🌍 한국어 ∙ English ∙ 中文简体 ∙ 中文繁體 ∙ 日本語 ∙ Deutsch ∙ Español ∙ Português

🎙️ Leistungsstarke KI-gestützte Webanwendung für YouTube-Videoverarbeitung, Spracherkennung, Übersetzung und mehrsprachige Text-to-Speech-Funktion
Voice-Pro ist eine hochmoderne Web-App, die die Erstellung von Multimedia-Inhalten revolutioniert. Sie kombiniert YouTube-Video-Downloads, Stimmseparation, Spracherkennung, Übersetzung und Text-to-Speech (TTS) in einem einzigen, leistungsstarken Tool und bietet so eine ideale Lösung für Kreative, Forscher und mehrsprachige Profis.
- 🔊 Erstklassige Spracherkennung: Whisper, Faster-Whisper, Whisper-Timestamped
- 🎤 Zero-Shot-Stimmklonierung: F5-TTS, E2-TTS, CosyVoice
- 📢 Mehrsprachige Text-to-Speech: Edge-TTS, kokoro
- 🎥 YouTube-Verarbeitung & Audioextraktion: yt-dlp
- 🌍 Sofortige Übersetzung in über 100 Sprachen: Deep-Translator
- 🔇 Professionelle Gesangsisolierung: UVR5
- 🔥 AI-Cover-Erstellung: RVC
Als starke Alternative zu ElevenLabs bietet Voice-Pro Podcastern, Entwicklern und Kreativen fortschrittliche Sprachlösungen.
- Voice-Pro wurde auf v2.x aktualisiert (Python 3.10.15, Torch 2.5.1+cu124, Gradio 5.14.0)
- 🆓 Die kostenlose Testversion unterstützt bis zu 60 Sekunden Medienverarbeitung
- 🔥 Neue AI-Cover-Funktion hinzugefügt
- 🎤 Unterstützung für CosyVoice und kokoro hinzugefügt
- ⏳ Beim ersten Start wird CozyVoice2-0.5B (9 GB) heruntergeladen. Je nach Netzwerkgeschwindigkeit kann dies über eine Stunde dauern
- 🎧 Stimmproben für die Klonierung werden kontinuierlich aktualisiert
- Anleitung:
- Upgrade von v1.x auf v2.x: Unmöglich. Daher wird empfohlen, den installer_files Ordner zu löschen und die neueste Version von start.bat auszuführen.
- Upgrade von v2.x auf v2.x: Möglich. Laden Sie den neuesten Code herunter und führen Sie update.bat aus.
- Erstanwender: Bitte beachten Sie die Installationsanleitung unten.
- Fehlerbehebung: In den meisten Fällen wird das Problem durch Löschen des installer_files Ordners und anschließendes Ausführen von configure.bat und start.bat nacheinander behoben.
voice-pro-demo-v1.6.7-1080p.mp4
Demo des umfassenden Medienverarbeitungs-Workflows im Studio-Tab: Zeigt einen durchgehenden Prozess von YouTube-Video-Download über KI-basierte Stimmseparation, automatische Whisper-Untertitel, mehrsprachige Übersetzung bis hin zu professioneller Synchronisation mit F5-TTS.
f5-tts-demo-elon-zuckerberg-1115-3.mp4
Demo der innovativen KI-Stimmklonierung von F5-TTS: Präsentiert fortschrittliche Sprachkonvertierungstechnologie, die die tatsächlichen Stimmen von Mark Zuckerberg und Elon Musk präzise nachahmt, um völlig neue Inhalte zu erstellen.
321132645-44ee3893-145d-474a-840b-1ff45802dfbf.mp4
Erstellt eine Trump-Version von IUs „Cupid“, Kim Kwang-seoks „Ich vermisse dich“ und „Brief eines Gefreiten“.
voice-pro-demo-v1.5.7-h264-1080p-live.mp4
Demo der Echtzeit-Mehrsprachigkeitsfunktion: Zeigt einen innovativen Prozess der mehrsprachigen Medienverarbeitung, der BBC-Nachrichteninhalte sofort erfasst, Untertitel in Echtzeit generiert und diese direkt in andere Sprachen übersetzt.
