Home
SRPC is a Workflow-based RPC developed by Sogou. It parses part of IDL (Interface Description File) and generates the code, offering a very simple user interface to integrate with the underlying communication framework of the Workflow.
SRPC has around 10,000 code lines. It uses a variety of generic programming methods and achieves vertical decoupling and horizontal scalability. Its architecture is exquisite and beautiful, growing from the same core codes. This article explains the design considerations behind the architecture.
I. Overview
II. Interface description, protocol and communication layer
- Interface description file layer
- RPC protocol layer
- Network communication layer
- Protocol + network communication
III. Overview of the architecture structure
IV. Code generation
- Original IDL interface
- srpc code generation interface
- Network protocols within srpc
- Many-to-many relationship between services and servers
V. Synchronous, asynchronous, semi-synchronous interface, and integration with the task flow in the Workflow
- Asynchronous interface
- Synchronous interface
- Semi-synchronous interface
- Task interface
- How to use Context to open a task flow and start an asynchronous server
VI. Other features in the Workflow
VII. Final remark
As an RPC, SRPC clearly positions itself as the framework that achieves vertical disassembly and horizontal decoupling at multiple levels. It consists of the following layers:
- User code (implementation of the functions for clients’/servers’ features)
- IDL serialization (protobuf/thrift serialization)
- Data organization (protobuf/thrift/json)
- Compression (none/gzip/zlib/snappy/lz4)
- Protocol (Sogou-std/Baidu-std/Thrift-framed/TRPC)
- Communication (TCP/HTTP)
The above layers can be assembled with each other, and high level of code reuse are achieved internally through multiple polymorphic methods such as overloading and subclass derivation to implement the interfaces of the parent classes or template specialization. If you want to upgrade the architecture in the future, it is very convenient to add one layer in the middle or add some features horizontally within a certain layer. The overall design is relatively ingenious.
