🌍 한국어 ∙ English ∙ 中文简体 ∙ 中文繁體 ∙ 日本語 ∙ Deutsch ∙ Español ∙ Português

🎙️ Poderoso aplicativo da web com tecnologia AI para processamento de vídeo do YouTube, reconhecimento de fala, tradução e texto para fala com suporte multilíngue
Voice-Pro é um aplicativo web de ponta que transforma a criação de conteúdo multimídia. Ele integra download de vídeos do YouTube, separação de voz, reconhecimento de fala, tradução e conversão de texto em fala (TTS) em uma única ferramenta poderosa, oferecendo uma solução ideal para criadores, pesquisadores e profissionais multilíngues.
- 🔊 Reconhecimento de fala de alto nível: Whisper, Faster-Whisper, Whisper-Timestamped
- 🎤 Clonagem de voz Zero-Shot: F5-TTS, E2-TTS, CosyVoice
- 📢 Conversão de texto em fala multilíngue: Edge-TTS, kokoro
- 🎥 Processamento de vídeos do YouTube e extração de áudio: yt-dlp
- 🌍 Tradução instantânea para mais de 100 idiomas: Deep-Translator
- 🔇 Separação vocal de nível profissional: UVR5
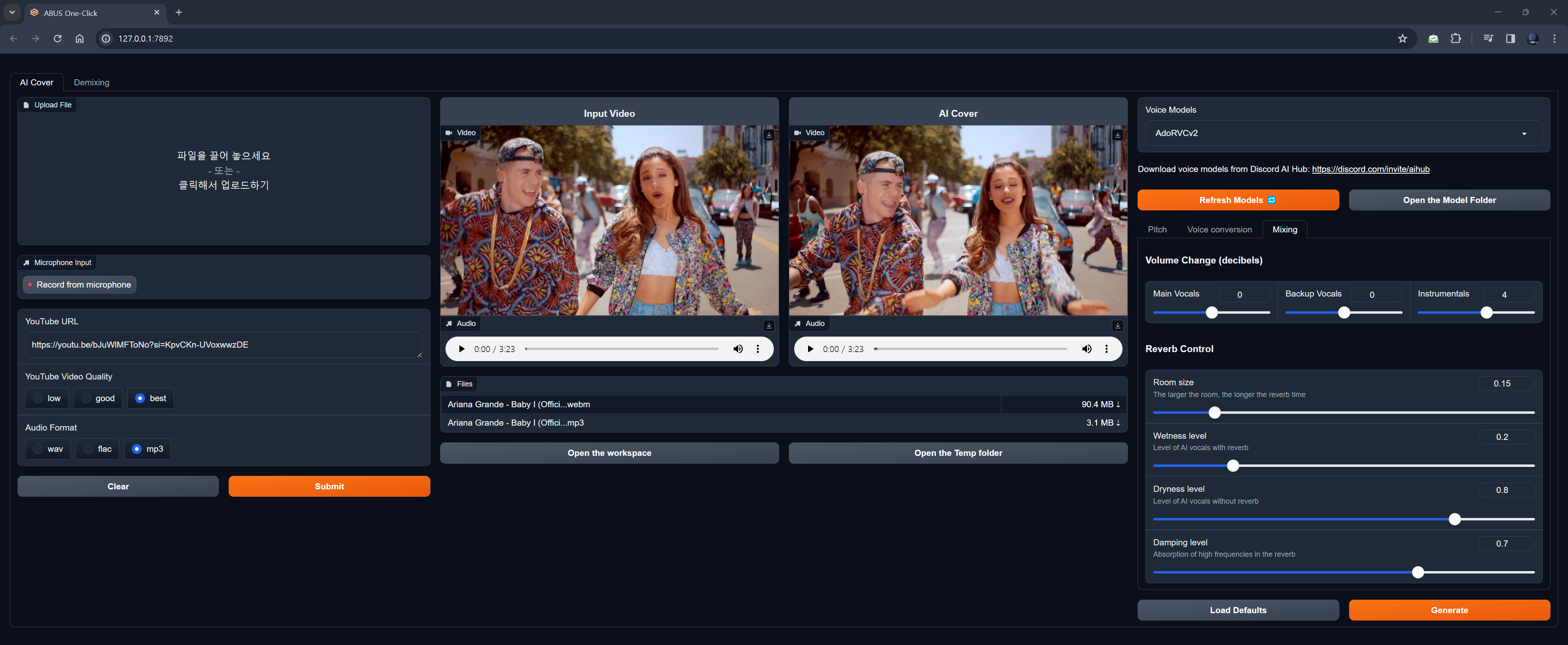
- 🔥 Criação de capas por IA: RVC
Como uma alternativa robusta ao ElevenLabs, o Voice-Pro capacita podcasters, desenvolvedores e criadores com soluções de voz avançadas.