- YouTube-Video-Downloads & Audioextraktion
- Stimmseparation mit MDX-Net und Demucs
- Unterstützung für Spracherkennung und Übersetzung in über 100 Sprachen
- Sprache-zu-Text: Whisper, Faster-Whisper, Whisper-Timestamped
- Text-zu-Sprache:
- Edge-TTS: Über 100 Sprachen, mehr als 400 Stimmen
- E2-TTS, F5-TTS, CosyVoice: Zero-Shot-Klonierung
- kokoro: Platz 2 im HuggingFace TTS Arena
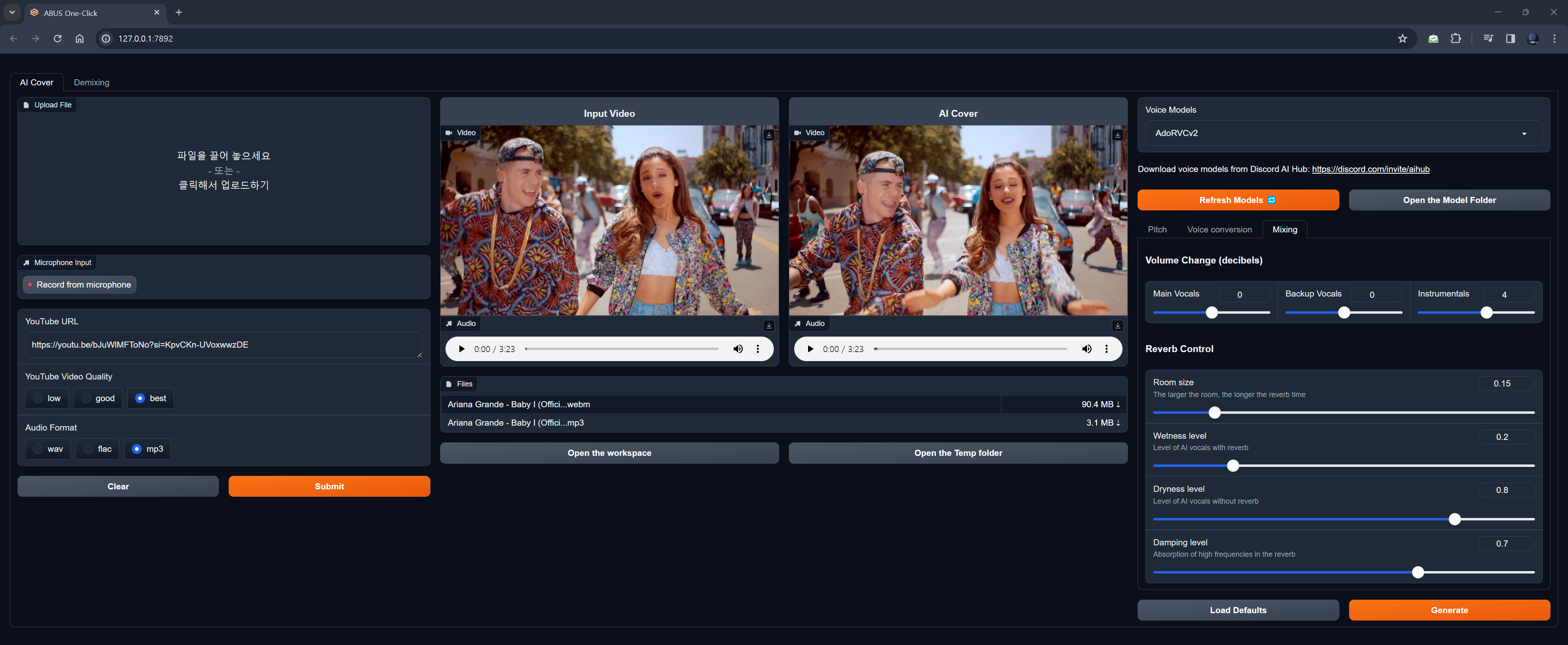
- 🔥 AI-Cover (Sprache-zu-Sprache): Gesangsentfernung mit UVR5, Modulation mit RVC
- Sofortige Spracherkennung
- Mehrsprachige Übersetzung in Echtzeit
- Anpassbare Audioeingaben
- All-in-One-Hub: YouTube-Downloads, Rauschunterdrückung, Untertitel, Übersetzung, TTS
- Unterstützt alle ffmpeg-kompatiblen Formate
- Ausgabeoptionen: WAV, FLAC, MP3
- Untertitel & Erkennung für über 100 Sprachen
- TTS mit einstellbarer Geschwindigkeit, Lautstärke und Tonlage

- Untertitel-spezifisch: Über 90 Sprachen
- Integrierte Untertitelanzeige mit Video
- Wortweise Hervorhebung & Optionen zur Rauschunterdrückung
- Übersetzung in über 100 Sprachen
- Unterstützt Untertiteldateien (ASS, SSA, SRT usw.)
- Echtzeit-Spracherkennung und Übersetzung
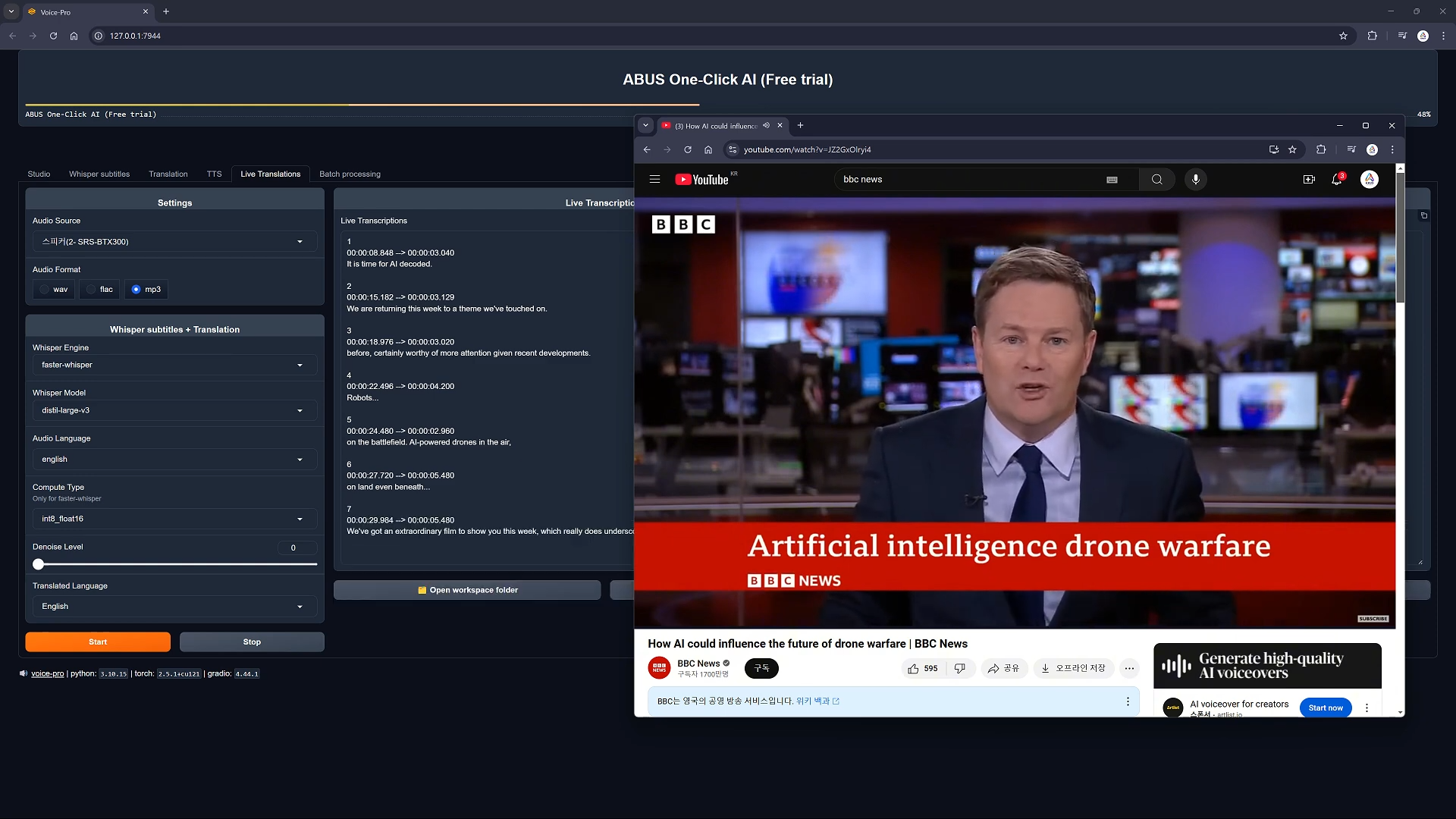
