各种语言实现代码:Go Java JavaScript Rust
默认使用 Go 语言实现。
树是一种数据结构,它是由 n(n>=0)个结点组成一个具有层次关系的集合。因为它看起来像一棵倒挂的树,所以把它叫做树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个结点有零个或多个子结点。
- 没有父结点的结点称为根结点。
- 每一个非根结点有且只有一个父结点。
- 除了根结点外,每个子结点可以分为多个不相交的子树。
二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
树的结点(node):包含一个数据元素及若干指向子树的分支。
根节点(root node):树的起始结点。
子结点(child node):结点的子树的根称为该结点的孩子。
子孙结点:以某结点为根的子树中任一结点都称为该结点的子孙。
叶子结点:也叫终端结点,是度为 0 的结点。
树的深度:树中最大的结点层。
遍历是对树的一种最基本的运算,遍历二叉树就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。
前序遍历
首先访问根,再先序遍历左(右)子树,最后先序遍历右(左)子树。
中序遍历
首先中序遍历左(右)子树,再访问根,最后中序遍历右(左)子树。
后序遍历
首先后序遍历左(右)子树,再后序遍历右(左)子树,最后访问根。
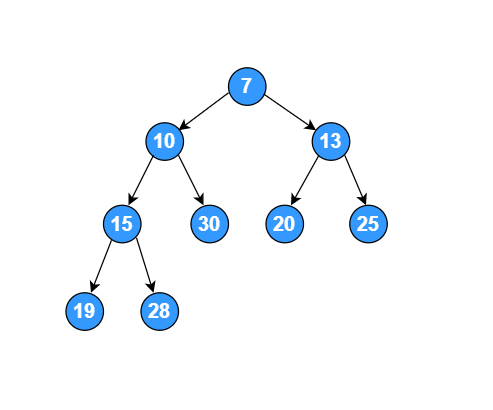
如下面的二叉树,分别使用前序、中序、后续遍历。
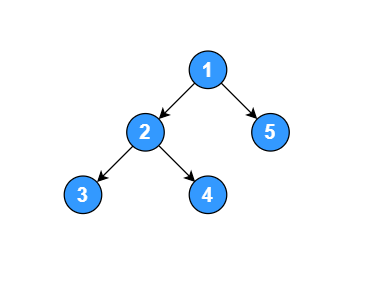
创建二叉树节点结构体:
type BinaryTreeNode struct {
no int // 编号
left *BinaryTreeNode // 左子节点
right *BinaryTreeNode // 右子节点
}前序遍历:
func preOrder(node *BinaryTreeNode) {
if node == nil {
return
}
// 当前节点
fmt.Println(node)
// 遍历左子树
preOrder(node.left)
// 遍历右子树
preOrder(node.right)
}中序遍历:
func infixOrder(node *BinaryTreeNode) {
if node == nil {
return
}
// 遍历左子树
infixOrder(node.left)
// 当前节点
fmt.Println(node)
// 遍历右子树
infixOrder(node.right)
}后续遍历:
func postOrder(node *BinaryTreeNode) {
if node == nil {
return
}
// 遍历左子树
postOrder(node.left)
// 遍历右子树
postOrder(node.right)
// 当前节点
fmt.Println(node)
}手动初始化节点函数:
func initNode() *BinaryTreeNode {
root := &BinaryTreeNode{no: 1}
node2 := &BinaryTreeNode{no: 2}
node3 := &BinaryTreeNode{no: 3}
node4 := &BinaryTreeNode{no: 4}
node5 := &BinaryTreeNode{no: 5}
// 手动建立树的关系
root.left = node2
root.right = node5
node2.left = node3
node2.right = node4
return root
}测试代码:
func TestOrder(t *testing.T) {
root := initNode()
fmt.Println("======前序遍历======")
preOrder(root)
fmt.Println("======中续遍历======")
infixOrder(root)
fmt.Println("======后续遍历======")
postOrder(root)
}运行:
golang/datastructure>go test -v -run ^TestOrder$ ./tree/binary_tree
=== RUN TestOrder
======前序遍历======
no:1
no:2
no:3
no:4
no:5
======中续遍历======
no:3
no:2
no:4
no:1
no:5
======后续遍历======
no:3
no:4
no:2
no:5
no:1前序查找
func preOrderSearch(node *BinaryTreeNode, no int) *BinaryTreeNode {
if node == nil {
return nil
}
fmt.Println("进入查找")
if node.no == no {
return node
}
// 左边查找
returnNode := preOrderSearch(node.left, no)
if returnNode != nil {
// 左边找到了节点,返回
return returnNode
}
// 右边查找
return preOrderSearch(node.right, no)
}中序查找
func infixOrderSearch(node *BinaryTreeNode, no int) *BinaryTreeNode {
if node == nil {
return nil
}
// 左边查找
returnNode := infixOrderSearch(node.left, no)
if returnNode != nil {
// 左边找到了节点,返回
return returnNode
}
fmt.Println("进入查找")
if node.no == no {
return node
}
// 右边查找
return infixOrderSearch(node.right, no)
}后续查找
func postOrderSearch(node *BinaryTreeNode, no int) *BinaryTreeNode {
if node == nil {
return nil
}
var returnNode *BinaryTreeNode
// 左边查找
returnNode = postOrderSearch(node.left, no)
if returnNode != nil {
// 左边找到了节点,返回
return returnNode
}
// 右边查找
returnNode = postOrderSearch(node.right, no)
if returnNode != nil {
// 右边找到了节点,返回
return returnNode
}
fmt.Println("进入查找")
if node.no == no {
returnNode = node
}
return returnNode
}查找 no = 4 的节点,分别输出前序、中序、后续查找的查找次数:
func TestSearch(t *testing.T) {
root := initNode()
no := 4
fmt.Println("======前序查找======")
fmt.Printf("查找no=%v\n", no)
node := preOrderSearch(root, no)
fmt.Printf("查找结果: no=%v\n", node.no)
no = 4
fmt.Println("======中序查找======")
fmt.Printf("查找no=%v\n", no)
node = infixOrderSearch(root, no)
fmt.Printf("查找结果: no=%v\n", node.no)
no = 4
fmt.Println("======后序查找======")
fmt.Printf("查找no=%v\n", no)
node = postOrderSearch(root, no)
fmt.Printf("查找结果: no=%v\n", node.no)
}运行:
golang/datastructure>go test -v -run ^TestSearch$ ./tree/binary_tree
=== RUN TestSearch
======前序查找======
查找no=4
进入查找
进入查找
进入查找
进入查找
查找结果: no=4
======中序查找======
查找no=4
进入查找
进入查找
进入查找
查找结果: no=4
======后序查找======
查找no=4
进入查找
进入查找
查找结果: no=4从输出结果中可看出前序、中序、后续查找分别查找了 4, 3, 2 次。
1.如果当前节点是叶子节点,直接删除。
2.如果当前节点是非叶子节点,删除该树。
代码如下:
func deleteNode(node *BinaryTreeNode, no int) {
// 当前节点为空直接返回
if node == nil {
return
}
// 如果左子节点就是要删除结点,就将 binaryTree.left = nil, 并且就返回(结束递归删除)
if node.left.no == no {
node.left = nil
