
Keras wrapper class for Normalized Gradient Descent from kmkolasinski/max-normed-optimizer, which can be applied to almost all Keras optimizers. Partially implements Block-Normalized Gradient Method: An Empirical Study for Training Deep Neural Network for all base Keras optimizers, and allows flexibility to choose any normalizing function. It does not implement adaptive learning rates however.
The wrapper class can also be extended to allow Gradient Masking and Gradient Clipping using custom norm metrics.
Wrapper classes :
NormalizedOptimizer: To normalize of gradient by the norm of that gradient.ClippedOptimizer: To clip the gradient by the norm of that gradient. Note: Clips by Local Norm only !
There are several normalization functions available to the NormalizedOptimizer class which wraps another Keras Optimizer. The available normalization functions are :
- l1 :
sum(abs(grad)). L1 normalization (here called max-normalization). - l2 :
sqrt(sum(square(grad))). L2 normalization (Frobenius norm) is the default normalization. - l1_l2 : Average of
l1andl2normalizations - avg_l1 :
mean(abs(grad)). Similar to L1 norm, however takes average instead of sum. - avg_l2 :
sqrt(mean(square(grad))). Similar to L2 norm, however takes average instead of sum. - avg_l1_l2 : Average of
avg_l1andavg_l2normalizations. - max :
max(abs(grad)). Takes the maximum as the normalizer. Ensures largest gradient = 1. - min_max : Average of
max(abs(grad))andmin(abs(grad)). - std : Uses the standard deviation of the gradient as normalization.
from keras.optimizers import Adam, SGD
from optimizer import NormalizedOptimizer, ClippedOptimizer
sgd = SGD(0.01, momentum=0.9, nesterov=True)
sgd = NormalizedOptimizer(sgd, normalization='l2')
adam = Adam(0.001)
adam = ClippedOptimizer(adam, normalization='l2', clipnorm=0.5)Apart from the above normalizations, it also possible to dynamically add more normalizers at run time. The normalization function must take a single Tensor as input and output a normalized Tensor.
The class method NormalizedOptimizer.set_normalization_function(func_name, normalization_fn) can be used to register new normalizers dynamically.
However, care must be taken to register these custom normalizers prior to loading a Keras Model (ex : load_model will fail otherwise).
from keras.optimizers import Adam
from optimizer import NormalizedOptimizer
from keras import backend as K
# dummy normalizer which is basically `avg_l1` normalizer
def dummy_normalization(grad):
norm = K.mean(K.abs(grad)) + K.epsilon()
return norm
# give the new normalizer a name
normalizer_name = 'mean`
NormalizedOptimizer.set_normalization_function(normalizer_name, dummy_normalization)
# now these models can be used just like before
sgd = SGD(0.1)
sgd = NormalizedOptimizer(sgd, normalization=normalizer_name)
adam = Adam(0.001)
adam = ClippedNormalization(adam, normalization=normalizer_name, clipnorm=0.5)We optimize the loss function :
L(x) = 0.5 x^T Q x + b^T x
where Q is random positive-definite matrix, b is a random vector
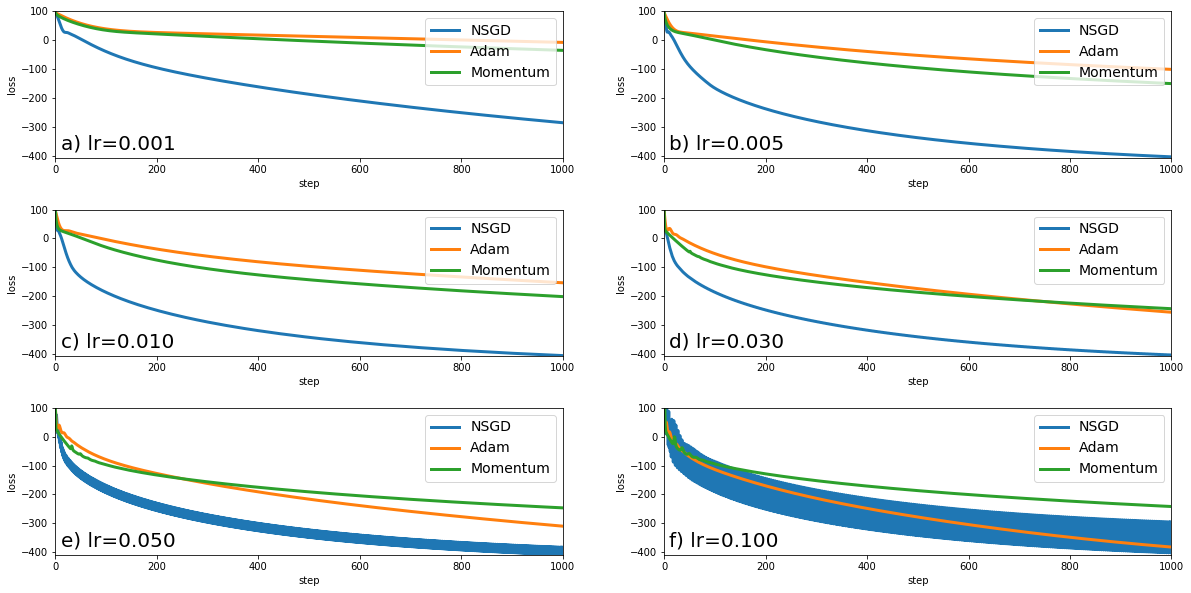

We also inspect how the initial choice of learning rate affects Normalized Adam for a convex optimization problem below.

Model is same as in the Tensorflow codebase kmkolasinski/max-normed-optimizer
* 30 dense layers of size 128.
* After each layer Batchnormalization is applied then dropout at level 0.2
* Small l2 regularization is added to the weights of the network

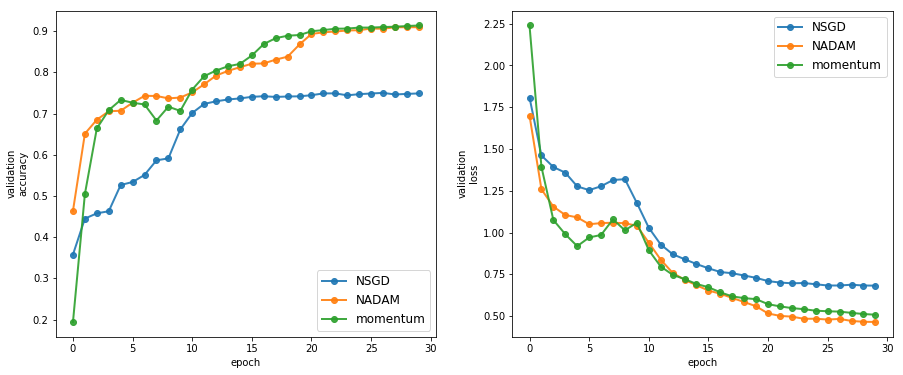
The implementation of the model is kept same as in the Tensorflow repository.


- Keras 2.1.6+
- Tensorflow / Theano (CNTK not tested, but should work)