This repo provides the PyTorch source code of our paper: Self-correcting LLM-controlled Diffusion Models (CVPR 2024). Check out project page here!
Authors: Tsung-Han Wu*, Long Lian*, Joseph E. Gonzalez, Boyi Li†, Trevor Darrell† at UC Berkeley.
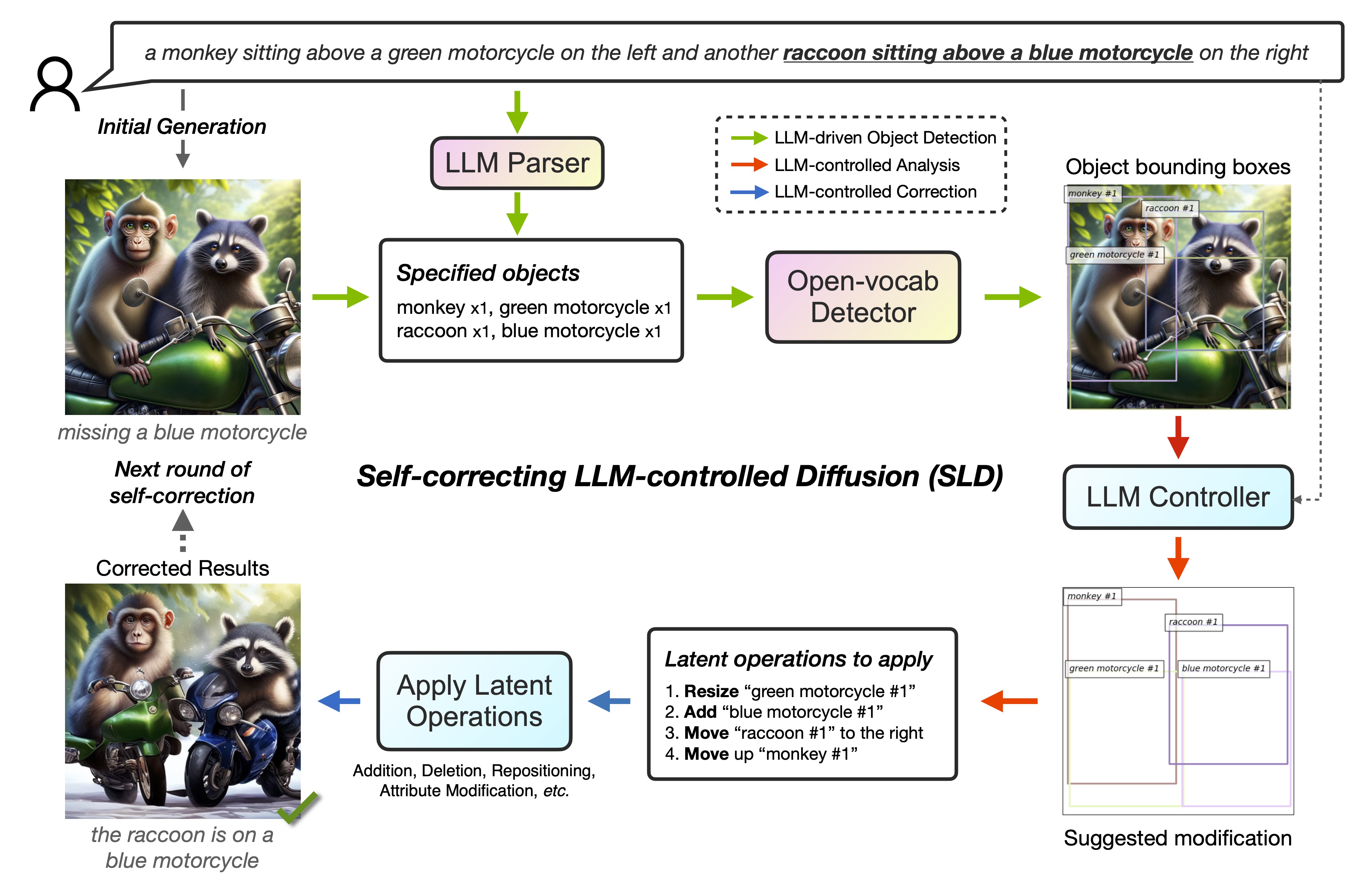
- Self-correction: Enhances generative models with LLM-integrated detectors for precise text-to-image alignment.
- Unified Generation and Editing: Excels at both image generation and fine-grained editing.
- Universal Compatibility: Works with ANY image generator, like DALL-E 3, requiring no extra training or data.
- 03/10/2024 - Add the all SLD scripts and results on the LMD T2I benchmark (all done!)
- 02/13/2024 - Add self-correction and image editing scripts with a few demo examples
-
System Setup: Linux with a single A100 GPU (GPUs with more than 24 GB RAM are also compatible). For Mac or Windows, minor adjustments may be necessary.
-
Dependency Installation: Create a Python environment named "SLD" and install necessary dependencies:
conda create -n SLD python=3.9
pip3 install -r requirements.txt Note: Ensure the versions of transformers and diffusers match the requirements. Versions of transformers before 4.35 do not include owlv2, and our code is incompatible with some newer versions of diffusers with different API.
Execute the following command to process images from an input directory according to the instruction in the JSON file and save the transformed images to an output directory.
CUDA_VISIBLE_DEVICES=X python3 SLD_demo.py \
--json-file demo/self_correction/data.json \ # demo/image_editing/data.json
--input-dir demo/self_correction/src_image \ # demo/image_editing/src_image
--output-dir demo/self_correction/results \ # demo/image_editing/results
--mode self_correction \ # image_editing
--config demo_config.ini
- This script supports both self-correction and image editing modes. Adjust the paths and --mode flag as needed.