return
}
// 如果右子节点就是要删除结点,就将 binaryTree.right = nil, 并且就返回(结束递归删除)
if node.right.no == no {
node.right = nil
return
}
// 左边查找删除
deleteNode(node.left, no)
// 右边查找删除
deleteNode(node.right, no)
}测试函数:
func TestDelete(t *testing.T) {
root := initNode()
no := 2
fmt.Println("======删除前======")
preOrder(root)
deleteNode(root, no)
// 被删除的节点恰好是 root 节点
if root.no == no {
root = nil
}
fmt.Println("======删除后======")
if root == nil {
fmt.Println("二叉树为nil")
} else {
preOrder(root)
}
}运行:
golang/datastructure>go test -v -run ^TestDelete$ ./tree/binary_tree
=== RUN TestDelete
======删除前======
no:1
no:2
no:3
no:4
no:5
======删除后======
no:1
no:5将二叉树存储在一个数组中,通过存储元素的下标反映元素之间的父子关系。用一组连续的存储单元存放二叉树中的结点元素,一般按照二叉树结点自上向下、自左向右的顺序存储。使用此存储方式,结点的前驱和后继不一定是它们在逻辑上的邻接关系,非常适用于满二叉树和完全二叉树。采用顺序存储能够最大地节省存储空间,可以利用数组元素下标值确定结点在二叉树中的位置以及结点之间的关系。
计算顺序存储二叉树节点下标的方法如下:
- 第 n 个节点的左子节点下标为 2*n+1。
- 第 n 个节点的右子节点下标为 2*n+2。
- 第 n 个节点的父节点下标为 (n-1)/2。
其中 n 表示二叉树中第几个节点,对应该节点在数组中的位置,位置从 0 开始,顺序为从上之下,从左至右。
下图是一个数组转换成的二叉树,其中红色的数字表示每个节点对应在数组中下标:
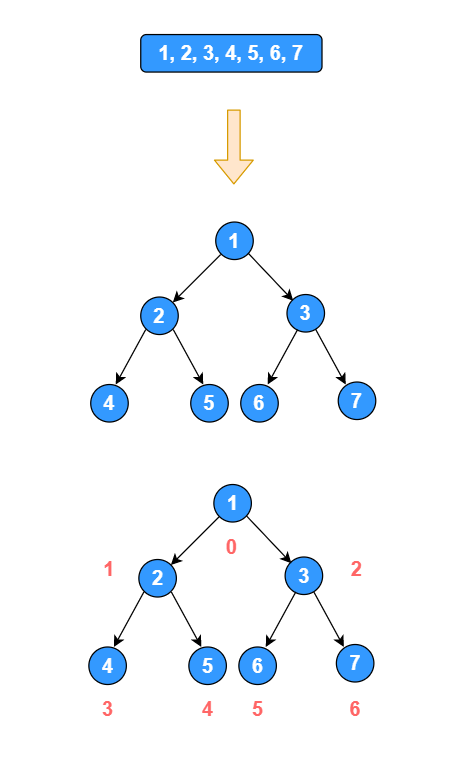
接下来实现上述使用顺序存储的二叉树,对其进行前序、中序、后续遍历。
创建顺序存储的二叉树:
type ArrayBinaryTree struct {
array []int // 存储节点数组
}创建二叉树实例的函数:
func NewArrayBinaryTree(array []int) *ArrayBinaryTree {
return &ArrayBinaryTree{array}
}前序遍历:
func (arrBinaryTree *ArrayBinaryTree) PreOrder() {
arrBinaryTree.preOrderFromIndex(0)
}
func (arrBinaryTree *ArrayBinaryTree) preOrderFromIndex(index int) {
length := len(arrBinaryTree.array)
if arrBinaryTree.array == nil || length == 0 ||index >= length {
return
}
// 当前节点
fmt.Println(arrBinaryTree.array[index])
// 左子节点下标
leftIndex := 2 * index + 1
// 右子节点下标
rightIndex := 2 * index + 2
// 向左遍历
arrBinaryTree.preOrderFromIndex(leftIndex)
// 向右遍历
arrBinaryTree.preOrderFromIndex(rightIndex)
}测试代码:
func TestSeqStorage(t *testing.T) {
nos := []int{1, 2, 3, 4, 5, 6, 7}
arrayBinaryTree := NewArrayBinaryTree(nos)
fmt.Println("======前序遍历======")
arrayBinaryTree.PreOrder()
}运行:
golang/datastructure>go test -v -run ^TestSeqStorage$ ./tree/binary_tree
=== RUN TestSeqStorage
======前序遍历======
1
2
4
5
3
6
7中序、后续遍历和二叉树遍历类似。
对于 n 个结点的二叉树,在二叉树中有 n+1 个空链域,用这些空链域存放该结点的前驱结点和后继结点的指针,这些指针称为线索,加上线索的二叉树称为线索二叉树。对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化。根据线索性质的不同,线索二叉树可分为前序线索二叉树、中序线索二叉树和后序线索二叉树三种。
下图是一个被线索化的二叉树:
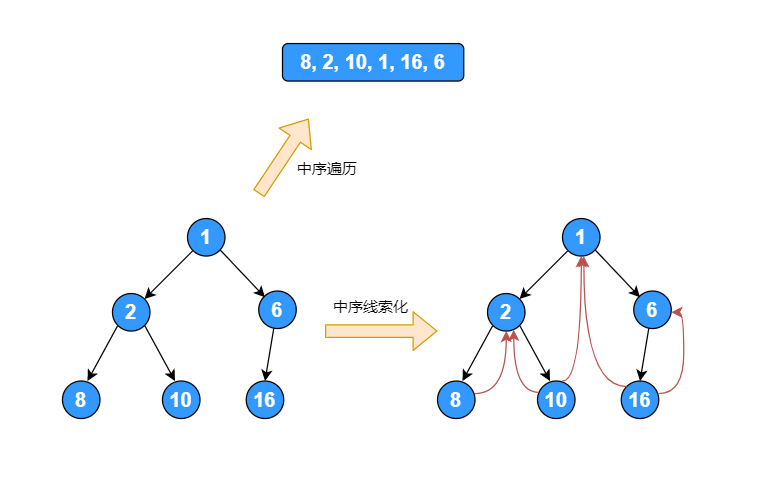
当二叉树线索化后,增加 leftTag 和 rightTag 两个标记,leftTag 和 rightTag 表示不同值时,情况如下:
- 如果 leftTag = 0, left 表示左子节点, 如果 leftTag = 1, left 表示前驱节点。
- 如果 rightTag = 0, right 表示右子节点, 如果为 rightTag = 1, right 表示后继节点。
中序线索化二叉树
实现上图中二叉树的中序线索化。
创建结构体:
type ThreadedBinaryTreeNode struct {
no int // 编号
left *ThreadedBinaryTreeNode // 左子节点
right *ThreadedBinaryTreeNode // 右子节点
// 增加两个标记
leftTag int
rightTag int
}
// 从最左边至最右边查找指定节点(测试使用)
func (threadedNode *ThreadedBinaryTreeNode) search(no int) *ThreadedBinaryTreeNode {
leftChildNode := threadedNode
for leftChildNode.left != nil {
leftChildNode = leftChildNode.left
}
node := leftChildNode
// 遍历右边
for node != nil {
if node.no == no {
break
}
node = node.right
}
return node
}中序线索化函数:
var previous *ThreadedBinaryTreeNode // 记录遍历时的上一个结点
// 中序线索化二叉树
func infixThreadTree(node *ThreadedBinaryTreeNode) {
if node == nil {
return
}
// 线索化左子节点
infixThreadTree(node.left)
// 线索化当前结点
// 如果 left 为 nil, 处理前驱节点
if node.left == nil {
node.left = previous
node.leftTag = 1 // 修改标记
}
// 如果 right 为 nil, 处理后继节点
if previous != nil && previous.right == nil {
previous.right = node // 将上一个节点的后继节点指向当前节点
previous.rightTag = 1 // 修改标记
}
// 修改 previous
previous = node
// 线索化右子节点
infixThreadTree(node.right)
}手动初始化节点函数:
func initThreadedNode() *ThreadedBinaryTreeNode {
root := &ThreadedBinaryTreeNode{no: 1}
node2 := &ThreadedBinaryTreeNode{no: 2}
node3 := &ThreadedBinaryTreeNode{no: 6}
node4 := &ThreadedBinaryTreeNode{no: 8}
node5 := &ThreadedBinaryTreeNode{no: 10}
node6 := &ThreadedBinaryTreeNode{no: 16}
// 手动建立树的关系
root.left = node2
root.right = node3
node2.left = node4
node2.right = node5
node3.left = node6
return root
}测试代码:
func TestInfixThreadedTree(t *testing.T) {
root := initThreadedNode()
infixThreadTree(root)
// 获取 no = 10 的结点,输出前驱和后继节点
node := root.search(10)
fmt.Printf("no=%v的前驱节点为%v\n", node.no, node.left.no)