Thanks to the performance of the Workflow, the performance of SRPC itself is also excellent. In addition to Sogou-std protocol, SRPC also implements Baidu-std protocol, Thrift-framed protocol and Tencent’s TRPC protocol. Under the same protocol, srpc has a leading throughput performance over brpc and apache thrift, and its long tail performance is on par with brpc but stronger than thrift.
srpc has been used stably for some time within Sogou and other developers after it became open-source. With its simple interface, you can not only gain fast development, but also boost your business performance by several times.
This article mainly explains the design considerations of SRPC architecture. Please read it together with the readme and other documents on the homepage.
Generally, when you use an RPC, you should pay attention to:method, request, response. The passages below explains how to use them in srpc.
The above passages briefs several layers. As an srpc developer, you should understand the following three layers:
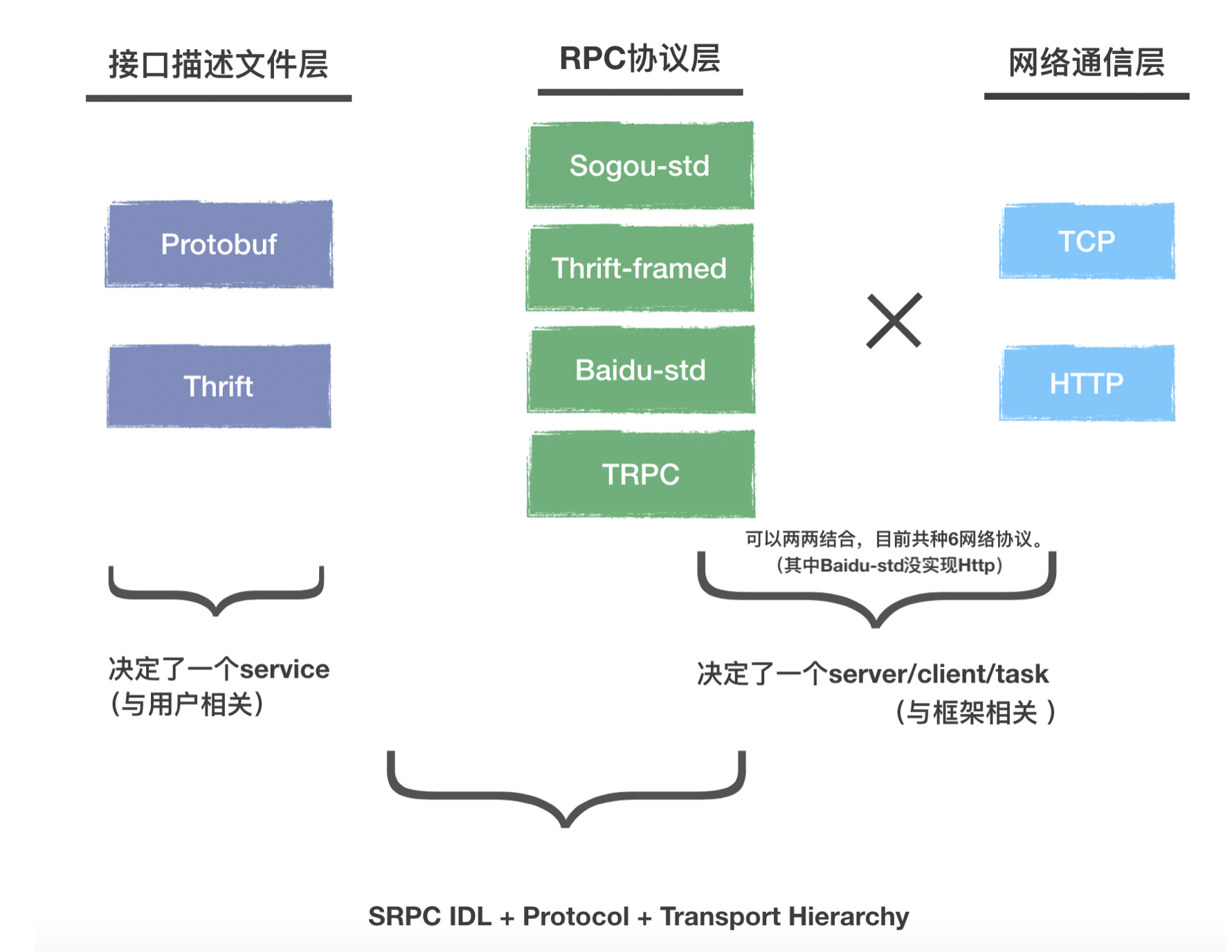
From the left to the right, the figure shows the layers where you may use, order by their frequencies from the most to the least. If you have used some RPCs, you usually choose an existing IDL. Currently protobuf and thrift are used widely, and both are supported by srpc. For the two IDLs:
- Thrift:IDL is parsed by yourself. When you use srpc, please DO NOT link to the library of thrift!
- Protobuf: the definition of its service is parsed by yourself
In your development, if you request a method, you populate the request with the data defined by one IDL, and receive the response defined by the same IDL.
One IDL determines one service.
The middle column indicates the specific protocol. sprc has implemented Sogou-std, Baidu-std, Thrift-framed and TRPC. The protocol of Sogou-std is as follows:
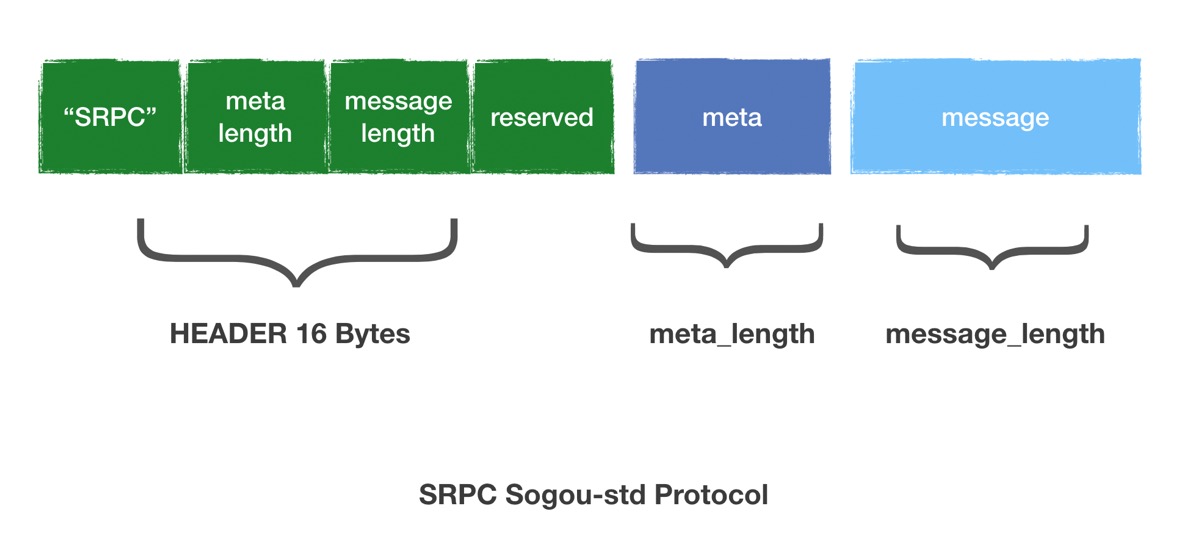
The service name, method name and other information of the RPC will be populated in the meta. The third part is the complete IDL for the user: the detailed content in the request/response
The above content, if it is sent out directly via TCP in binary, must be parsed by the server/client using the same protocol. However, if you want it language-neutral, the simplest way is to use the HTTP protocol. Therefore, the third column in the network communication, alongside TCP binary content, is HTTP.