- We use
gligen/diffusers-generation-text-box(SDv1.4) as the base diffusion model for image manipulation. For enhanced image quality, we incorporate SDXL refinement techniques similar to LMD.
- Prepare a JSON File: Structure the file as follows, providing necessary information for each image you wish to process:
[
{
"input_fname": "<input file name without .png extension>",
"output_dir": "<output directory>",
"prompt": "<editing instructions or text-to-image prompt>",
"generator": "<optional; setting this for hyper-parameters selection>",
"llm_parsed_prompt": null, // Leave blank for automatic generation
"llm_layout_suggestions": null // Leave blank for automatic suggestions
}
]
Ensure you replace placeholder text with actual values for each parameter. The llm_parsed_prompt and llm_layout_suggestions are optional and can be left as null for LLM automatic generation.
- Setting the config
- Duplicate the config/demo_config.ini file to a preferred location.
- Update this copied config file with your OpenAI API key and organization details, along with any other necessary hyper-parameter adjustments.
- For security reasons, avoid uploading your secret key to public repositories or online platforms.
- Execute the Script: Run the script similarly to the provided demo, adjusting the command line arguments as needed for your specific configuration and the JSON file you've prepared.
In our research, we've shown the superior performance of SLD across four key tasks: negation, numeracy, attribute binding, and spatial relationship. Utilizing the LMD 400 prompts T2I generation benchmark, and employing the state-of-the-art OWLv2 detector with a fixed detection threshold, we've ensured a fair comparison between different methods. Below, we provide both the code and the necessary data for full reproducibility.
The image generation process, including both the initial and resulting images, has been documented to ensure transparency and ease of further research:
| Method | Negation | Numeracy | Attribution | Spatial | Overall |
|---|---|---|---|---|---|
| DALL-E 3 | 27 | 37 | 74 | 71 | 52.3% |
| DALL-E 3 w/ SLD | 84 | 58 | 80 | 85 | 76.8% (+24.5) |
| LMD+ | 100 | 80 | 49 | 88 | 79.3% |
| LMD+ w/ SLD | 100 | 94 | 65 | 97 | 89.0% (+9.7) |
For access to the data and to generate these performance metrics or to reproduce the correction process yourself, please refer to the above table. The structure of the dataset is as follows:
dalle3_sld
├── 000 # LMD benchmark prompt ID
│ ├── chatgpt_data.json # raw GPT-4 response
│ ├── det_result1.jpg # visualization of bboxes
│ ├── initial_image.jpg # initial generation results
│ ├── log.txt # loggging
│ └── round1.jpg # round[X] SLD correction rsults
├── 001
│ ├── chatgpt_data.json
│ ├── det_result1.jpg
...
To generate these performance metrics on your own, execute the following command:
python3 lmd_benchmark_eval.py --data_dir [GENERATION_DIR] [--optional-args]
To replicate our image correction process, follow these steps:
- Setting the config
- Duplicate the config/benchmark_config.ini file to a preferred location.
- Update this copied config file with your OpenAI API key and organization details, along with any other necessary hyper-parameter adjustments.
- For security reasons, avoid uploading your secret key to public repositories or online platforms.
-
Execute the SLD Correction Script
To apply the SLD correction and perform the evaluation, run the following command:
python3 SLD_benchmark.py --data_dir [OUTPUT_DIR]Executing this command will overwrite all existing log files and generated images within the specified directory. Ensure you have backups or are working on copies of data that you can afford to lose.
Also, if you wanna correct other diffusion models, feel free to put the data into the similar structure and then run our code!
-
Why are the results for my own image not optimal?
The SLD framework, while training-free and effective for achieving text-to-image alignment—particularly with numeracy, spatial relationships, and attribute binding—may not consistently deliver optimal visual quality. Tailoring hyper-parameters to your specific image can enhance outcomes.
-
Why do the images generated differ from those in the paper?
In our demonstrations, we use consistent random seeds and hyper-parameters for simplicity, differing from the iterative optimization process in our paper figure. For optimal results, we recommend fine-tuning critical hyper-parameters, such as the dilation parameter in the SAM refinement process or parameters in DiffEdit, tailored to your specific use case.
-
Isn't using SDXL for improved visualization results unfair?
For quantitative comparisons with baselines in our paper (Table 1), we explicitly exclude the SDXL refinement step to maintain fairness. Also, we set the same hyper-parameters across all models in quantitative evaluation
-
Can other LLMs replace GPT-4 in your process?
Yes, other LLMs may be used as alternatives. Our tests with GPT-3.5-turbo indicate only minor performance drops. We encourage exploration with other robust open-source tools like FastChat.
-
Have more questions or encountered any bugs?
Please use the GitHub issues section for bug reports. For further inquiries, contact Tsung-Han (Patrick) Wu at [email protected].
We are grateful for the foundational code provided by Diffusers and LMD. Utilizing their resources implies agreement to their respective licenses. Our project benefits greatly from these contributions, and we acknowledge their significant impact on our work.
If you use our work or our implementation in this repo, or find them helpful, please consider giving a citation.
@article{wu2023self,
title={Self-correcting LLM-controlled Diffusion Models},
author={Wu, Tsung-Han and Lian, Long and Gonzalez, Joseph E and Li, Boyi and Darrell, Trevor},
journal={arXiv preprint arXiv:2311.16090},
year={2023}
}