- O Voice-Pro foi atualizado para a versão v2.x (Python 3.10.15, Torch 2.5.1+cu124, Gradio 5.14.0)
- 🆓 A versão de teste gratuita suporta até 60 segundos de processamento de mídia
- 🔥 Nova função AI Cover adicionada
- 🎤 Suporte para CosyVoice e kokoro incluído
- ⏳ Na primeira execução, será feito o download do CozyVoice2-0.5B (9GB). Dependendo da velocidade da rede, pode levar mais de uma hora
- 🎧 Amostras de voz para clonagem serão continuamente atualizadas
- Orientações:
- Atualização de v1.x para v2.x: Impossível. Portanto, recomenda-se excluir a pasta installer_files e executar a versão mais recente de start.bat.
- Atualização de v2.x para v2.x: Possível. Baixe o código mais recente e execute update.bat.
- Novos usuários: Consulte as instruções de instalação abaixo.
- Solução de problemas: Na maioria dos casos, excluir a pasta installer_files e executar configure.bat e start.bat sequencialmente resolverá o problema.
voice-pro-demo-v1.6.7-1080p.mp4
Demonstração do fluxo de trabalho completo de processamento de mídia na aba Estúdio: Mostra um processo contínuo de transformação de mídia, desde o download de vídeos do YouTube até a separação de vozes por IA, legendas automáticas com Whisper, tradução multilíngue e dublagem profissional usando F5-TTS.
f5-tts-demo-elon-zuckerberg-1115-3.mp4
Demonstração da tecnologia inovadora de clonagem de voz por IA do F5-TTS: Apresenta uma tecnologia avançada de conversão de voz que imita precisamente as vozes reais de Mark Zuckerberg e Elon Musk para criar conteúdos totalmente novos.
321132645-44ee3893-145d-474a-840b-1ff45802dfbf.mp4
Cria uma versão de Trump para "Cupid" de IU, "Saudades de Você" de Kim Kwang-seok e "Carta de um Soldado".
voice-pro-demo-v1.5.7-h264-1080p-live.mp4
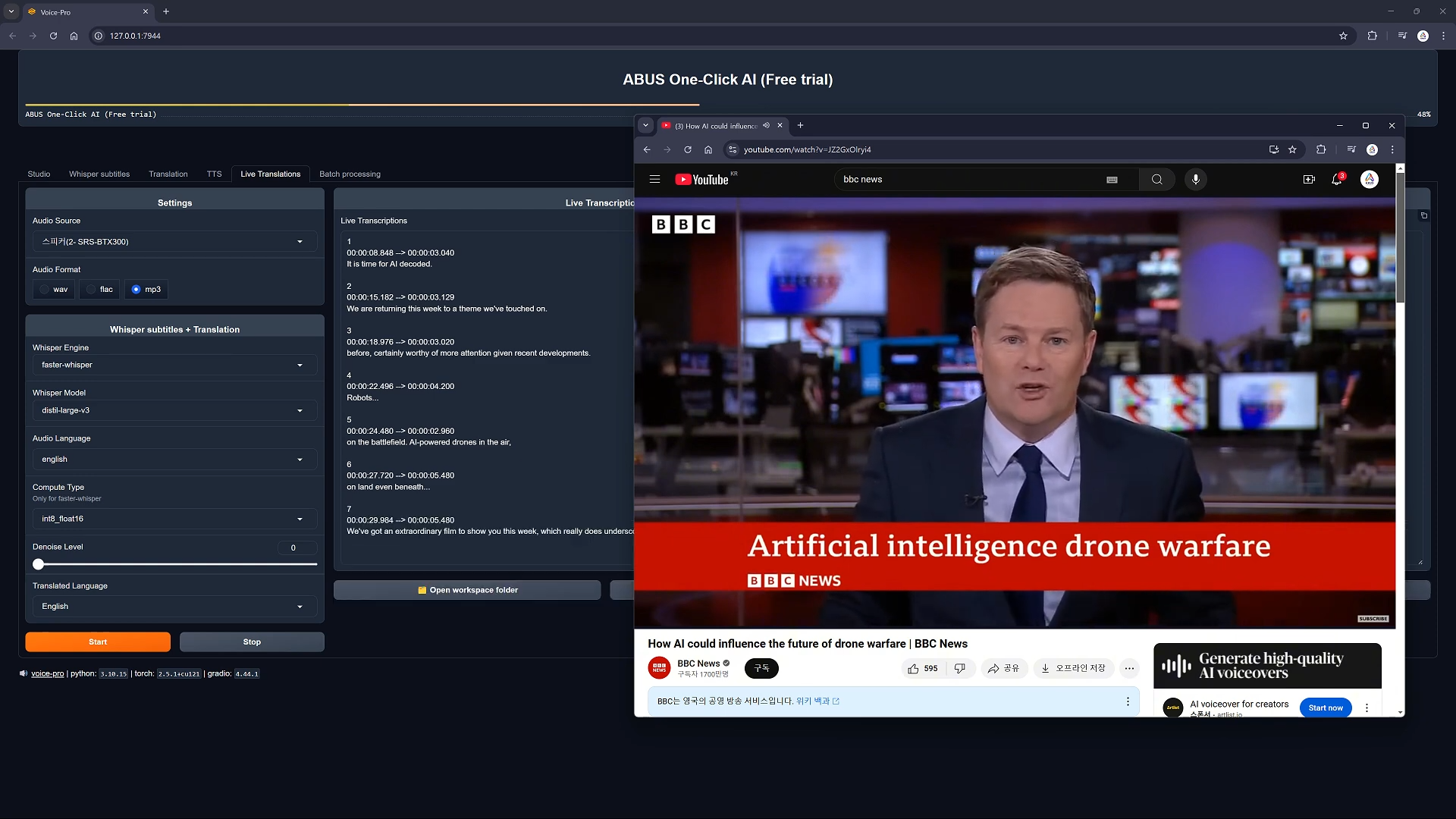