In theory, each of the items in the second column and each of the items in the third column can be combined together. When you send a message with a specific RPC protocol in the second column, you should specify the HTTP-related content. Instead of sending it in its own protocol, send it in HTTP. What is required in HTTP? URL, header and body.
Append the service/method to the host in URL, and then put the content in the meta of the specific protocol one by one in the header of HTTP by the header key recognizable by HTTP. Finally, put the detailed request/response into the body of the HTTP and send it out.
Except HTTP+Baidu-std/TRPC, we have implemented six network communication protocols via such combination:
- SRPCStd
- SRPCHttp
- BRPCStd
- TRPC
- ThriftBinaryFramed
- ThriftBinaryHttp
In order to be more compatible with HTTP users, apart from protobuf/thrift, our body also support json. In other words, the client can use any language. If you send an HTTP request in JSON to the server, the server still receives an IDL structure.
One network communication protocol determines one type of server/client/task.
Let's take a look at the process on how to send out the request through the method and handle the received response:
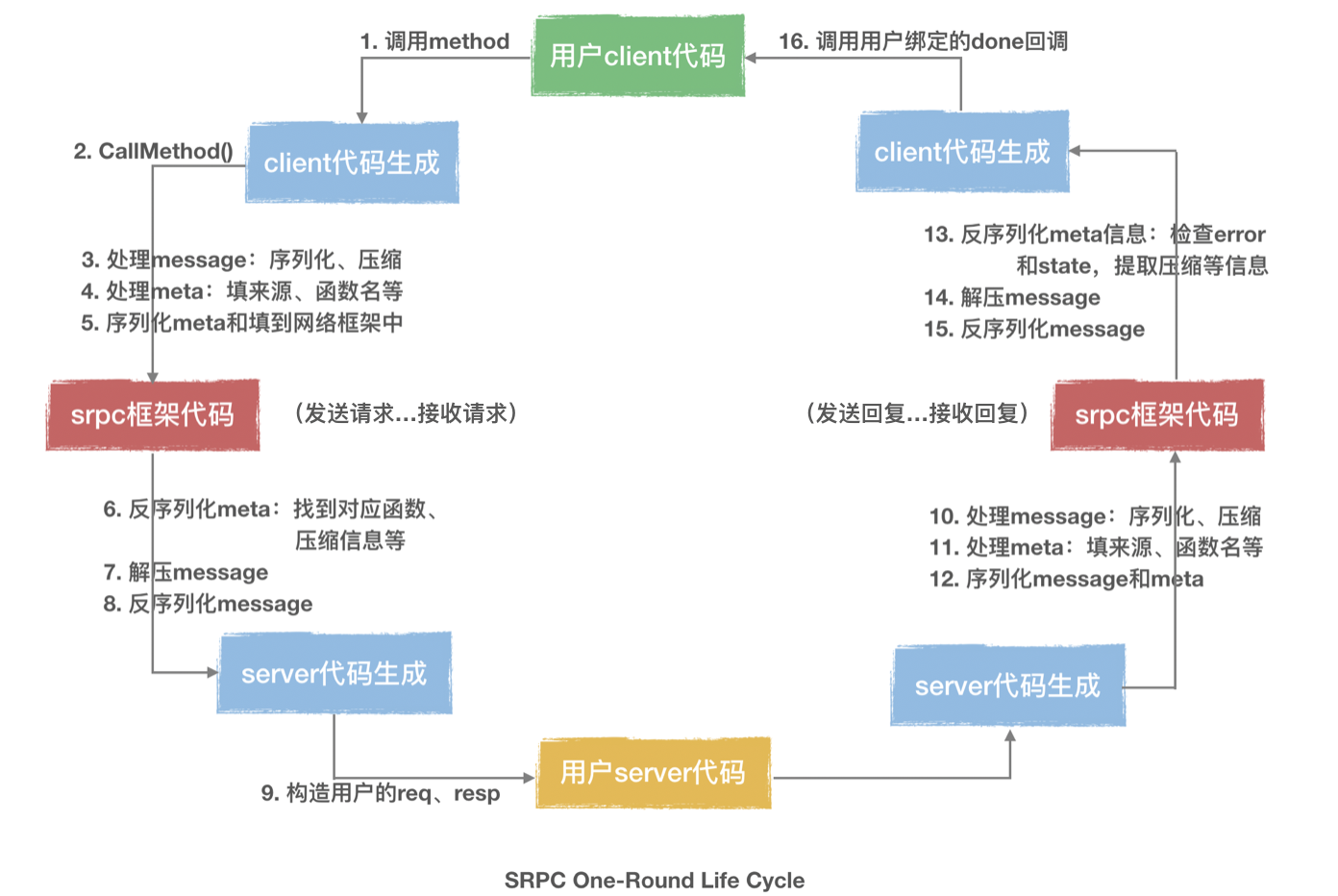
In the above figure,
you can clearly see the various layers mentioned at the beginning of the article, in which the compression layer, serialization layer and protocol layer are decoupled from each other, and the code implementation is very uniform. When you add any compression algorithm or IDL or protocol horizontally, it is not necessary to change the existing code.
The principle behind the architecture design of srpc can be basically summarized as: constant decoupling.
In addition, as a communication framework, srpc has designed modular plug-ins for each layer in order to support the call of external services and extensible control logic. Expanding the process from receiving a message to sending a reply by a server, the modular plug-in architecture is shown as follows:
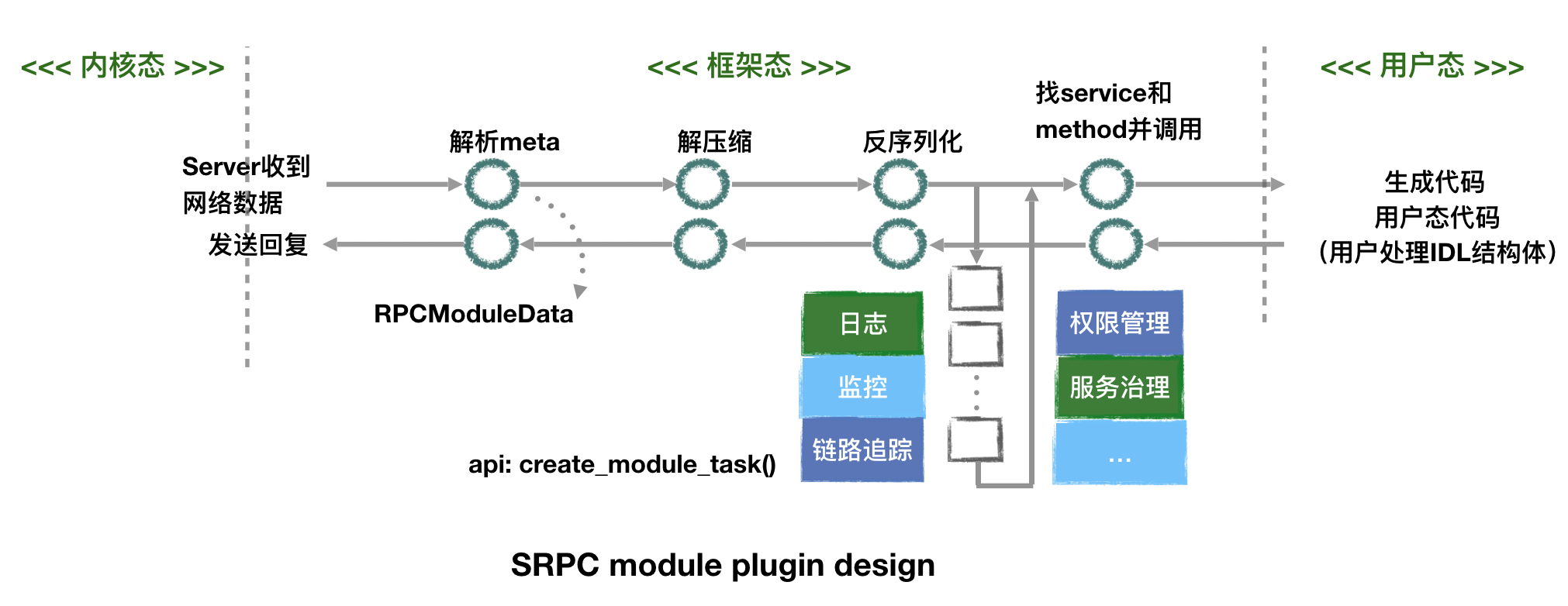