fmt.Printf("no=%v的后继节点为%v\n", node.no, node.right.no)
}运行:
golang/datastructure>go test -v -run ^TestInfixThreadedTree$ ./tree/binary_tree
=== RUN TestInfixThreadedTree
no=10的前驱节点为2
no=10的后继节点为1中序遍历线索化二叉树
被线索化后的二次树不能按原来二叉树的方式遍历,因为叶子节点的左右节点指针指向了实际的节点,否则会出现死递归。可使用线性方式遍历线索化二叉树。
代码如下:
// 中序遍历线索化二叉树
func infixOrderThreadedTree(node *ThreadedBinaryTreeNode) {
currentNode := node
for currentNode != nil {
// 循环找到 leftTag = 0 的节点, 第一个找到的就是最左边的叶子节点
for currentNode.leftTag == 0 {
currentNode = currentNode.left
}
// 输出当前节点
fmt.Printf("id:%v\n", currentNode.no)
// 循环输出后继节点
for currentNode.rightTag == 1 {
currentNode = currentNode.right
fmt.Printf("id:%v\n", currentNode.no)
}
// 移动当前节点
currentNode = currentNode.right
}
}测试代码:
func TestInfixOrderThreadedTree(t *testing.T) {
root := initThreadedNode()
infixThreadTree(root)
infixOrderThreadedTree(root)
}运行:
golang/datastructure>go test -v -run ^TestInfixOrderThreadedTree$ ./tree/binary_tree
=== RUN TestInfixOrderThreadedTree
id:8
id:2
id:10
id:1
id:16
id:6堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序。
堆是一个具有特殊性质的完全二叉树,任意非叶子节点的值大于或等于左右子节点的值,或者任意非叶子节点的值小于或等于左右子节点的值。
大顶堆
在一个完全二叉树中,任意非叶子节点的值大于或等于左右子节点的值。
小顶堆
在一个完全二叉树中,任意非叶子节点的值小于或等于左右子节点的值。
步骤:
- 将待排序的序列构造成大顶堆或小顶堆(升序大顶堆,降序小顶堆)。
- 堆顶的根节点就是序列的最大值。
- 将堆顶的根节点和叶子节点进交换,此时叶子节点就是最大值。
- 对于剩余的元素重新构造成大顶堆或小顶堆,重复第 2 步,最后就是有序的。
示例:
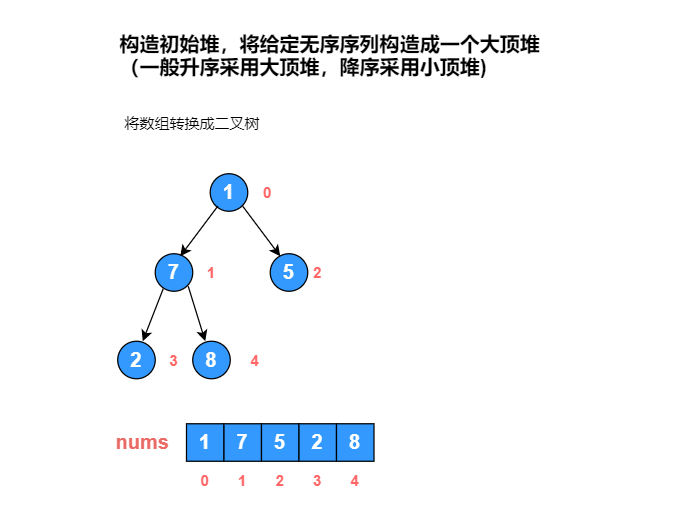
使用堆排序对数组 [1, 7, 5, 2, 8] 进行从小到大排序。
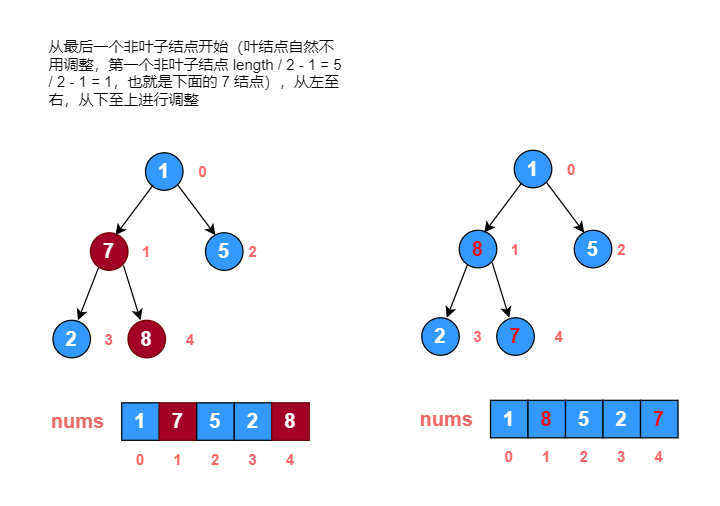
最后一个非叶子节点计算公式:length / 2 - 1
第 n 个下标节点的左子节点计算公式:2 * n + 1
第 n 个下标节点的右子节点计算公式:2 * n + 2
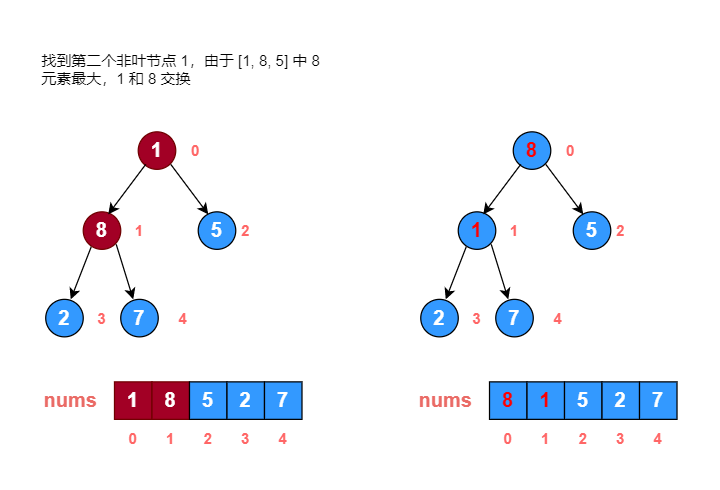
画图分析:
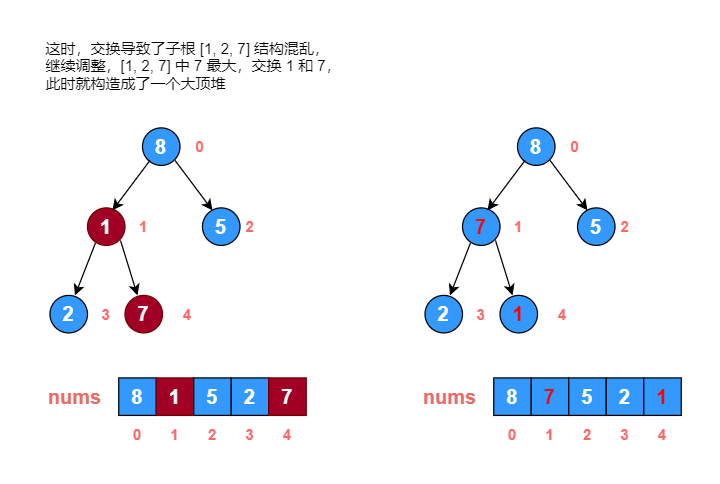
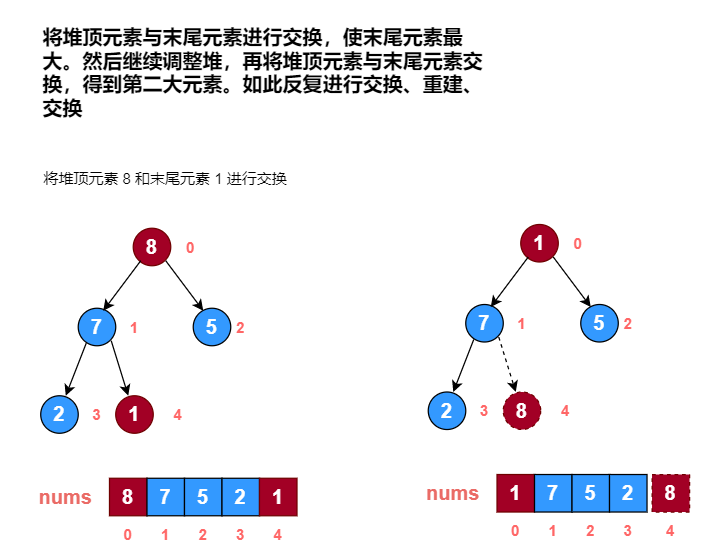
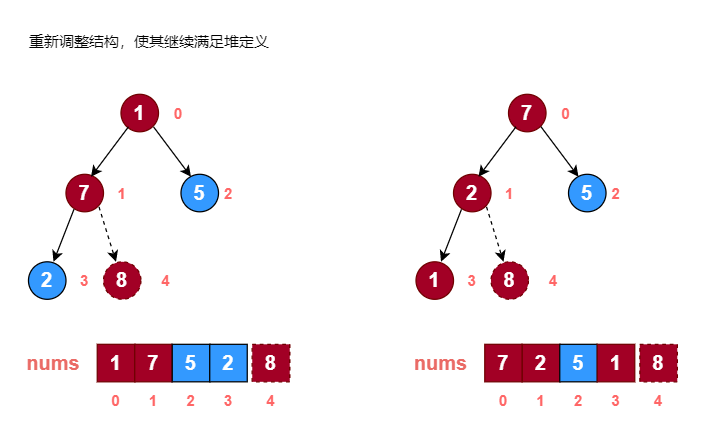
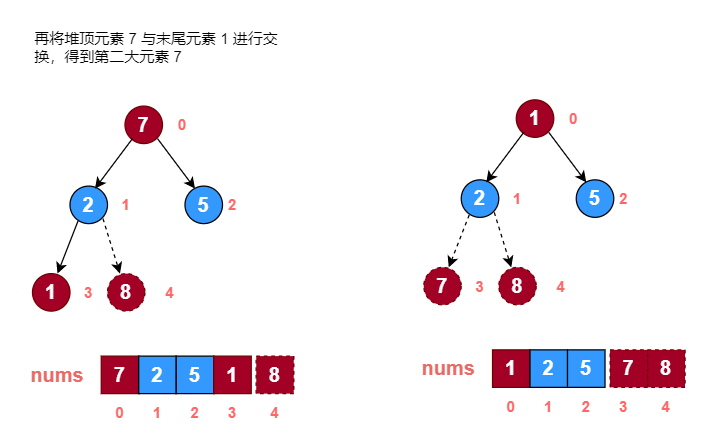
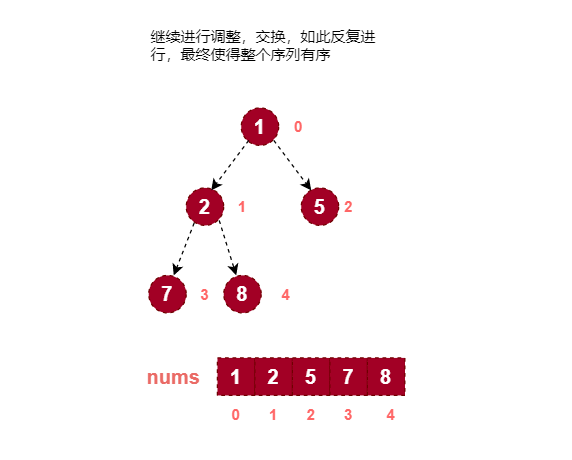
代码实现:
func heapSort(nums[] int) {
if nums == nil {
return
}
// 调整第 1 个节点 [1 7 5 2 8] => [1 8 5 2 7]
// adjustHeap(nums, 1, len(nums))
// 调整第 0 个节点 [1 8 5 2 7] => [8 7 5 2 1]
// adjustHeap(nums, 0, len(nums))
// 调整所有叶子节点, 构造成一个大顶堆
// 堆顶的根节点就是序列的最大值
for i := len(nums) / 2 - 1; i >= 0; i-- {
adjustHeap(nums, i, len(nums))
}
// 将堆顶的根节点和叶子节点进交换,此时叶子节点就是最大值
for i := len(nums) - 1; i > 0; i-- {
nums[0], nums[i] = nums[i], nums[0]
// 对于剩余的元素重新构造成大顶堆
adjustHeap(nums, 0, i)
}
}
// 调整堆, 使其成为大顶堆
// i: 当前需要调整的节点下标
// count: 调整次数
func adjustHeap(nums[] int, i, count int) {
temp := nums[i] // 当前节点
for j := 2 * i + 1; j < count; j = 2 * j + 1 {
// 左子节点小于右子节点
if j + 1 < count && nums[j] < nums[j + 1] {
j++ // 指向右子节点
}
// 子节点比父节点大
if nums[j] > temp {
// 将节点赋值给父节点
nums[i] = nums[j]
i = j // 修改成下一个子节点
} else {
// 跳出循环,因为调整顺序为从左至右,从下至上,子树是已经调整好的堆
break
}
}
// 放入到最终位置
nums[i] = temp
}测试代码:
func TestHeapSort(t *testing.T) {
nums := []int{1, 7, 5, 2, 8}
fmt.Printf("排序前: %v\n", nums)
heapSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/datastructure>go test -v -run ^TestHeapSort$ ./tree/binary_tree
=== RUN TestHeapSort
排序前: [1 7 5 2 8]
排序后: [1 2 5 7 8]有 N 个权值作为 N 个叶子结点,构造一棵二叉树,如果该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。哈夫曼树又称为最优树。
路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为 1,则从根结点到第 L 层结点的路径长度为 L-1。
结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度
树的带权路径长度规定为所有叶子节点的带权路径长度之和,记为 WPL。
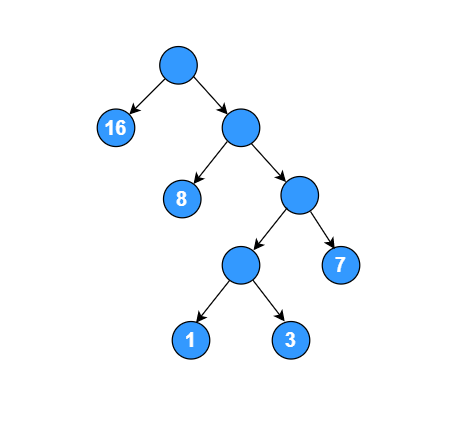
WPL = (2 - 1) * 16 + (3 - 1) * 8 + (4 - 1) * 7 + (5 - 1) * 1 + (5 - 1) * 3
假设有 n 个权值,则构造出的哈夫曼树有 n 个叶子结点。n 个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
- 将 w1、w2、…、wn 看成一个序列, 每个数据可以看做一个权值。
- 将序列从小到大排序。
- 选出两个根节点的权值最小的树合并,作为一棵新树的左、右子节点,且新树的根节点权值为其左、右子树根节点权值之和。
- 从序列中删除选出的两个节点,并将新树加入序列。
- 重复 2、3、4 步,直到序列中只剩一棵树为止,该树即为所求得的哈夫曼树。
示例:
将序列 1, 7, 3, 8, 16 构造成哈夫曼树
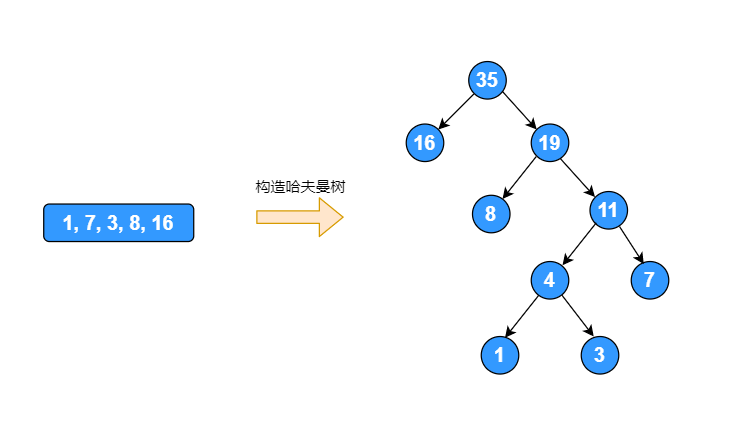
代码实现:
type Node struct {
value int // 权值
left *Node // 左子节点
right *Node // 右子节点
}
type Nodes []*Node
func (nodes Nodes) Len() int {
return len(nodes)
}
func (nodes Nodes) Less(i, j int) bool {
return nodes[i].value < nodes[j].value
}
func (nodes Nodes) Swap(i, j int) {
nodes[i], nodes[j] = nodes[j], nodes[i]
}// 构建哈夫曼树
func createHuffmanTree(nums[] int) *Node {
if nums == nil {
return nil
}
var nodes = make(Nodes, 0)
for _, num := range nums {
