🌍 한국어 ∙ English ∙ 中文简体 ∙ 中文繁體 ∙ 日本語 ∙ Deutsch ∙ Español ∙ Português

Voice-Pro是一款革新多媒体内容制作的先进网页应用。它将YouTube视频下载、音频分离、语音识别、翻译和文本转语音(TTS)集成到一个强大的工具中,为创作者、研究人员和多语言专家提供理想的解决方案。
- 🔊 顶级语音识别:Whisper、Faster-Whisper、Whisper-Timestamped
- 🎤 零样本声音克隆:F5-TTS、E2-TTS、CosyVoice
- 📢 多语言文本转语音:Edge-TTS、kokoro
- 🎥 YouTube处理和音频提取:yt-dlp
- 🌍 100多种语言即时翻译:Deep-Translator
- 🔇 专业级人声分离:UVR5
- 🔥 AI翻唱制作:RVC
作为ElevenLabs的强大替代方案,Voice-Pro为播客主持人、开发者和创作者提供高级语音解决方案。
- Voice-Pro已更新至v2.x版本(Python 3.10.15, Torch 2.5.1+cu124, Gradio 5.14.0)
- 🆓 免费试用版支持最长60秒的媒体处理
- 🔥 新增AI翻唱功能
- 🎤 新增CosyVoice和kokoro支持
- ⏳ 首次运行时需下载CozyVoice2-0.5B (9GB),根据网络速度可能需要1小时以上
- 🎧 声音克隆用的语音样本将持续更新
- 提示:
- 从 v1.x 升级到 v2.x:不可能。因此,建议删除 installer_files 文件夹并运行最新版本的 start.bat。
- 从 v2.x 升级到 v2.x:可能。下载最新代码后,运行 update.bat。
- 首次用户:请参考以下安装方法。
- 问题解决:在大多数情况下,删除 installer_files 文件夹并依次运行 configure.bat 和 start.bat 即可解决问题。
voice-pro-demo-v1.6.7-1080p.mp4