If you want to use a plug-in, you need to register it in advance, so as to ensure that no overhead is introduced by unused modules. The internal implementation of each module encapsulates the specific execution mode into a task, which follows the programming paradigm of the internal task flow in the Workflow.
You can see that many steps are completed by code generation in the above figure. Because users want to customize their IDL structure, an RPC framework must consider how to reflect a piece of memory received on the network according to the structure definition, and provide the interface with the custom structure as parameters. All these only requires to generate some codes for C++. Theoritically, if you rely on protobuf and thrift, you can really avoid manual code generation.
Now let’s see why we need code generation.
For the service definition in protobuf, or all the contents in thrift, we have used code generation. Take protobuf as an example:
message EchoRequest
{
optional string message = 1;
};
message EchoResponse
{
optional string message = 1;
};
service ExamplePB
{
rpc Echo(EchoRequest) returns (EchoResponse);
};Actually, for pb, you need only to match it with:
option cc_generic_services = true;Then it can generate the interface of the specific service/method, but protobuf itself does not have network communication function. You need to develop it based on this interface. The native interface of pb is very complicated:
// SERVER
class ExamplePB : public ::PROTOBUF_NAMESPACE_ID::Service {
public:
// It is an interface. You should derive this class and override the function. Then put the businesss logic of the server in that function.
virtual void Echo(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done);
};
// CLIENT
class ExamplePB_Stub : public ExamplePB {
public:
// For RPC invocation, you still need the controller and Closure done
void Echo(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done);