nodes = append(nodes, &Node{value: num})
}
for len(nodes) > 1 {
// 排序
sort.Sort(nodes)
fmt.Println(nodes)
left := nodes[0] // 权值最小的元素
right := nodes[1] // 权值第二小的元素
// 创建新的根节点
root := &Node{value: left.value + right.value}
// 构建二叉树
root.left = left
root.right = right
// 删除处理过的节点
nodes = deleteNode(nodes, left)
nodes = deleteNode(nodes, right)
// 将二叉树加入到 nodes
nodes = append(nodes, root)
}
return nodes[0]
}
func preOrder(node *Node) {
if node == nil {
return
}
fmt.Println(node.value)
preOrder(node.left)
preOrder(node.right)
}
func deleteNode(nodes Nodes, node *Node) Nodes {
for i := 0; i < len(nodes); i++ {
if nodes[i].value == node.value {
nodes = append(nodes[:i], nodes[i + 1:]...)
i-- // 删除了一个元素,修正下标
}
}
return nodes
}测试代码:
func TestHuffmanTree(t *testing.T) {
nums := []int{1, 7, 3, 8, 16}
root := createHuffmanTree(nums)
preOrder(root)
}运行:
golang/datastructure>go test -v -run ^TestHuffmanTree$ ./tree/huffman_tree
=== RUN TestHuffmanTree
[value:1, value:3, value:7, value:8, value:16, ]
[value:4, value:7, value:8, value:16, ]
[value:8, value:11, value:16, ]
[value:16, value:19, ]
35
16
19
8
11
4
1
3
7哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码。
假设有一个字符串 i love go,共有 9 个字符(包括空格),用 ascii 码表示如下:
i: 105 空格: 32 l: 108 o: 111 v: 118 e: 101 空格: 32 g: 103 o: 111
数据都是以二进制的形式传递,对应的二进制表示为:
01101001 00100000 01101100 01101111 01110110 01100101 00100000 01100111 01101111
一个字符占 8 位,总的长度为 72 位。
ascii 码转二进制工具:https://www.mokuge.com/tool/asciito16。
统计每个字符出现的次数,每个字符出现的次数分别为 i: 1 次、l: 1 次、o: 2 次、v: 1 次、e: 1 次、g: 1 次、空格: 2 次,将次数作为权值,构建一颗哈夫曼树如下:
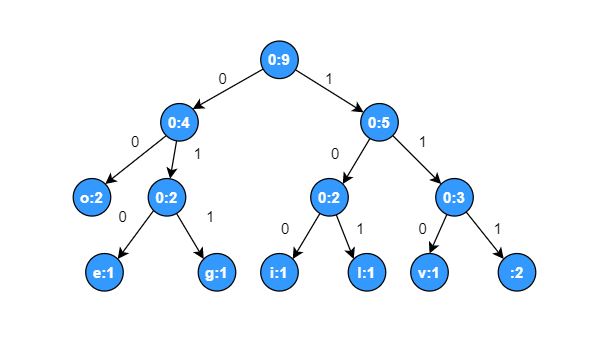
转成哈夫曼树时顺序不同,每个字符在树中的位置也会不同,但是最后生成的哈夫曼编码长度不变。
根据哈夫曼编码,给每个字符串规定前缀编码,节点左边的路径为 0,节点右边的路径为 1,则上述字符串每个字符对应的编码如下:
o: 00 e: 010 g: 011 i: 100 l: 101 v: 110 空格: 111
将上述编码按照字符串的顺序排列。
100 111 101 00 110 010 111 011 00
总长度为 25 。
此编码满足前缀编码,即字符的编码都不能是其他字符编码的前缀,不会造成匹配的多义性。
转哈夫曼树
步骤:
- 获取到要压缩的数据对应的字节数组。
- 统计每个字节出现的次数, 将字节作为 key, 次数作为 value。
- 定义树的存储结构,使用字节作为域(data), 出现的次数作为权值(weight)。
- 每一个 key 对应一个节点, 构建哈夫曼树。
代码实现:
// 定义树的存储结构,使用字节作为域(data), 出现的次数作为权值(weight)
type DataNode struct {
data byte // 保存字节
weight int // 保存出现的次数
left *DataNode
right *DataNode
}
type DataNodes []*DataNode
func (nodes DataNodes) Len() int {
return len(nodes)
}
func (nodes DataNodes) Less(i, j int) bool {
return nodes[i].weight < nodes[j].weight
}
func (nodes DataNodes) Swap(i, j int) {
nodes[i], nodes[j] = nodes[j], nodes[i]
}
func (nodes DataNodes) String() string {
str := "["
for _, node := range nodes {
str += fmt.Sprintf("{data:%v, value:%d}, ", node.data, node.weight)
}
str += "]"
return str
}// 构建哈夫曼树
func buildHuffmanTree(bytes []byte) *DataNode {
// 统计每个字节出现的次数, 将字节作为 key, 次数作为 value
byteMap := count(bytes)
dataNodes := initDataNode(byteMap)
// 每一个 key 对应一个节点, 构建哈夫曼树
for len(dataNodes) > 1 {
// 稳定排序
sort.Stable(dataNodes)
left := dataNodes[0] // 权值最小的元素
right := dataNodes[1] // 权值第二小的元素
// 创建新的根节点
root := &DataNode{weight: left.weight + right.weight}
// 构建二叉树
root.left = left
root.right = right
// 删除处理过的节点
dataNodes = deleteDataNode(dataNodes, left)
dataNodes = deleteDataNode(dataNodes, right)
// 将二叉树加入到 nodes
dataNodes = append(dataNodes, root)
}
return dataNodes[0]
}
func count(bytes []byte) map[byte]int {
count := make(map[byte]int, len(bytes))
for _, key := range bytes {
value, ok := count[key]
if ok {
count[key] = value + 1
} else {
count[key] = 1
}
}
return count
}
func initDataNode(byteMap map[byte]int) DataNodes {
dataNodes := make(DataNodes, 0)
var slice []string
// 保存 key
for key := range byteMap {
slice = append(slice, strconv.Itoa(int(key)))
}
// 排序,保证每次遍历 key 的顺序一致
sort.Strings(slice)
for _, data := range slice {
n, _ := strconv.Atoi(data)
key := byte(n)
dataNodes = append(dataNodes, &DataNode{data: key, weight: byteMap[key]})
}
return dataNodes
}
func dataNodePreOrder(node *DataNode) {
if node == nil {
return
}
fmt.Printf("{data:%v, value:%d}\n", node.data, node.weight)
dataNodePreOrder(node.left)
dataNodePreOrder(node.right)
}
func deleteDataNode(nodes DataNodes, node *DataNode) DataNodes {
for i := 0; i < len(nodes); i++ {
if nodes[i].data == node.data {
nodes = append(nodes[:i], nodes[i + 1:]...)