工作室标签页的综合媒体处理工作流程演示:从YouTube视频下载到AI语音分离、Whisper自动字幕、多语言翻译,再到使用F5-TTS进行专业配音的一站式媒体转换过程。
f5-tts-demo-elon-zuckerberg-1115-3.mp4
F5-TTS的创新AI声音克隆技术演示:精确模仿马克·扎克伯格和埃隆·马斯克的真实声音,创建全新内容的高级语音转换技术展示。
321132645-44ee3893-145d-474a-840b-1ff45802dfbf.mp4
制作特朗普版本的IU《Cupid》、金光石《想念的人》、《士兵的信》。
voice-pro-demo-v1.5.7-h264-1080p-live.mp4
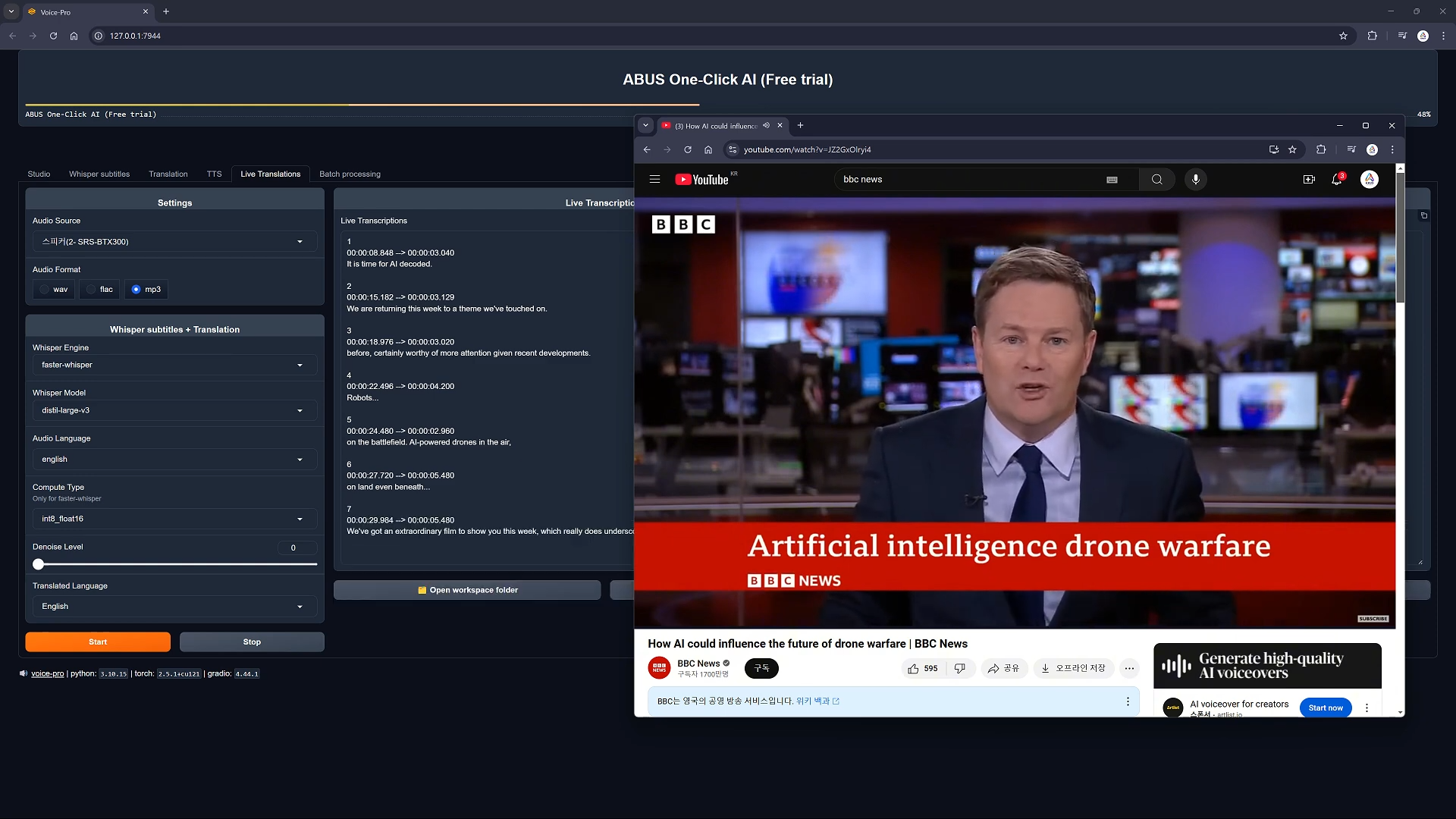
实时多语言翻译功能演示:即时捕获BBC新闻内容,生成实时字幕,并立即翻译成其他语言的创新多语言媒体处理过程。
- YouTube视频下载和音频提取
- 使用MDX-Net和Demucs进行语音分离
- 支持100多种语言的语音识别和翻译
- 语音转文本: Whisper、Faster-Whisper、Whisper-Timestamped
- 文本转语音:
- Edge-TTS:支持100多种语言,400多种声音
- E2-TTS、F5-TTS、CosyVoice:零样本克隆
- kokoro:在HuggingFace TTS Arena中排名第二
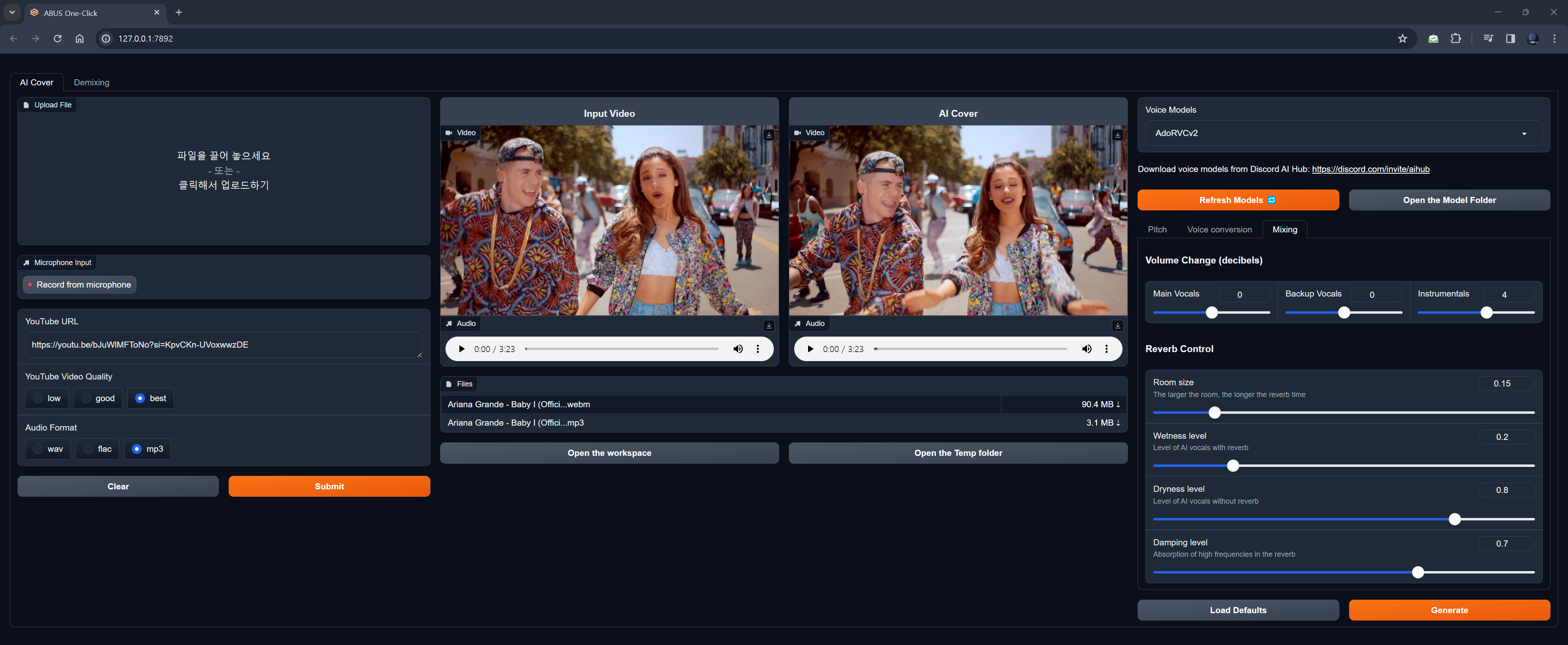
- 🔥 AI翻唱(语音转语音): 使用UVR5移除人声,使用RVC进行变声
- 即时语音识别
- 实时多语言翻译
- 可自定义音频输入
- 集成中心:YouTube下载、降噪、字幕、翻译、TTS
- 支持所有ffmpeg兼容格式
- 输出选项:WAV、FLAC、MP3
- 支持100多种语言的字幕和识别
- 可调节TTS的速度、音量、音调

- 专用字幕:90多种语言
- 视频集成字幕显示
- 单词级高亮和降噪选项
- 100多种语言翻译
