rdf2pg Architecture
The figure below shows how rdf2pg is organised.
As discussed elsewhere, the framework is based on the idea of extracting PG elements from RDF by means of SPARQL queries. This is done by node processors and relation processors, which run the identifier queries (eg, node's IRIs extractions). A processor collects tuples from the query, groups them in batches and passes each batch to a parallel handler.
The handler usually runs the detail-extraction query (eg, it gets all the properties of a node) and finally uses all the obtained RDF data to 'make' the corresponding PG entity, eg, it issues a CREATE Cypher command against a Neo4j server, or it writes a graphml fragment to describe the node. We use the 'make' verb here in the attemp to capture general processes, which range from writing to a file to sending data language commands to a database, or even writing a different flavour of RDF.
The SPARQL queries rely on a Jena/TDB database, which must be populated from the input RDF files as a first step of the conversion, which is common to any specific rdf2pg target. We use TDB because it gives performance and practical advantages with respect to a remote SPARQL endpoint.
For instance, we don't need to paginate the queries (ie, LIMIT/OFFSET), which is often a performance bottleneck in SPARQL. We plan to support generic endpoints for this conversion step in future, and possibly to experiment with the HDT format.
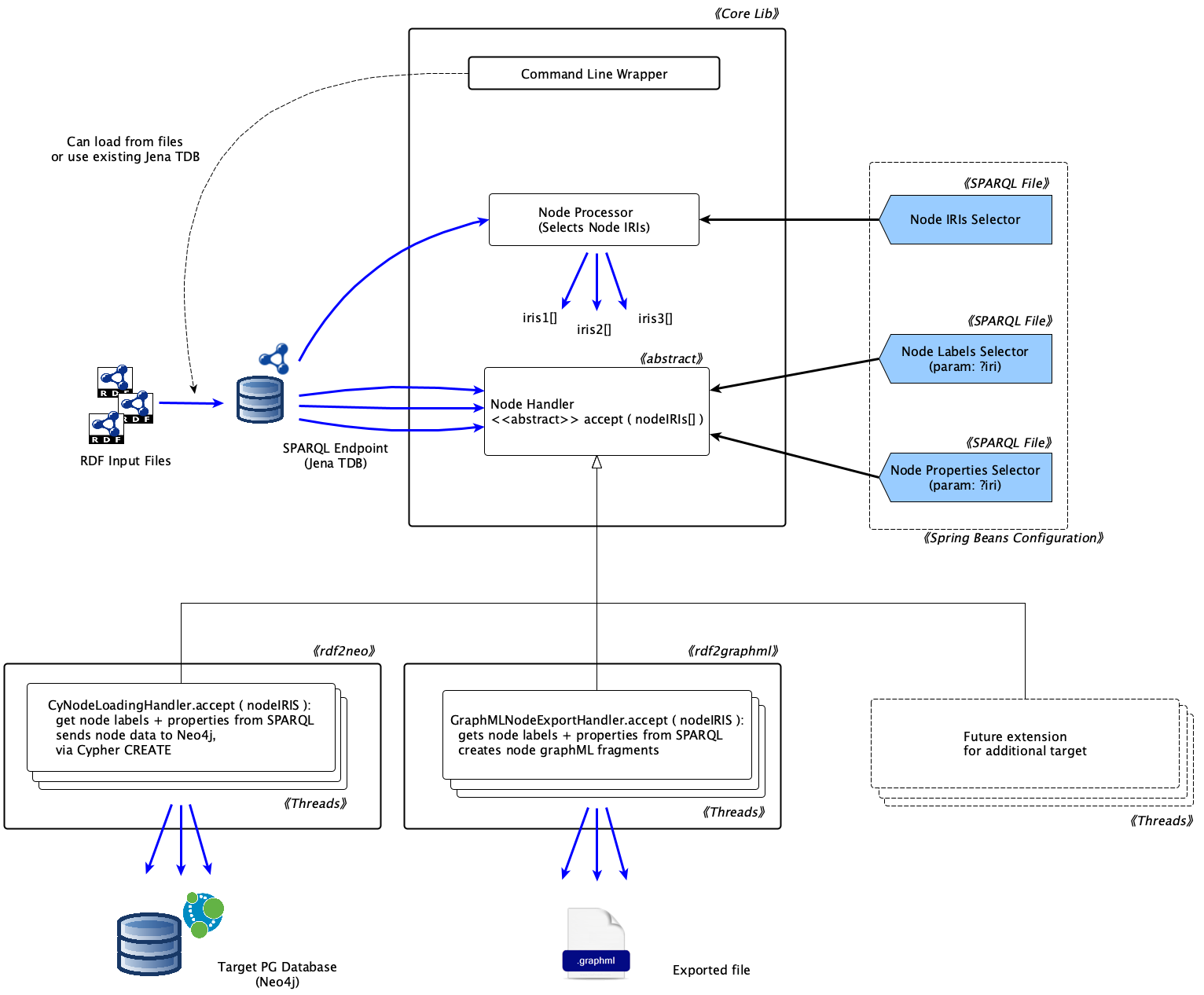
TODO: this is hard to follow, we plan to write a hands-on tutorial, showing how to realise a new target converter.