// 避免删除重复的数据
return nodes
}
}
return nodes
}测试代码:
func TestHuffmanCode(t *testing.T) {
msg := "i love go"
// 获取到要压缩的数据对应的字节数组
bytes := []byte(msg)
// 构建哈夫曼树
root := buildHuffmanTree(bytes)
fmt.Println("======前序遍历======")
dataNodePreOrder(root)
}运行:
golang/datastructure>go test -v -run ^TestHuffmanCode$ ./tree/huffman_tree
=== RUN TestHuffmanCode
======前序遍历======
{data:0, value:9}
{data:0, value:4}
{data:32, value:2}
{data:0, value:2}
{data:101, value:1}
{data:103, value:1}
{data:0, value:5}
{data:0, value:2}
{data:105, value:1}
{data:108, value:1}
{data:0, value:3}
{data:118, value:1}
{data:111, value:2}编码
步骤:
- 根据原始数据,和哈夫曼码表,将编码顺序拼接。
- 以每八位作为一个字节的二进制数,转成十进制,并顺序放入切片中。
代码实现:
// 获取哈夫曼码表
// 生成字符和编码对应关系
// node: 哈夫曼码树
// 返回 map[32:00 101:010 103:011 105:100 108:101 111:111 118:110]
func getCodes(node *DataNode) map[byte]string {
codeMap := make(map[byte]string, 0)
var codes []string
if node != nil {
getLeafCodes(node.left, "0", codes, codeMap)
getLeafCodes(node.right, "1", codes, codeMap)
}
return codeMap
}
// 递归拼接 0 或 1, 形成 101:010
func getLeafCodes(node *DataNode, flag string, codes []string, codeMap map[byte]string) {
codes = append(codes, flag)
if node != nil {
if node.data == 0 { // 表示非叶子节点
getLeafCodes(node.left, "0", codes, codeMap)
getLeafCodes(node.right, "1", codes, codeMap)
} else { // 叶子节点
codeMap[node.data] = strings.Join(codes, "")
}
}
}// 将原始数据和码表编码成字节切片
// source: 原始字节切片
// codeMap: 哈夫曼码表
// 返回: 编码后的字节切片
func encodeBytes(source []byte, codeMap map[byte]string) []byte {
var codes []string
for _, b := range source {
codeStr, ok := codeMap[b]
if ok {
codes = append(codes, codeStr)
}
}
// 转成编码序列
codeString := strings.Join(codes, "")
fmt.Printf("编码序列:%s\n", codeString) // 1000010111111001000011111
// 将编码序列每八位看成一个字节,放入字节切片中
// 八位看成一个字节
// 10000101 11111001 00001111 1
targetByteLength := (len(codeString) + 7) / 8
// 增加 1 个字节,用来表示最后一个字节的有效比特位
targetBytes := make([]byte, targetByteLength + 1)
start, end := 0, 0
lastBitLength := 8
for i := 0; i < targetByteLength; i++ {
start = i * 8
end = (i + 1) * 8
if end > len(codeString) {
end = len(codeString)
// 记录不足八位的有效长度
lastBitLength = len(codeString) % 8
}
// 每八位截取一次作为一个字节
bitStr := codeString[start: end]
n, _ := strconv.ParseInt(bitStr, 2, 64)
targetBytes[i] = byte(n)
}
// 最后一个字节记录原始序列中最后一个字节真实有效的比特长度
targetBytes[targetByteLength] = byte(lastBitLength)
return targetBytes
}测试代码:
func TestHuffmanCode(t *testing.T) {
msg := "i love go"
// 获取到要压缩的数据对应的字节数组
bytes := []byte(msg)
// 构建哈夫曼树
root := buildHuffmanTree(bytes)
fmt.Println("======创建码表======")
// 获取码表
codeMap := getCodes(root)
fmt.Println(codeMap)
fmt.Printf("未编码时的长度:%d\n", len(bytes))
fmt.Println("======编码======")
// 编码
encodeBytes := encodeBytes(bytes, codeMap)
fmt.Println(encodeBytes)
fmt.Printf("编码后的长度:%d\n", len(encodeBytes))
}运行:
golang/datastructure>go test -v -run ^TestHuffmanCode$ ./tree/huffman_tree
=== RUN TestHuffmanCode
======创建码表======
map[32:00 101:010 103:011 105:100 108:101 111:111 118:110]
未编码时的长度:9
======编码======
编码序列:1000010111111001000011111
[133 249 15 1 1]
编码后的长度:5解码
步骤:
- 将编码后的字节切片,还原成原始字符串序列,每个字节对应八个字符长度(除最后一个字节外)。
- 反转哈夫曼编码表,将 key 作为新编码表的 value,将 value 作为新编码表的 value。
- 从字符串序列起始位置开始,每向右增加一个位置就从反转后的编码中搜索是否存在 key,将 存在的 key 对应的 value 添加到切片中,知道所有的字符串序列搜索完成。
代码实现:
// 将编码后的字节数据按照哈夫曼编码表解码成字节切片
// target: 编码后的字节切片
// codeMap: 哈夫曼码表
// 返回解码后的字节切片
func decodeBytes(target []byte, codeMap map[byte]string) []byte {
var codes []string
codeLength := len(target)
// 实际长度
codeRealLength := codeLength - 1
for i := 0; i < codeRealLength; i++ {
n := int64(target[i])
bitStr := ""
if i != codeRealLength - 1 {
// 除了最后一个字节,不足 8 位,高位补 0
// 如果不补 0,会导致长度不正确
n = n | 256
bitStr = strconv.FormatInt(n, 2)
// 截取最后八位
bitStr = bitStr[len(bitStr) - 8:]
} else { // 最后一个字节
lastBitLength := int(target[codeLength - 1])
bitStr = strconv.FormatInt(n, 2)
if len(bitStr) < lastBitLength {
// 前面补 0
bitStr = strings.Repeat("0", lastBitLength - len(bitStr)) + bitStr
}
}
codes = append(codes, bitStr)
}
sourceString := strings.Join(codes, "") // 拼接成原始序列
fmt.Printf("解码序列:%s\n", sourceString) // 1000010111111001000011111
// 反转哈夫曼编码表
// 32:00 => 00:32
reverseCodeMap := make(map[string]byte, len(codeMap))
for key, value := range codeMap {
reverseCodeMap[value] = key
}
var sourceBytes []byte
var str string
// 根据反转后的哈夫曼编码表,查找对应的字节数值
for i := 0; i < len(sourceString); {
count := 1
for {
if i + count > len(sourceString) {
break
}
str = sourceString[i:i + count]
b, ok := reverseCodeMap[str]
if ok {
// 搜索到就添加到切片中
sourceBytes = append(sourceBytes, b)
break
} else {
count++
}
}
i += count
}
return sourceBytes
}测试代码:
func TestHuffmanCode(t *testing.T) {
msg := "i love go"
// 获取到要压缩的数据对应的字节数组
bytes := []byte(msg)
// 构建哈夫曼树
root := buildHuffmanTree(bytes)
fmt.Println("======前序遍历======")
dataNodePreOrder(root)
fmt.Println("======创建码表======")
// 获取码表
codeMap := getCodes(root)
fmt.Println(codeMap)
fmt.Printf("未编码时的长度:%d\n", len(bytes))
fmt.Println("======编码======")
// 编码
encodeBytes := encodeBytes(bytes, codeMap)
fmt.Println(encodeBytes)
fmt.Printf("编码后的长度:%d\n", len(encodeBytes))
fmt.Println("======解码======")
// 解码
sourceBytes := decodeBytes(encodeBytes, codeMap)
fmt.Printf("解码后的内容:%s\n", string(sourceBytes))
}运行:
E:\Github\datastructure-algorithm\golang\datastructure>go test -v -run ^TestHuffmanCode$ ./tree/huffman_tree
=== RUN TestHuffmanCode
...