- 支持字幕文件(ASS、SSA、SRT等)
- 实时语音识别和翻译
- 选项:Edge-TTS、F5-TTS、CosyVoice、kokoro
- 使用名人声音制作播客和多语言支持

- 人声移除:MDX-Net、Demucs
- 语音变调:RVC
- AI声音可从Discord AI Hub下载或发邮件至[email protected]请求
- 操作系统: Windows 10/11(64位)※不支持Linux/Mac
- 显卡: 支持CUDA 12.4的NVIDIA显卡(推荐)
- 显存: 4GB以上(推荐8GB以上)
- 内存: 4GB以上
- 存储: 20GB以上可用空间
- 网络: 必需
使用configure.bat和start.bat轻松安装Voice-Pro。
- 从
下载最新发布版本(Source code (zip))
git clone https://github.com/abus-aikorea/voice-pro.git- 🚀 configure.bat
- 安装git、ffmpeg、CUDA(使用NVIDIA GPU时)
- 首次运行一次;需要网络,可能需要1小时以上
- 不要关闭命令窗口
- 🚀 start.bat
- 运行Voice-Pro网页界面
- 首次运行时安装依赖(可能需要1小时以上)
- 如果出现问题,删除installer_files后重新运行
- 🚀 update.bat:更新Python环境(比重新安装更快)
- 运行uninstall.bat或删除文件夹(便携式安装)
- 关闭Windows命令窗口,重新运行start.bat,或
- 直接启动浏览器,在地址栏输入Windows命令窗口显示的地址(例如**http://127.0.0.1:7892**)
- 在Windows任务管理器-性能标签中检查GPU内存状态
- 将降噪级别设置为0或1。降噪级别2需要8GB以上的GPU内存
- 将计算类型设置为int类型。float类型质量更好但需要更多GPU内存