- Optionen: Edge-TTS, F5-TTS, CosyVoice, kokoro
- Podcasts mit Promi-Stimmen & mehrsprachige Unterstützung

- Gesangsentfernung: MDX-Net, Demucs
- Stimmmodulation: RVC
- AI-Stimmen können von Discord AI Hub heruntergeladen oder über [email protected] angefordert werden
- OS: Windows 10/11 (64-Bit) ※ Linux/Mac nicht unterstützt
- GPU: NVIDIA mit CUDA 12.4 (empfohlen)
- VRAM: 4 GB+ (8 GB+ bevorzugt)
- RAM: 4 GB+
- Speicher: Mindestens 20 GB freier Speicherplatz
- Internet: Erforderlich
Mit configure.bat und start.bat lässt sich Voice-Pro einfach installieren.
- Laden Sie die neueste Version von
herunter (Source code (zip))
git clone https://github.com/abus-aikorea/voice-pro.git- 🚀 configure.bat
- Installiert git, ffmpeg und CUDA (bei NVIDIA-GPU)
- Einmalige Ausführung; Internet erforderlich, kann über 1 Stunde dauern
- Schließen Sie das Befehlsfenster nicht
- 🚀 start.bat
- Startet die Voice-Pro-WebUI
- Bei erstmaliger Ausführung werden Abhängigkeiten installiert (kann über 1 Stunde dauern)
- Bei Problemen installer_files löschen und erneut ausführen
- 🚀 update.bat: Aktualisiert die Python-Umgebung (schneller als Neuinstallation)