======创建码表======
map[32:00 101:010 103:011 105:100 108:101 111:111 118:110]
未编码时的长度:9
======编码======
编码序列:1000010111111001000011111
[133 249 15 1 1]
编码后的长度:5
======解码======
解码序列:1000010111111001000011111
解码后的内容:i love go注意事项
如果文件本身经过压缩处理,使用哈夫曼编码压缩,效率并不会有明显编码。
如果一个文件中的内容重复的数据不多,压缩效果不好很明显。
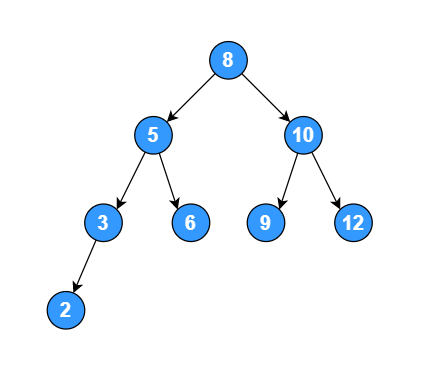
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),也叫二叉搜索树。在一般情况下,查询效率比链表结构要高。对于任何一个非叶子节点,它的左子节点的值小于自身的值,它的右子节点的值大于自身的值,具有这样性质的二叉树称为二叉排序树。
如下是一颗二叉排序树:
定义树结点结构体:
// 树节点结构体
type BinaryTreeNode struct {
no int // 编号
left *BinaryTreeNode // 左子节点
right *BinaryTreeNode // 右子节点
}
func (sortTreeNode *BinaryTreeNode) String() string {
return fmt.Sprintf("no:%d", sortTreeNode.no)
}
// 二叉排序树结构体
type BinarySortTree struct {
root *BinaryTreeNode // 树的根节点
}
func NewBinarySortTree() *BinarySortTree {
return &BinarySortTree{}
}添加节点的方法如下:
// 添加结点
func (sortTree *BinarySortTree) Add(node *BinaryTreeNode) {
if node == nil {
return
}
// 根节点为 nil,要添加的节点作为根节点
if sortTree.root == nil {
sortTree.root = node
return
}
sortTree.add(sortTree.root, node)
}
func (sortTree *BinarySortTree) add(root, node *BinaryTreeNode) {
// 要添加的节点小于根节点
if node.no < root.no {
// 左子节点为 nil,直接添加为左子节点
if root.left == nil {
root.left = node
return
}
// 左递归
sortTree.add(root.left, node)
} else {
// 右子节点为 nil,直接添加为右子节点
if root.right == nil {
root.right = node
return
}
// 右递归
sortTree.add(root.right, node)
}
}
func (sortTree *BinarySortTree) InfixOrder() {
if sortTree.root == nil {
return
}
sortTree.infixOrder(sortTree.root)
}
func (sortTree *BinarySortTree) infixOrder(node *BinaryTreeNode) {
if node == nil {
return
}
sortTree.infixOrder(node.left)
fmt.Println(node)
sortTree.infixOrder(node.right)
}测试代码:
func TestBinarySortTree(t *testing.T) {
nos := []int{8, 5, 10, 3, 6, 9, 12, 2}
binarySortTree := NewBinarySortTree()
for _, no := range nos {
binarySortTree.Add(&BinaryTreeNode{no: no})
}
fmt.Println("======中序遍历======")
binarySortTree.InfixOrder()
}运行:
golang/datastructure>go test -v -run ^TestBinarySortTree$ ./tree/binary_sort_tree
=== RUN TestBinarySortTree
======中序遍历======
no:2
no:3
no:5
no:6
no:8
no:9
no:10
no:12要删除节点时,被删除的节点分以下三种情况:
- 节点是叶子节点直接删除。
- 节点是子节点且只有一颗子树,左子树或右子树。如果被删除的节点是父节点的左子节点,将父节点的左子节点指向该删除节点的子树,如果是父节点的右子节点,则将父节点的右子节点指向该删除节点的子树。
- 节点是子节点且只有两颗子树。从被删除节点的右子节点的左子树中找到最小值的节点,将其删除,然后将该节点的值赋值给被删除的节点。
代码实现:
func (sortTree *BinarySortTree) search(no int) (*BinaryTreeNode, *BinaryTreeNode) {
if sortTree.root == nil {
return nil, nil
}
// 查找的节点就是根节点
if sortTree.root.no == no {
return nil, sortTree.root
}
return sortTree.recursionSearch(sortTree.root, no)
}
// 递归查找指定节点
// 返回查找到的父节点和查找到的节点
func (sortTree *BinarySortTree) recursionSearch(node *BinaryTreeNode, no int) (*BinaryTreeNode, *BinaryTreeNode) {
if node == nil {
return nil, nil
}
if node.left != nil && node.left.no == no {
return node, node.left
}
if node.right != nil && node.right.no == no {
return node, node.right
}
// 判断是往左边还是往右边查找
if no < node.no {
return sortTree.recursionSearch(node.left, no)
} else {
return sortTree.recursionSearch(node.right, no)
}
}
// 删除节点
func (sortTree *BinarySortTree) Delete(no int) {
parentNode, node := sortTree.search(no)
// 没有找到要删除的节点
if node == nil {
return
}
// 当前节点为叶子节点
if node.left == nil && node.right == nil {
// 被删除的节点为根节点
if parentNode == nil {
sortTree.root = nil
return
}
// 当前节点为父节点的左子节点
if parentNode.left != nil && parentNode.left.no == no {
parentNode.left = nil
}
// 当前节点为父节点的右子节点
if parentNode.right != nil && parentNode.right.no == no {
parentNode.right = nil
}
return
}
// 当前节点有两颗子树
if node.left != nil && node.right != nil {
// 把右子节点作为根节点,从左边开始遍历到最后一个叶子节点
leftChildNode := node.right
for leftChildNode.left != nil {
leftChildNode = leftChildNode.left
}
// 删除最小的叶子节点
sortTree.Delete(leftChildNode.no)
// 替换掉被删除节点的值
node.no = leftChildNode.no
} else { // 当前节点只有一颗子树