Demonstração da função de tradução multilíngue em tempo real: Apresenta um processo inovador de processamento de mídia multilíngue que captura instantaneamente conteúdos de notícias da BBC, gera legendas em tempo real e as traduz imediatamente para outros idiomas.
- Download de vídeos do YouTube e extração de áudio
- Separação de voz com MDX-Net e Demucs
- Suporte para reconhecimento de fala e tradução em mais de 100 idiomas
- Fala para Texto: Whisper, Faster-Whisper, Whisper-Timestamped
- Texto para Fala:
- Edge-TTS: Mais de 100 idiomas, mais de 400 vozes
- E2-TTS, F5-TTS, CosyVoice: Clonagem Zero-Shot
- kokoro: 2º lugar no HuggingFace TTS Arena
- 🔥 AI Cover (Fala para Fala): Remoção vocal com UVR5, modulação com RVC
- Reconhecimento de fala instantâneo
- Tradução multilíngue em tempo real
- Entradas de áudio personalizáveis
- Centro integrado: Downloads do YouTube, remoção de ruído, legendas, tradução e TTS
- Suporta todos os formatos compatíveis com ffmpeg
- Opções de saída: WAV, FLAC, MP3
- Legendas e reconhecimento para mais de 100 idiomas
- TTS com ajustes de velocidade, volume e tom

- Foco em legendas: Mais de 90 idiomas
- Exibição de legendas integrada ao vídeo
- Destaque por palavra e opções de remoção de ruído
- Tradução para mais de 100 idiomas
- Suporte a arquivos de legendas (ASS, SSA, SRT, etc.)
- Reconhecimento e tradução de voz em tempo real
- Opções: Edge-TTS, F5-TTS, CosyVoice, kokoro
- Podcasts com vozes de celebridades e suporte multilíngue

- Remoção vocal: MDX-Net, Demucs
- Modulação de voz: RVC
- Faça download de vozes IA no Discord AI Hub ou solicite por [email protected]
- SO: Windows 10/11 (64 bits) ※ Linux/Mac não suportados
- GPU: NVIDIA com suporte a CUDA 12.4 (recomendado)
- VRAM: 4 GB ou mais (8 GB+ preferível)
- RAM: 4 GB ou mais
- Armazenamento: Pelo menos 20 GB de espaço livre
- Internet: Obrigatória
Instale o Voice-Pro facilmente com configure.bat e start.bat.