- Führen Sie uninstall.bat aus oder löschen Sie den Ordner (portable Installation)
- Schließen Sie das Windows-Befehlsfenster und führen Sie start.bat erneut aus
- Öffnen Sie den Browser manuell und geben Sie die im Befehlsfenster angezeigte Adresse ein (z. B. http://127.0.0.1:7892)
- Überprüfen Sie den GPU-Speicherstatus im Windows Task-Manager – Reiter „Leistung“
- Stellen Sie den Rauschunterdrückungslevel auf 0 oder 1 ein (Level 2 erfordert mindestens 8 GB GPU-Speicher)
- Stellen Sie den Berechnungstyp auf „int“ ein („float“ bietet bessere Qualität, benötigt aber mehr GPU-Speicher)
- Größere Whisper-Modelle tendieren zu besserer Untertitelqualität (large > medium > small > base > tiny), dies ist jedoch nicht garantiert
- Unter den Berechnungstypen bietet „float“ gute Leistung; „int“ reduziert GPU-Nutzung und erhöht die Geschwindigkeit durch Modellquantisierung, allerdings mit Leistungseinbußen
- Ein höherer Rauschunterdrückungslevel entfernt mehr Hintergrundgeräusche und nutzt nur die verbleibende Stimme für die Erkennung, garantiert aber nicht immer bessere Ergebnisse
Windows Defender könnte eine Warnung über eine nicht vertrauenswürdige Anwendung anzeigen und die weitere Ausführung von Voice-Pro verhindern.