};Google likes to separate the interface layer from the implementation layer. If you want to use protobuf's default code, you need to write controller and closure. Both of them can be implemented. Generally, RPC that supports protobuf does the same thing. However, it will be a headache for users to see so many complicated things. In particular, controller is not in line with the aesthetics of architecture as it requries users to learn one more structure with client.
On the other hand, the life cycle of response and controller is also very confusing. pb is an interface that requires you to pass the life cycle, and you should ensure that the life cycle must be kept until the end of asynchronous request, which is obviously not friendly.
For thrift, the combination of the request and the connection itself is too tight, which is not friendly for you to implement your own network communication layer.
In order to support two different IDL requests to Workflow, we use code generation, including basic generator->parser->printer. The code style is similar to C. The IDL file needs to be compiled first. Then you can call them as follows:
srpc_generator [protobuf|thrift] [proto_file|thrift_file] out_dirThe specific file is generated in xxx.srpc.h. Take the previous protobuf as example. The code generated by srpc is as follows:
// SERVER
class Service : public srpc::RPCService
{
public:
// You should derive and implement this function. It correponds to the code generated for pb.
virtual void Echo(EchoRequest *request, EchoResponse *response,
srpc::RPCContext *ctx) = 0;
};
// CLIENT
using EchoDone = std::function<void (EchoResponse *, srpc::RPCContext *)>;
class SRPCClient : public srpc::SRPCClient
{
public:
void Echo(const EchoRequest *req, EchoDone done);
};The interface will be very simple to use, especially the client interface, where done is our callback function, and you can ignore the session context information like controller if you do not want to use it.
srpc also support to generate a skeleton, like thrift: server.xx_skeleton.cc and client.xx_skeleton.cc includes the client, the server and the service derivation in the main function, and you do not need to worry about the steps.