- 字幕质量通常随着使用更大的Whisper模型而提高,但并不总是如此。large > medium > small > base > tiny
- 在计算类型中,float类型性能更好。int类型通过模型量化降低GPU使用量并提高速度,但性能较差
- 提高降噪级别可以更多地去除背景音,只将剩余的语音用于语音识别。但不总是能保证更好的结果
Windows Defender可能会显示不受信任应用程序的警告,并阻止Voice-Pro继续运行。 如果SmartScreen安全级别设置为"警告",请点击"更多信息"后点击"仍要运行"。 如果SmartScreen设置为"阻止"级别,则没有可以运行安装的按钮。在这种情况下,打开start.bat文件的属性,勾选"解除阻止",应用更改后重新运行start.bat文件。
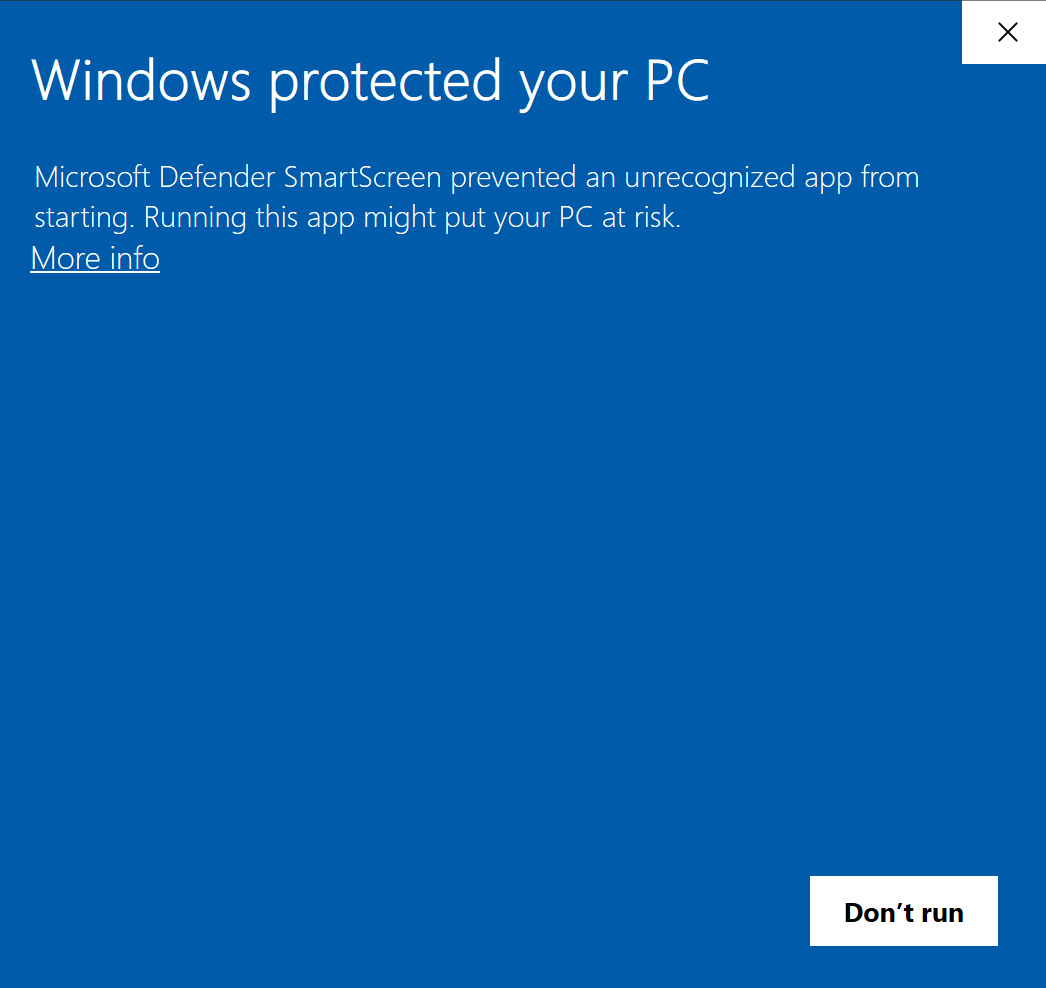
如果Windows Defender错误地将批处理文件识别为特洛伊木马,这通常被称为"误报"。要解决这个问题,可以采取以下步骤:
-
文件例外处理:可以在Windows Defender中设置特定文件或进程跳过安全检查。请按照以下步骤操作:
- 点击"开始"按钮,进入"设置"
- 点击"更新和安全"
- 选择"Windows安全中心",进入"病毒和威胁防护"
- 点击"管理病毒和威胁防护设置"
- 在"病毒和威胁防护设置"中选择"添加或删除排除项"
- 选择"文件或文件夹",找到相关批处理文件并添加为例外
-
暂时禁用Windows Defender:这可以作为临时解决方案。但使用此方法时,请注意计算机可能会暴露于其他威胁中。
-
向防病毒软件报告问题:如果您确信该文件不是特洛伊木马,可以向Microsoft报告为误报。Microsoft会审查后采取必要的措施。
- 此存储库提供 Voice-Pro 的免费试用版。
- Voice-Pro 的免费试用版允许您处理长达 60 秒的媒体。
- Voice-Pro 的正式版本可通过 ABUS 官方网站 (https://abuskorea.imweb.me) 购买。