- SmartScreen „Warnung“-Einstellung: Klicken Sie auf „Weitere Infos“ und dann auf „Trotzdem ausführen“
- SmartScreen „Blockieren“-Einstellung: Öffnen Sie die Eigenschaften von start.bat, aktivieren Sie „Entsperren“, übernehmen Sie die Änderungen und führen Sie start.bat erneut aus
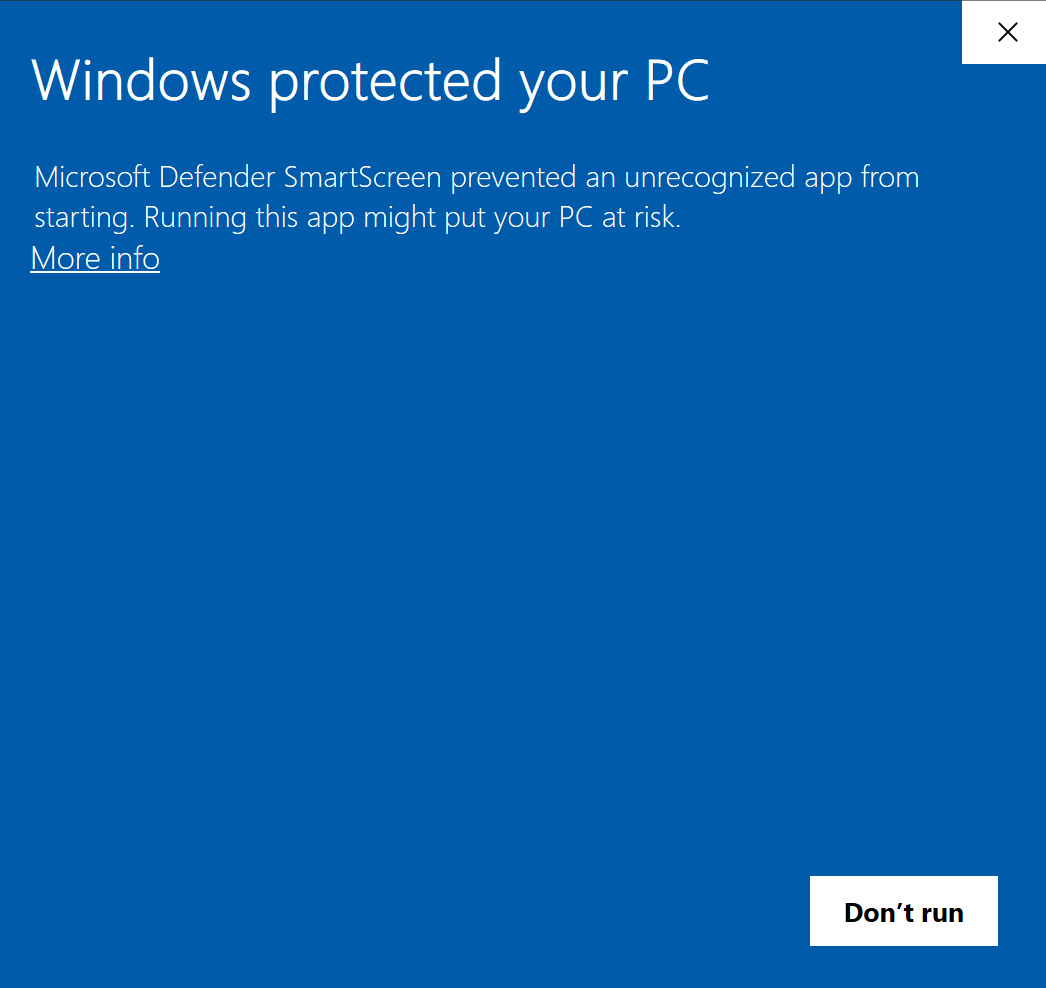
Falls Windows Defender eine Batch-Datei fälschlicherweise als Trojaner erkennt, spricht man oft von einem „False Positive“. Zur Lösung dieses Problems können Sie folgende Schritte unternehmen:
- Datei-Ausnahmebehandlung: In Windows Defender können Sie bestimmte Dateien oder Prozesse von der Sicherheitsprüfung ausnehmen. Gehen Sie wie folgt vor:
- Klicken Sie auf die Schaltfläche „Start“ und gehen Sie zu „Einstellungen“
- Klicken Sie auf „Update und Sicherheit“
- Wählen Sie „Windows-Sicherheit“ und gehen Sie zu „Viren- und Bedrohungsschutz“
- Klicken Sie auf „Einstellungen für Viren- und Bedrohungsschutz verwalten“
- Wählen Sie unter „Einstellungen für Viren- und Bedrohungsschutz“ die Option „Ausnahme hinzufügen“
- Wählen Sie „Datei oder Ordner“, suchen Sie die betroffene Batch-Datei und fügen Sie sie als Ausnahme hinzu
- Windows Defender vorübergehend deaktivieren: Dies kann eine temporäre Lösung sein. Seien Sie jedoch vorsichtig, da Ihr Computer anderen Bedrohungen ausgesetzt sein könnte
- Problem an Antivirensoftware melden: Wenn Sie sicher sind, dass die Datei kein Trojaner ist, können Sie sie Microsoft als „False Positive“ melden. Microsoft wird dies prüfen und entsprechende Maßnahmen ergreifen