//server.pb_skeleton.cc. The code below is generated automatically.
#include "xxxx.srpc.h"
class ExamplePBServiceImpl : public ::example::ExamplePB::Service
{
public:
void Echo(::example::EchoRequest *request, ::example::EchoResponse *response,
srpc::RPCContext *ctx) override
{ /* The business logic after receiving the request. Populate the response here. */ }
};
int main()
{
// 1. Define a server
SRPCServer server;
// 2. Define a service and put it into the server
ExamplePBServiceImpl examplepb_impl;
server.add_service(&examplepb_impl);
// 3. Start the server
server.start(PORT);
pause();
server.stop();
return 0;
}Now let’s see the integration between communication layer and protocol layer. Let's continue to read xxxx.srpc.h, which defines several protocols:
// Code generated by protobuf
class Service : public srpc::RPCService;
class SRPCClient : public srpc::SRPCClient;
class SRPCHttpClient : public srpc::SRPCHttpClient;
class BRPCClient : public srpc::BRPCClient;
class TRPCClient : public srpc::TRPCClient;If the IDL is thrift, the generated xxxx.srpc.h will have these items:
// Code generated by thrift
class Service : public srpc::RPCService;
class SRPCClient : public srpc::SRPCClient;
class SRPCHttpClient : public srpc::SRPCHttpClient;
class ThriftClient : public srpc::ThriftClient;
class ThriftHttpClient : public srpc::ThriftHttpClient;You can see that each has only one service, because service is only related to IDL.
Then, for different RPC protocols (SRPC/BRPC/Thrift/TRPC), if there is a matching communication protocol (TCP/HTTP), there will be a corresponding client.
We learned that one IDL defines one service, and one network communication protocol defines one server. And the layers inside srpc can be combined with each other, which means:
- Multiple services can be added to the server of one protocol (This is not new. Most rps support that)
- You can implement one service function, which can be added to multiple servers for different protocols and all are runnable;
- The function of a service can support both TCP and HTTP services, and it is very convenient to reuse the business logic.
int main()
{
SRPCServer server_srpc;
SRPCHttpServer server_srpc_http;
BRPCServer server_brpc;
TRPCServer server_trpc;
ThriftServer server_thrift;
ExampleServiceImpl impl_pb; // use pb as the interface service
AnotherThriftServiceImpl impl_thrift; // use thrift as the interface service
server_srpc.add_service(&impl_pb); // you can add the service if the protocol supports its IDL
server_srpc.add_service(&impl_thrift);
server_srpc_http.add_service(&impl_pb); // srpc supports both TCP and HTTP services
server_srpc_http.add_service(&impl_thrift);
server_brpc.add_service(&impl_pb); // for baidu-std, support protobuf only
server_trpc.add_service(&impl_pb); // change one character and be compatible with another protocol
server_thrift.add_service(&impl_thrift); // for thrift-binary, support thrift only
server_srpc.start(1412);
server_srpc_http.start(8811);
server_brpc.start(2020);
server_trpc.start(2021);
server_thrift.start(9090);
....
return 0;
}srpc provides synchronous, semi-synchronous and asynchronous interfaces, among which asynchronous interface is the key to integrate with the task flow in the Workflow.