var replaceNode *BinaryTreeNode
if node.left != nil {
replaceNode = node.left
} else if node.right != nil {
replaceNode = node.right
}
// 父节点为 nil,表示根节点
if parentNode == nil {
sortTree.root = replaceNode
return
}
// 当前节点为父节点的左子节点
if parentNode.left != nil && parentNode.left.no == no {
parentNode.left = replaceNode
}
// 当前节点为父节点的右子节点
if parentNode.right != nil && parentNode.right.no == no {
parentNode.right = replaceNode
}
}
}测试代码:
func TestBinarySortTree(t *testing.T) {
nos := []int{8, 5, 10, 3, 6, 9, 12, 2}
binarySortTree := NewBinarySortTree()
for _, no := range nos {
binarySortTree.Add(&BinaryTreeNode{no: no})
}
fmt.Println("======中序遍历======")
binarySortTree.InfixOrder()
binarySortTree.Delete(6)
fmt.Println("======删除叶子节点 6======")
binarySortTree.InfixOrder()
binarySortTree.Delete(5)
fmt.Println("======删除只有一颗子树的节点 5======")
binarySortTree.InfixOrder()
binarySortTree.Delete(10)
fmt.Println("======删除有两颗子树的节点 10======")
binarySortTree.InfixOrder()
}运行:
golang/datastructure>go test -v -run ^TestBinarySortTree$ ./tree/binary_sort_tree
=== RUN TestBinarySortTree
======中序遍历======
no:2
no:3
no:5
no:6
no:8
no:9
no:10
no:12
======删除叶子节点 6======
no:2
no:3
no:5
no:8
no:9
no:10
no:12
======删除只有一颗子树的节点 5======
no:2
no:3
no:8
no:9
no:10
no:12
======删除有两颗子树的节点 10======
no:2
no:3
no:8
no:9
no:12在 AVL 树中任何节点的两个子树的高度最大差别为 1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL 树本质上是带了平衡功能的二叉排序树(二叉查找树,二叉搜索树)。
特点:
- 本身是一颗二叉排序树。
- 带有平衡条件,每个节点的左右子树的高度之差的绝对值(平衡因子)最多为 1
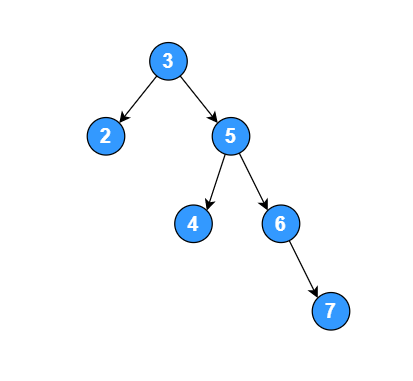
如下是一个颗 AVL 树:
有一个序列,其元素为 [3, 2, 5, 4, 6, 7],将此序列构建成一颗二叉排序树,如下图:
先定义 AVL 树结构体:
// 树节点结构体
type BinaryTreeNode struct {
no int // 编号
left *BinaryTreeNode // 左子节点
right *BinaryTreeNode // 右子节点
}
func (sortTreeNode *BinaryTreeNode) String() string {
return fmt.Sprintf("no:%d", sortTreeNode.no)
}
// AVL 树结构体
type AVLTree struct {
root *BinaryTreeNode // 树的根节点
}
func NewAVLTree() *AVLTree {
return &AVLTree{}
}
// 省略添加节点,中序遍历等方法计算节点树的高度:
// 左子树高度
func (avlTree *AVLTree) leftHeight() int {
if avlTree.root == nil {
return 0
}
return avlTree.height(avlTree.root.left)
}
// 右子树高度
func (avlTree *AVLTree) rightHeight() int {
if avlTree.root == nil {
return 0
}
return avlTree.height(avlTree.root.right)
}
// 计算节点树的高度
func (avlTree *AVLTree) height(node *BinaryTreeNode) int {
if node == nil {
return 0
}
var lHeight, rHeight int
// 递归左子节点
lHeight = avlTree.height(node.left)
// 递归右子节点
rHeight = avlTree.height(node.right)
// 取最大值,1 表示当前节点的高度值
return int(math.Max(float64(lHeight), float64(rHeight))) + 1
}测试代码:
func TestHeight(t *testing.T) {
nos := []int{3, 2, 5, 4, 6, 7}
avlTree := NewAVLTree()
for _, no := range nos {
avlTree.Add(&BinaryTreeNode{no: no})
}
fmt.Printf("左子树的高度为: %d\n", avlTree.leftHeight())
fmt.Printf("右子树的高度为: %d\n", avlTree.rightHeight())
}运行:
golang/datastructure>go test -v -run ^TestHeight$ ./tree/avl_tree
=== RUN TestHeight
左子树的高度为: 1
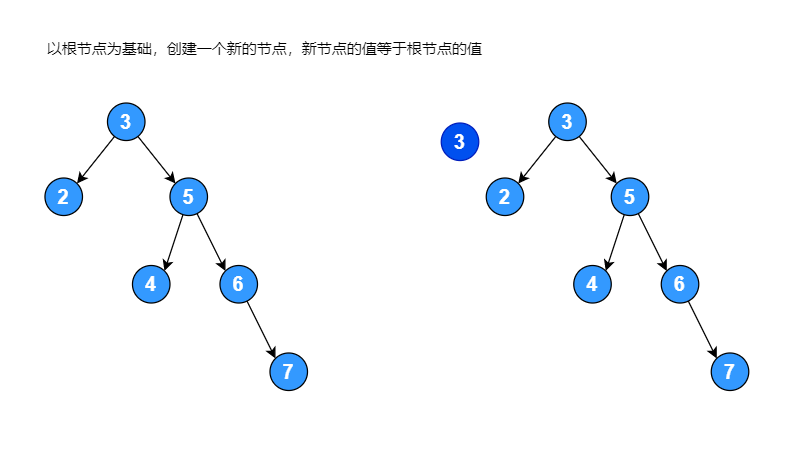
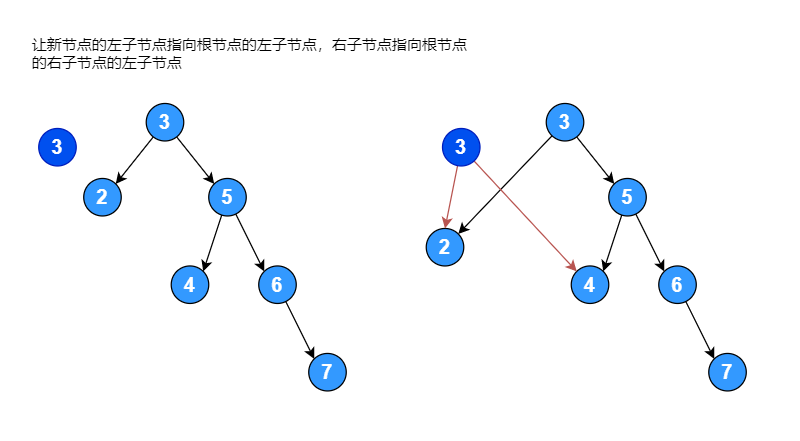
右子树的高度为: 3如果一颗二叉排序树中,右子树的高度减去左子树的高度大于 1,将其进行左旋转使其变成平衡二叉排序树,左旋转过程如下图:
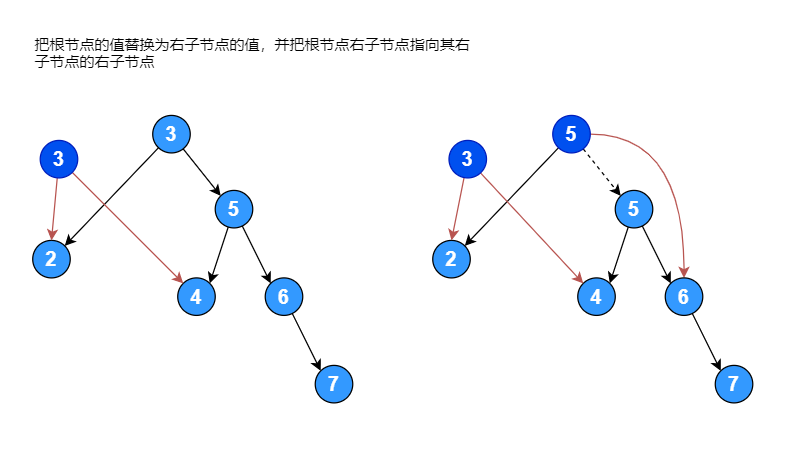
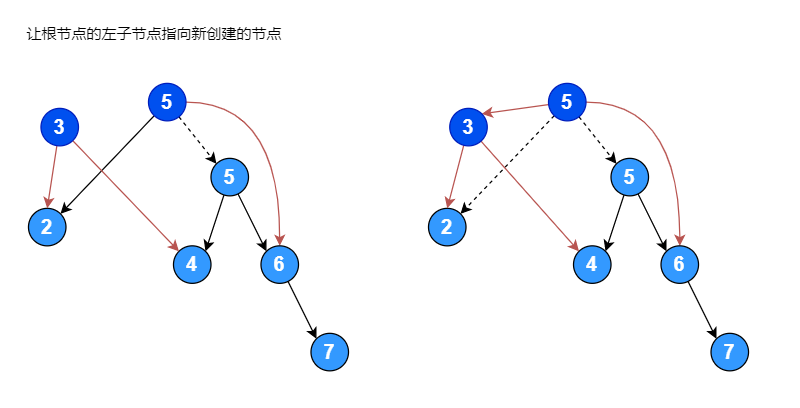
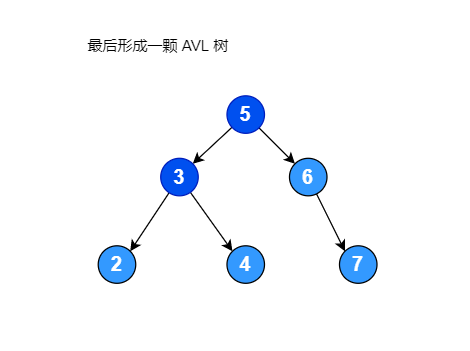
左旋转代码:
// 左旋转
func (avlTree *AVLTree) leftRotate(node *BinaryTreeNode) {
if node == nil {
return
}
// 以当前节点为基础,创建一个新的节点,新节点的值等于当前节点的值
newNode := &BinaryTreeNode{no: node.no}
// 让新节点的左子节点指向当前节点的左子节点,右子节点指向当前节点的右子节点的左子节点
newNode.left = node.left
newNode.right = node.right.left
// 把当前节点的值替换为右子节点的值,并把当前节点右子节点指向其右子节点的右子节点
node.no = node.right.no
node.right = node.right.right
// 让当前节点的左子节点指向新创建的节点
node.left = newNode
}在添加节点后进行旋转:
// 添加节点
func (avlTree *AVLTree) Add(node *BinaryTreeNode) {
if node == nil {
return
}
// 根节点为 nil,要添加的节点作为根节点
if avlTree.root == nil {
avlTree.root = node
return
}
avlTree.add(avlTree.root, node)
// 添加节点后判断是否需要旋转
// 右边高度超过左边 1 个高度以上,进行左旋转