- 如果您想参与并帮助我们进行此项目,请随时创建一个 Issues。
- 如果出现问题,请提交一个 Pull requests 以改进此项目。
- 欢迎任何类型的贡献。
- 有关购买、商业伙伴关系、技术调整、投资和其他相关事宜的咨询,请通过电子邮件 ([email protected]) 与我们联系。
- 如果您喜欢这个项目,请给这个存储库加星标。我们将非常感谢。 ⭐⭐⭐
- 您可以在这里通过捐赠支持 Voice-Pro:

- 电子邮件:[email protected]
- 主页(韩语):https://abuskorea.imweb.me
- Amazon:US | Japan | Singapore | UAE
- 韩国Naver:软件 | 解决方案
- Demucs: https://github.com/facebookresearch/demucs
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- gradio: https://github.com/gradio-app/gradio
- edge-TTS: https://github.com/rany2/edge-tts
- F5-TTS: https://github.com/SWivid/F5-TTS.git
- openai-whisper: https://github.com/openai/whisper
- faster-whisper: https://github.com/SYSTRAN/faster-whisper
- whisper-timestamped: https://github.com/linto-ai/whisper-timestamped
- RVC-Project: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- UVR5: https://github.com/Anjok07/ultimatevocalremovergui
![]() by ABUS
by ABUS