Mapping RDF to PG using SPARQL
Contrary to other tools (such as neo semantics, rdf2pg allows for custom mapping from RDF patterns (eg, based on the OWL or RDF-S ontologies), to a proerty graph model. The concept is shown in the figure below, adapted from our SWAT4LS 18 paper.
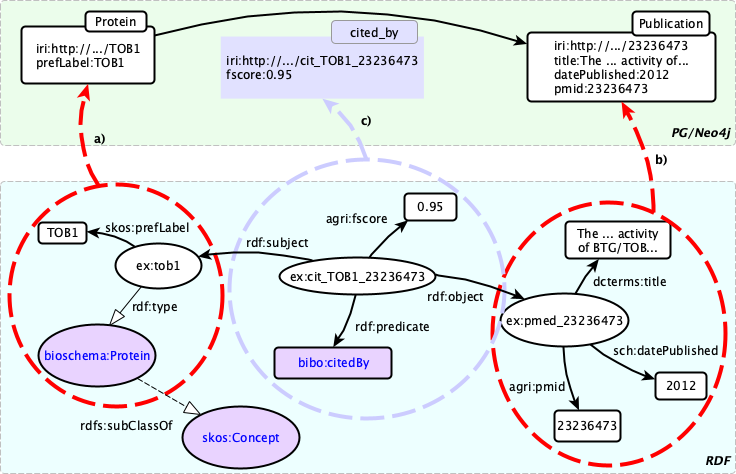
As you can see, "canonical" mappings (eg, an RDF resource becomes a PG node, its rdf:type is used to build the node's label) can be mixed with adaptations to your own particular RDF model (eg, our agri: vocabulary, your own reification vocabulary used as an alternative to rdf:Statement and associated properties).
Those mapping rules can be defined with nothing but SPARQL, as the next figure shows:

Essentially, several SPARQL queries provide the rdf2pg engine with the data that correspond to the desired nodes and relations, as well as node and relation details, that is, the node's labels (ie, types), the relation types, and the node and relation properties.
Several queries are provided as logical pairs, eg, for the nodes, you have to first list all the RDF resource URIs that correspond to entities you want to represent as nodes on the PG side, and then the engine will call 'detail queries' for each of the found URIs, passing the URI to the query. For example, the first (top/left) query in the figure, selects all the (transitive) instances of skos:Concept, then, each concept's URI is sent to the third query in the figure (2nd row, first column), which extracts all the labels of a node, by simply checking which rdf:type statements it is subject of (a ?label is a SPARQL/Turtle shorthand for rdf:type ?label). rdf:type is a typical correspondant of PG node label, more sophysticated cases might be property paths like rdf:type/rdfs:label (ie, the RDF label of the instantiated class, also notes that, when a URI is given as a PG label, its last fragment is extracted by default, see details here).
Similarly, the second query in the figure (first row, second column) gets relevant name/value pairs associated to a node's URI, by listing known RDF properties (eg, dcterms:title) and properties that are (transitively) subproperties of the known root schema:Property. Both patterns in the query correspond to common ways node properties are encoded in RDF.
Finally, relations work similarly, with the difference that rdf2pg requires (for efficiency reasons) that you first list tuples of relation's URI + endpoints + relation type, and then, the relation properties.
The reason for using the split of identifiers first and details afterwards depends on the fact that this is an efficient way for rdf2pg to work: it first fetches the entity's identifiers quickly, then it works on each entity/URI in parallel, using the detail queries.
Note: in examples and code, you will often read IRI in place of URIs, to reflect the fact that the latter are a more general form of universal identifiers. For practical purposes, hereby you can consider the two concepts almost interchangeable.
General details about mapping can be found here.