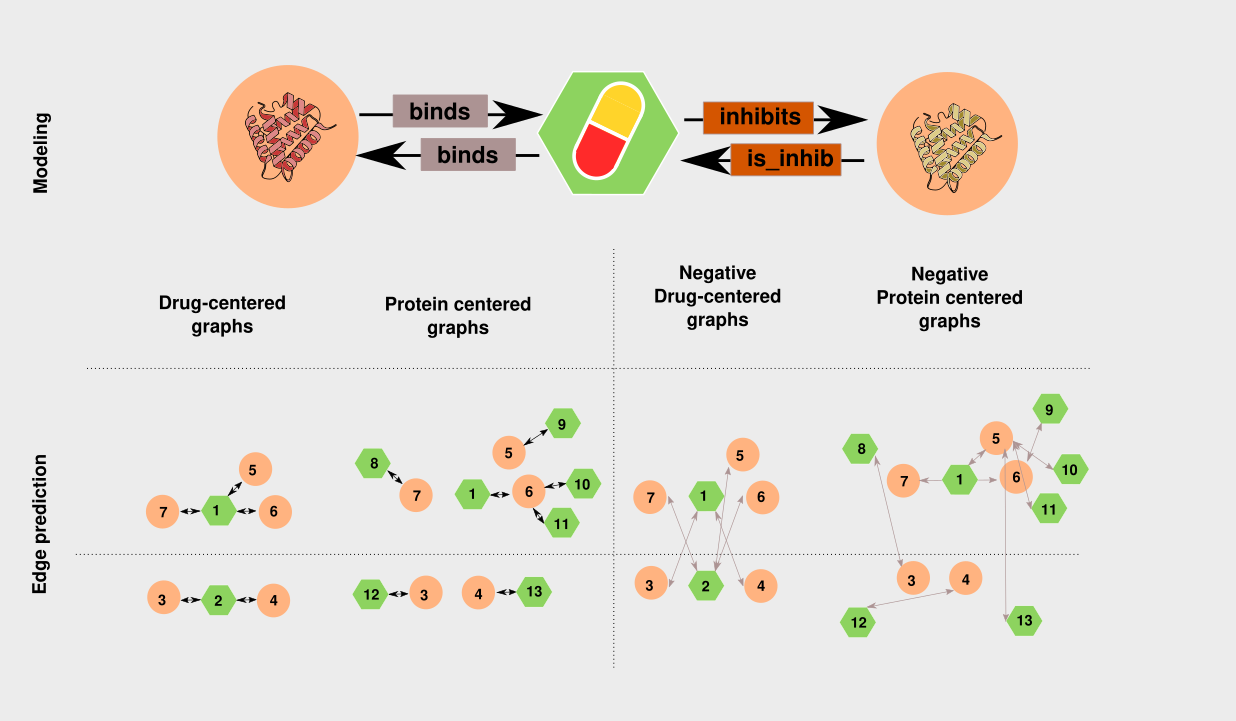
Outline of modeling and negative sampling approach:
for each epoch, the list of training drugs is permuted. All edges are contain attributes and represent drug-target interactions. For each unique drug, interaction type and target, a random embedding is initialized. Only the interactions that have at least a certain number of occurrences in the dataset are kept for statistical reasons (there is a risk of over-fitting to the unique subsets of relation-targets that contain the rare interactions).
All drugs and targets are put in a single graph tuple for performance. An efficient negative edge and sub-graph sampling strategy is also implemented. Namely:
- a random subset of drugs is selected (from a pre-computed drug-target edge list). The targets chosen are always a subset of the available ones, up to a certain number (2 to 3) in order to avoid an explosion on the number of edges.
- From that subset of drugs, the subset of targets that interact with them are selected, and the drugs that interact with those targets are also selected (using a pre-computed target-drug edge list).
The collected graphs up to that point constitute the "positive" graph. For negative sampling, in order to avoid re-loading other embeddings on the GPU, a derangement of the senders list is computed and the respective edges are added to the graph tuple that is to be returned.
The learning task, as a first step, is simply defined as predicting whether an edge exists or not (whether it is of the particular type).
In the following figure the derangement-based negative edge sampling strategy and the modeling strategy is depicted.
See bottom of included notebook.