If you continue to read the generated code, taking one client as an example, all interfaces of the client defined by a specific protocol are as follows:
class SRPCClient : public srpc::SRPCClient
{
public:
// asynchronous interface
void Echo(const EchoRequest *req, EchoDone done);
// synchronous interface
void Echo(const EchoRequest *req, EchoResponse *resp, srpc::RPCSyncContext *sync_ctx);
// semi-synchronous interface
WFFuture<std::pair<EchoResponse, srpc::RPCSyncContext>> async_Echo(const EchoRequest *req);
public:
SRPCClient(const char *host, unsigned short port);
SRPCClient(const struct srpc::RPCClientParams *params);
public:
// Asynchonous interface. Use it in the same way as other tasks in the Workflow
srpc::SRPCClientTask *create_Echo_task(EchoDone done);
};These interfaces use request, response, context and done in a variety of ways:
Asynchronous interface is easy to understand, and you don't need to pass the pointer of response when making requests, and you don't need to guarantee the life cycle of them. The above passages show the callback function done, which is a std::function, and the framework will create a response in the generated code that calls done. The example in skeleton code is as follows:
static void echo_done(::example::EchoResponse *response, srpc::RPCContext *context)
{
// Use this RPCContext to get the status provided by the framework during the request
}Synchronous interface has no life cycle problem, so you can operate response and context directly.
Semi-synchronous interface will return a future, which is a WFFutureencapsulated within Workflow. Its usage is similar to std::future. When you need to wait, you can get the result through the get() interface, and the result is response and context.
Actually, asynchronous interface is also implemented internally through the task interface. The following code demonstrate the way we create a task through a client:
srpc::SRPCClientTask * task = SRPCClient::create_Echo_task(done);
task->serialize_input(req);
task->start();This way fully embodies the secondary factory concept of the Workflow. srpc involves a few specific protocols and some extra functions(such as serialization and compression of user IDL). The implementation of a protocol with complex functions in the Workflow is actually the implementation of a secondary factory.
After getting task, you need to populate the request and start it. This is exactly the same as the task in the Workflow.
The most important thing of this interface is: rpc created by the secondary factory in the client can be put into any task flow graph in the Workflow, and automatically run during the execution of the flow graph.
You can get RPCContext in two places:
- The parameters of the function implementation of the service in the server
- The parameters of
donein the client
This RPCContext supports a lot of features, which are mainly of the following three types:
- providing interfaces for some session-level (or task-level) information for the current response on the server, such as compression types;
- checking the status and other information of the request when the client gets the reply;
- retrieving the series;
Take the interface of series as follows:
SeriesWork *get_series() const;In the implementation of the functions for a server, you can append other task to this series to realize an asynchronous server (the sever will reply after all tasks in the series are finished), or you can continue to append other Workflow tasks to the task flow in the callback function of the client. This should be the simplest asynchronous server implementation among all existing RPCs.
To build an asynchronous server, take the previous service as an example:
class ExampleServiceImpl : public Example::Service
{
public:
void Echo(EchoRequest *request, EchoResponse *response, RPCContext *ctx) override
{
auto *task = WFTaskFactory::create_timer_task(10, nullptr);
ctx->get_series()->push_back(task); // The RPC replies after the task is finished, which is the same as other tasks in the Workflow
}
};As you can see in the above passages, srpc successfully integrates with the Workflow, and the rpc request is divided according to the task concept of the Workflow: protocol, request and response.
So what other features can we borrow from the Workflow?
Service governance. The upstream in the Workflow manages a batch of machines as the upstream under the same domain name in the process, which provides various mechanisms such as load balancing and fuse recovery. srpc clients can use them directly. A client created in srpc may correspond to an IP or a cluster with local service governance.
Configurations at Client and task levels. For example, various timeouts in the Workflow can be used. The network request in the Workflow itself has retry times, and the default value in rpc is 0. You can configure it if necessary.
Other system resources. rpc is only related to the network, while the Workflow contains the resources such as computation and asynchronous file IO, which can be used by srpc after the integration with the task flow.
With the evolution of srpc architecture, several generic programming methods are used, which are listed as follows:
 Some details in architecture design, such as the management of discrete memory, memory reflection, and the specific practices of modular plug-ins, are not included in this wiki for the time being. Currently, we have made some expansion and research on the service level for the srpc project, and we are learning from related projects. From the favorable feedbacks of users and their implementation, we are very confident to promote the Workflow and srpc. We will work with you to learn and make progresses together.
Some details in architecture design, such as the management of discrete memory, memory reflection, and the specific practices of modular plug-ins, are not included in this wiki for the time being. Currently, we have made some expansion and research on the service level for the srpc project, and we are learning from related projects. From the favorable feedbacks of users and their implementation, we are very confident to promote the Workflow and srpc. We will work with you to learn and make progresses together.