If you want to develop a new rdf2pg target, ie, convert to a new property graph format or graph database, the following are the main elements to consider.
- The rdf2pg basic elements are arranged as a core library and a command line interface core library. Quite expectedly, the first contains the elements described in the previous section, while the CLI core contains facilities to wrap your new target library with a command line interface.
- We recommend that you arrange your new target code in a similar way, that is, a library working out the conversion that can be invoked programmatically, and a CLI tool that uses the former. The two can be arranged as Maven modules, as in the case of rdf2neo and rdf2graphml.
- Likely, most of the conversion is going to be done by your extension of
PGNodeHandlerandPGRelationHandler, that is, the components that get node/relation identifiers, fetch further details and finally make the corresponding PG entities. See what already exists for rdf2neo/rdf2graphml. - You also need to extend
PGNodeMakeProcessorandPGRelationMakeProcessor, that is the components that fetch the entity identifiers and invoke the handlers above in batches (ie, the first part of the conversion pipeline described above). These are marked as abstract classes, in order to force an extension that at least binds them to the corresponding handler you want to use in your target-specific package, binding that should be done through the Java generics that those classes use. That said, in most cases probably you don't need any actual code in these extensions, since the SPARQL fetching part is likely to be independent of any specific PG target. Similarly, your handlers can reuse theRdfDataManagermethods to fetch node/relation details. - Likely, you will be able to reuse
ConfigItem, that is, the component to get configuration information from Spring files, such as SPARQL queries. These information are usually the same for all the possible PG targets, however,Neo4jConfigItemis an example where this class is extended with additional configuration options. - The whole mapping+conversion process is started by some extension of
MultiConfigPGMaker, which uses some kind ofConfigItemto instantiate single-type conversion components, coded by the classSimplePGMakerand its extensions. Similarly to the previous point, these skeleton classes formally require local extensions, but usually shouldn't need much specific logic, since they manage a general process that is common to most mappings/conversions. - In the command line package, what usually instantiates and uses a
MultiConfigPGMakerextension is a subclass of theRdf2PgCommandclass, where the latter is a CLI skeleton, invoking all of the mapping+conversion process described above starting from CLI arguments. This includes the processing of common arguments (eg, the input TDB path) and by extending this class for your specific CLI, you'll have these options available and parsed automatically. - Note that the CLI architecture is based on Spring: a converter (script) is expected to invoke
Rdf2PGCli, themain()method in this class loads a Spring context (viagetInstance()), so that Spring will auto-wire thecommandfield in the same class, by looking for a subclass ofRdf2PgCommand, that is, the concrete implementation of the converter CLI invoker. This implies that in your own target-specific converter there should be only one implementation of such class, to be used as an entry point for Spring. See also the@ComponentScanannotation in `Rdf2PGCli``. - Note that there is an even more general super-class of
Rdf2PgCommand, which isCliCommand. This is a simple general placeholder, which could be used for rdf2pg-related commands that don't share the common elements inRdf2PgCommand, eg, if they do some maintenance and don't require configuration or RDF input.