- Dieses Repository bietet eine kostenlose Testversion von Voice-Pro.
- Die kostenlose Testversion von Voice-Pro ermöglicht die Verarbeitung von Medien bis zu 60 Sekunden.
- Die offizielle Version von Voice-Pro kann über die offizielle ABUS-Website (https://abuskorea.imweb.me) erworben werden.
- Wenn Sie an diesem Projekt teilnehmen und uns helfen möchten, können Sie gerne ein Issues erstellen.
- Wenn etwas schief geht, senden Sie bitte einen Pull Requests, um dieses Projekt zu verbessern.
- Jede Art von Beitrag ist willkommen.
- Für Anfragen zu Käufen, Geschäftspartnerschaften, technischer Anpassung, Investitionen und anderen Angelegenheiten kontaktieren Sie uns bitte per E-Mail ([email protected]).
- Wenn Ihnen dieses Projekt gefällt, geben Sie diesem Repository bitte einen Stern. Wir würden uns sehr freuen. ⭐⭐⭐
- Sie können Voice-Pro hier mit einer Spende unterstützen:

- E-Mail: [email protected]
- Homepage (Koreanisch): https://abuskorea.imweb.me
- Amazon: US | Japan | Singapore | UAE
- Naver: Software | Solution
- Demucs: https://github.com/facebookresearch/demucs
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- gradio: https://github.com/gradio-app/gradio
- edge-TTS: https://github.com/rany2/edge-tts
- F5-TTS: https://github.com/SWivid/F5-TTS.git
- openai-whisper: https://github.com/openai/whisper
- faster-whisper: https://github.com/SYSTRAN/faster-whisper
- whisper-timestamped: https://github.com/linto-ai/whisper-timestamped
- RVC-Project: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- UVR5: https://github.com/Anjok07/ultimatevocalremovergui
![]() by ABUS
by ABUS