By Quentin Churet, Alexis Tacnet, Domitille Prevost at CentraleSupélec.
This project is a search engine with a good looking terminal interface and some queries to test our search algorithm. This algorithm is based on the TW-IDF described in this paper, where we compute the link between words in a fixed window.
We also added two other term-weighting models :
- TF-IDF
- Okapi-BM25
After cloning the repository, it is highly recommended to install a virtual environment (such as virtualenv) or Anaconda to isolate the dependencies of this project with other system dependencies.
To install virtualenv, simply run:
$ pip install virtualenv
Once installed, a new virtual environment can be created by running:
$ virtualenv venv
This will create a virtual environment in the venv directory in the current working directory. To change the location and/or name of the environment directory, change venv to the desired path in the command above.
To enter the virtual environment, run:
$ source venv/bin/activate
You should see (venv) at the beginning of the terminal prompt, indicating the environment is active. Again, replace venv with your desired directory name.
To get out of the environment, simply run:
(venv) $ deactivate
While the virtual environment is active, install the required dependencies by running:
(venv) $ pip install -r requirements.txt
This will install all of the dependencies at specific versions to ensure they are compatible with one another.
We use NLTK as our package for word libraries, and you may need to install some datasets:
(venv) $ python -m nltk.downloader stopwords wordnet
This search engine was built to work on the CS276 data by Stanford Education. The dataset can be found here and needs to be installed in the ./data/cs276 folder.
You can install the data by running
python download_data.py
You will have the following structure:
project
└───data
│ └───cs276
| └───0
| | | 3dradiology.stanford.edu_
| | | ...
| └───1
| ...
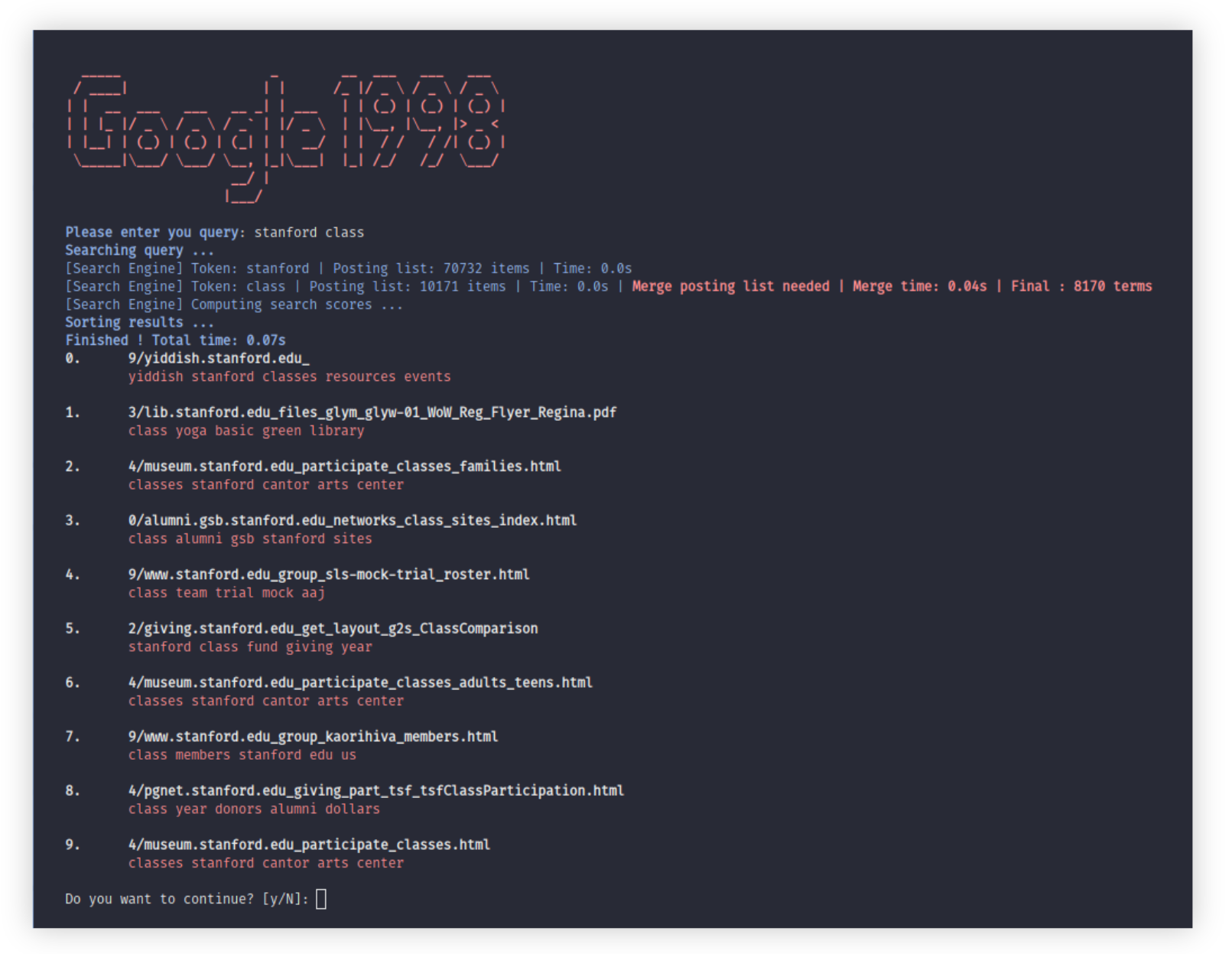
We provide a good looking interface for your queries, just by running:
(venv) $ python interface.py
The first time you launch our search engine, we will compute the indexes. This may takes some time.
You can also specify the count of results that it will display, like this:
(venv) $ python interface.py --count 20
By default the term-weighting model is TW-IDF, but you can also try the two other weighting models (TF-IDF and Okapi-BM25) by adding an argument :
(venv) $ python interface.py --count 20 --w tf-idf
(venv) $ python interface.py --count 20 --w okapi-bm25
In order to test our search algorithm, we have in the dev_* folders (in the dev_resources folder) sample queries and their expected output.
You can test them and compute the accuracy scores by simply running the following command :
(venv) $ python show_accuracy.py -w tw-idf
This will test the results using the TW-IDF weighting model. You can also try two other weighting model :
- Okapi-BM25 (by passing the
okapi-bm25as an argument) - TF-IDF (by passing the
tf-idfas an argument)
The documents are preprocessed in the indexing pipeline. In a first time removed the English stopwords, but we kept them in the final version for more accuracy, as the performance for indexing and query time is quite the same. We then lemmatize the tokens with the WordNet network.
TW-IDF tries to catch the different nuances of a word, by only counting the different links to other words in a window of 4.
TF-IDF and Okapi-BM25 are two different algorithms that are based on the term frequency of a word in a document They both then normalize the term-frequency in order to take into account :
- The size of the document
- The occurence of a word in a document (i.e. the normalized term weight difference won't be the same if a word is seen 1 time vs 2 times than if a word appears 100 times vs 101 times).