- Baixe a versão mais recente em
(Source code (zip))
git clone https://github.com/abus-aikorea/voice-pro.git- 🚀 configure.bat
- Instala git, ffmpeg e CUDA (se usar GPU NVIDIA)
- Execute apenas uma vez; requer internet, pode levar mais de 1 hora
- Não feche a janela de comando
- 🚀 start.bat
- Inicia a interface web do Voice-Pro
- Na primeira execução, instala dependências (pode levar mais de 1 hora)
- Em caso de problemas, delete installer_files e execute novamente
- 🚀 update.bat: Atualiza o ambiente Python (mais rápido que reinstalar)
- Execute uninstall.bat ou delete a pasta (instalação portátil)
- Feche a janela de comando do Windows e execute start.bat novamente
- Abra o navegador manualmente e insira o endereço exibido na janela de comando (ex.: http://127.0.0.1:7892)
- Verifique o status da memória da GPU no Gerenciador de Tarefas do Windows - guia "Desempenho"
- Defina o nível de remoção de ruído para 0 ou 1 (o nível 2 requer pelo menos 8 GB de memória GPU)
- Configure o tipo de cálculo como "int" (o tipo "float" tem melhor qualidade, mas exige mais memória GPU)
- Modelos Whisper maiores tendem a melhorar a qualidade das legendas (large > medium > small > base > tiny), mas isso não é garantido
- Entre os tipos de cálculo, "float" oferece bom desempenho; "int" reduz o uso da GPU e aumenta a velocidade por meio de quantização do modelo, mas com perda de desempenho
- Aumentar o nível de remoção de ruído elimina mais sons de fundo e usa apenas a voz restante para reconhecimento, mas não garante sempre bons resultados
O Windows Defender pode exibir um aviso sobre um aplicativo não confiável e impedir a execução adicional do Voice-Pro.
- Configuração "Aviso" do SmartScreen: Clique em "Mais informações" e depois em "Executar mesmo assim"
- Configuração "Bloquear" do SmartScreen: Abra as propriedades do start.bat, marque "Desbloquear", aplique as alterações e execute novamente o start.bat
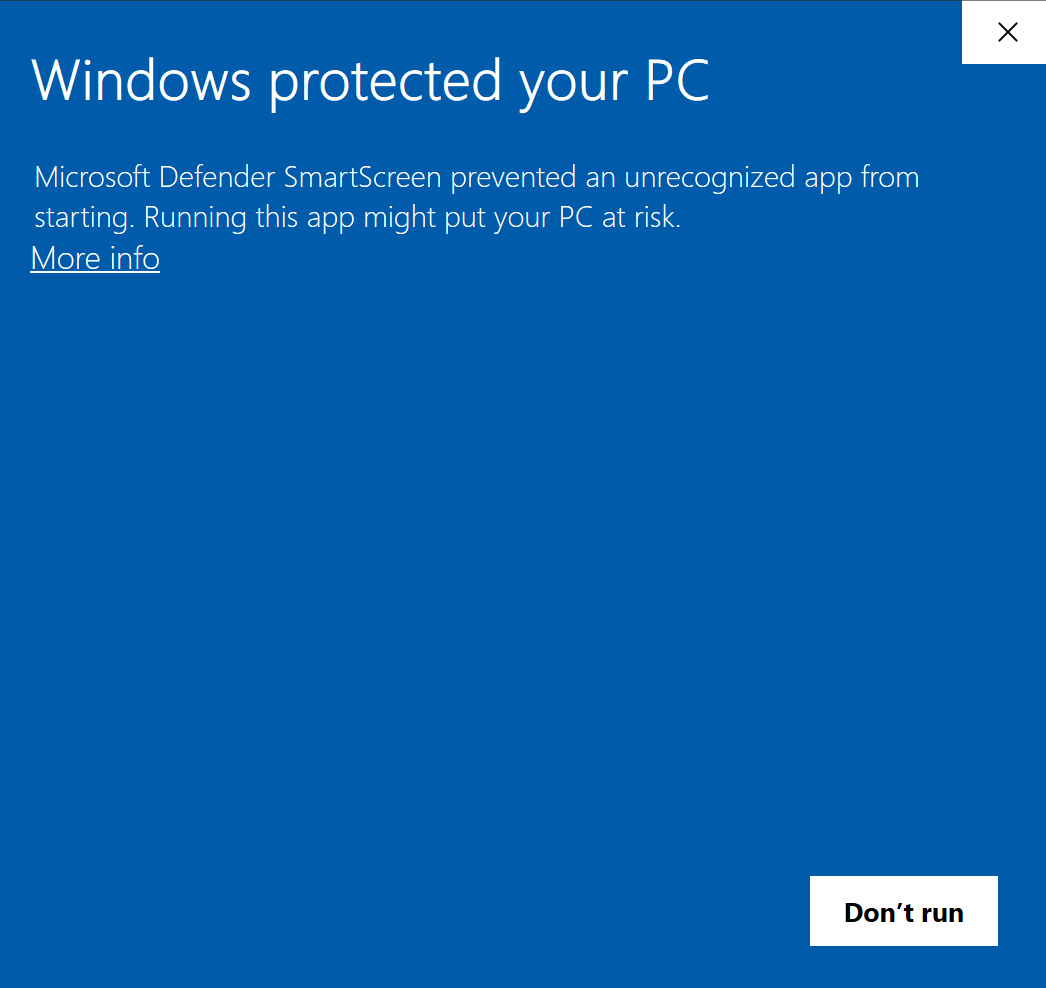
Quando o Windows Defender reconhece erroneamente um arquivo em lote como um Trojan, isso é frequentemente chamado de "Falso Positivo". Para resolver esse problema, siga estas etapas:
- Tratamento de exceções de arquivo: No Windows Defender, você pode configurar arquivos ou processos específicos para ignorar a verificação de segurança. Siga os passos abaixo:
- Clique no botão "Iniciar" e vá para "Configurações"
- Clique em "Atualização e Segurança"
- Selecione "Segurança do Windows" e vá para "Proteção contra vírus e ameaças"
- Clique em "Gerenciar configurações de proteção contra vírus e ameaças"
- Selecione "Adicionar uma exclusão" em "Configurações de proteção contra vírus e ameaças"
- Escolha "Arquivo ou Pasta", localize o arquivo em lote problemático e adicione-o como exceção
- Desativar temporariamente o Windows Defender: Isso pode ser uma solução temporária. No entanto, tome cuidado ao usar esse método, pois seu computador pode ficar exposto a outras ameaças
- Reportar o problema ao software antivírus: Se você tiver certeza de que o arquivo não é um Trojan, pode reportá-lo à Microsoft como "Falso Positivo". A Microsoft revisará e tomará as medidas necessárias
- Este repositório oferece uma versão de teste gratuita do Voice-Pro.
- A versão de teste gratuita do Voice-Pro permite processar até 60 segundos de mídia.
- A versão oficial do Voice-Pro pode ser adquirida através do site oficial da ABUS (https://abuskorea.imweb.me).
- Se você deseja participar e nos ajudar com este projeto, sinta-se à vontade para criar um Issues.
- Se algo der errado, envie um Pull requests para melhorar este projeto.
- Qualquer tipo de contribuição é bem-vindo.
- Para dúvidas relacionadas a compras, parcerias comerciais, ajustes técnicos, investimentos e outros assuntos, entre em contato conosco por e-mail ([email protected]).
- Se você gosta deste projeto, por favor, dê uma estrela a este repositório. Nós agradeceríamos muito. ⭐⭐⭐
- Você pode apoiar o Voice-Pro com uma doação aqui:

- E-mail: [email protected]
- Página inicial (Coreano): https://abuskorea.imweb.me
- Amazon: US | Japan | Singapore | UAE
- Naver: Software | Solução
- Demucs: https://github.com/facebookresearch/demucs
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- gradio: https://github.com/gradio-app/gradio
- edge-TTS: https://github.com/rany2/edge-tts
- F5-TTS: https://github.com/SWivid/F5-TTS.git
- openai-whisper: https://github.com/openai/whisper
- faster-whisper: https://github.com/SYSTRAN/faster-whisper
- whisper-timestamped: https://github.com/linto-ai/whisper-timestamped
- RVC-Project: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- UVR5: https://github.com/Anjok07/ultimatevocalremovergui
![]() por ABUS
por ABUS