if avlTree.rightHeight() - avlTree.leftHeight() > 1 {
avlTree.leftRotate(avlTree.root)
}
}测试左右子树的高度:
func TestLeftRotate(t *testing.T) {
nos := []int{3, 2, 5, 4, 6, 7}
avlTree := NewAVLTree()
for _, no := range nos {
avlTree.Add(&BinaryTreeNode{no: no})
}
fmt.Println("左旋转后")
avlTree.InfixOrder()
fmt.Printf("根节点 = %v\n", avlTree.root)
fmt.Printf("左子树的高度为: %d\n", avlTree.leftHeight())
fmt.Printf("右子树的高度为: %d\n", avlTree.rightHeight())
}运行:
golang/datastructure>go test -v -run ^TestLeftRotate$ ./tree/avl_tree
=== RUN TestLeftRotate
左旋转后
no:2
no:3
no:4
no:5
no:6
no:7
根节点 = no:5
左子树的高度为: 2
右子树的高度为: 2假设有一个序列 [6, 4, 7, 2, 5, 3], 将其构建成一颗二叉排序树,如果左子树的高度减去右子树的高度大于 1,将其进行右旋转使其变成平衡二叉排序树,右旋转过程如下图:
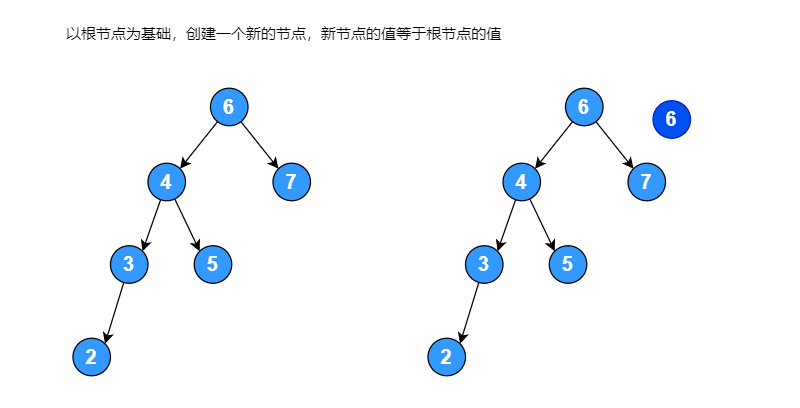
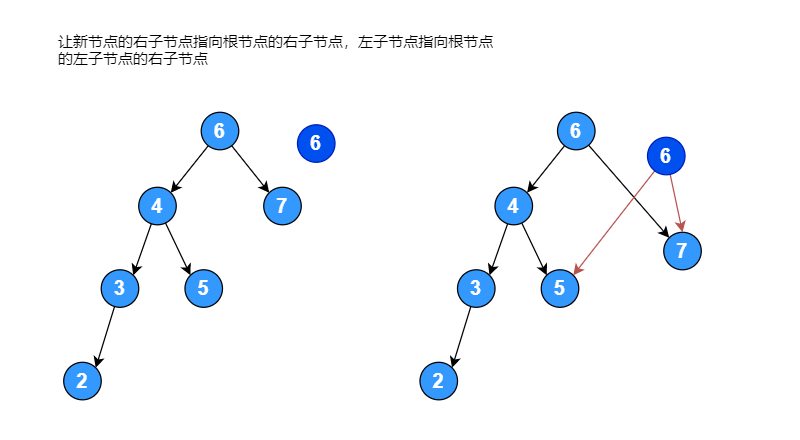
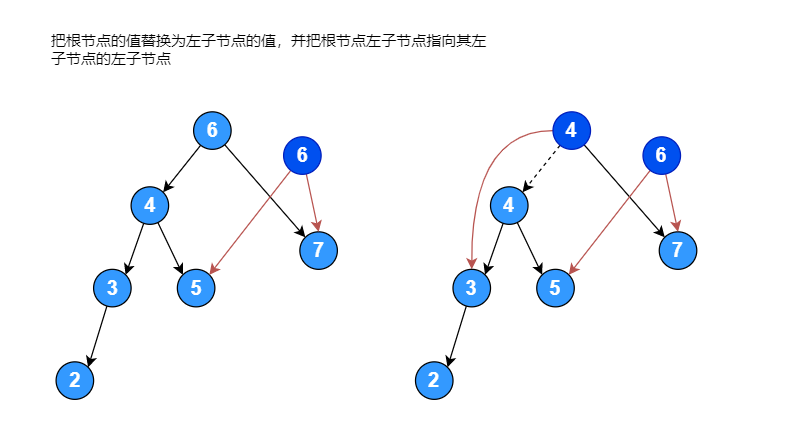
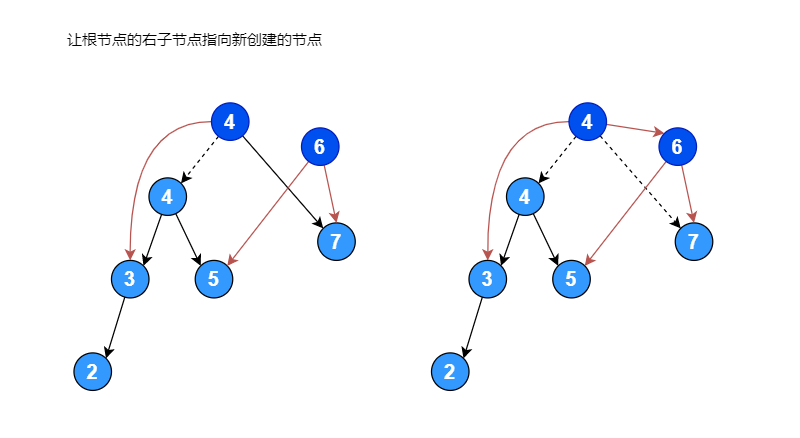
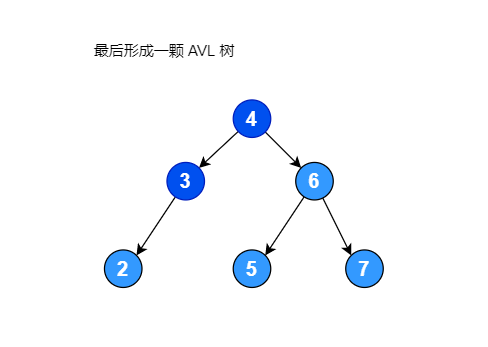
右旋转代码:
// 右旋转
func (avlTree *AVLTree) rightRotate(node *BinaryTreeNode) {
if node == nil {
return
}
// 以当前节点为基础,创建一个新的节点,新节点的值等于根节点的值
newNode := &BinaryTreeNode{no: node.no}
// 让新节点的右子节点指向当前节点的右子节点,左子节点指向当前节点的左子节点的右子节点
newNode.right = node.right
newNode.left = node.left.right
// 把当前节点的值替换为左子节点的值,并把当前节点左子节点指向其左子节点的左子节点
node.no = node.left.no
node.left = node.left.left
// 让当前节点的右子节点指向新创建的节点
node.right = newNode
}在添加节点后进行旋转:
// 添加结点
func (avlTree *AVLTree) Add(node *BinaryTreeNode) {
if node == nil {
return
}
// 根节点为 nil,要添加的节点作为根节点
if avlTree.root == nil {
avlTree.root = node
return
}
avlTree.add(avlTree.root, node)
// 添加节点后判断是否需要旋转
// 左边高度超过右边 1 个高度以上,进行右旋转
if avlTree.leftHeight() - avlTree.rightHeight() > 1 {
avlTree.rightRotate(avlTree.root)
}
}测试左右子树高度:
func TestRightRotate(t *testing.T) {
nos := []int{6, 4, 7, 3, 5, 2}
avlTree := NewAVLTree()
for _, no := range nos {
avlTree.Add(&BinaryTreeNode{no: no})
}
fmt.Println("右旋转后")
avlTree.InfixOrder()
fmt.Printf("根节点 = %v\n", avlTree.root)
fmt.Printf("左子树的高度为: %d\n", avlTree.leftHeight())
fmt.Printf("右子树的高度为: %d\n", avlTree.rightHeight())
}运行:
golang/datastructure>go test -v -run ^TestRightRotate$ ./tree/avl_tree
=== RUN TestRightRotate
右旋转后
no:2
no:3
no:4
no:5
no:6
no:7
根节点 = no:4
左子树的高度为: 2
右子树的高度为: 2有些情况将根节点左旋转或者旋转后,任然不能满足平衡二叉排序树的要求,如下图是一个二叉排序树进行右旋转:
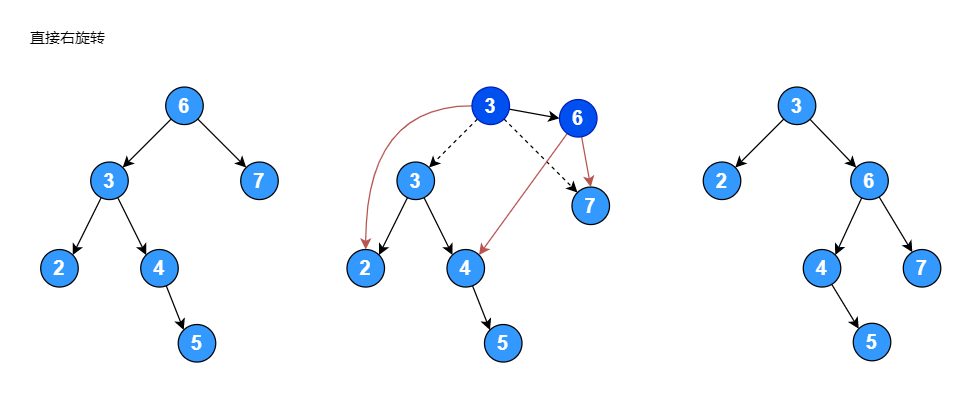
旋转后任然不是一颗 AVL 树,当左子节点的右子树高度大于其左子树高度时,需要将根节点的左子节点进行左旋转,然后再将根节点进行右旋转:
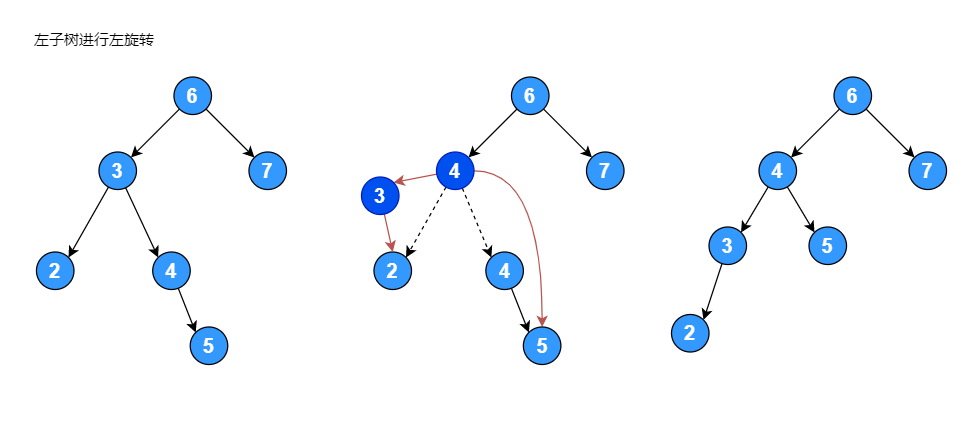
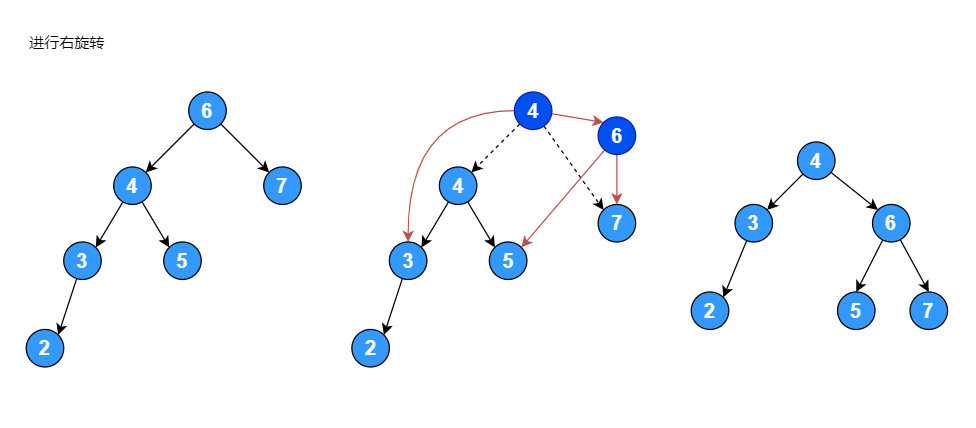
反之,先将根节点的右子树进行右旋转,然后再将根节点进行左旋转。
在添加节点后,判断子树是否需要进行左右旋转,代码如下:
// 添加节点
func (avlTree *AVLTree) Add(node *BinaryTreeNode) {
if node == nil {
return
}
// 根节点为 nil,要添加的节点作为根节点
if avlTree.root == nil {
avlTree.root = node
return
}
avlTree.add(avlTree.root, node)
// 添加节点后判断是否需要旋转
// 右边高度超过左边 1 个高度以上,进行左旋转
if avlTree.rightHeight() - avlTree.leftHeight() > 1 {
rightNode := avlTree.root.right
// 右子节点不为 nil,并且右子节点的左子树高度大于右子节点的右子树高度
if rightNode != nil &&
avlTree.height(rightNode.left) > avlTree.height(rightNode.right) {
// 将右子节点右旋转
avlTree.rightRotate(rightNode)
}
avlTree.leftRotate(avlTree.root)
return
}
// 左边高度超过右边 1 个高度以上,进行右旋转
if avlTree.leftHeight() - avlTree.rightHeight() > 1 {
leftNode := avlTree.root.left
// 左子节点不为 nil, 并且左子节点的右子树高度大于左子节点的左子树高度
if leftNode != nil &&
avlTree.height(leftNode.right) > avlTree.height(leftNode.left) {
// 将左子节点左旋转
avlTree.leftRotate(leftNode)
}
avlTree.rightRotate(avlTree.root)
}
}测试:
func TestDoubleRotate(t *testing.T) {
nos := []int{6, 3, 7, 2, 4, 5}
avlTree := NewAVLTree()
for _, no := range nos {
avlTree.Add(&BinaryTreeNode{no: no})
}
fmt.Println("双旋转后")
avlTree.InfixOrder()
fmt.Printf("根节点 = %v\n", avlTree.root)
fmt.Printf("左子树的高度为: %d\n", avlTree.leftHeight())
fmt.Printf("右子树的高度为: %d\n", avlTree.rightHeight())
}运行:
golang/datastructure>go test -v -run ^TestDoubleRotate$ ./tree/avl_tree
=== RUN TestDoubleRotate
双旋转后
no:2
no:3
no:4
no:5
no:6
no:7
根节点 = no:4
左子树的高度为: 2
右子树的高度为: 2