Pipeline Execution
Note: Prior to reading this document, we strongly recommend that you familiarize yourself with the core concepts of the \psi framework, by reading the Brief Introduction tutorial.
Once a graph of components has been configured, a \psi pipeline may be executed using one of the pipeline's Run() or RunAsync() methods. Calls to Run() are synchronous and will block until the pipeline execution completes, while calls to RunAsync() will start the pipeline execution and return immediately. The following sections will illustrate their use in different pipeline execution scenarios. The tutorial is structured in the following sections:
- Basics of Pipeline Execution - describes the basics of running \psi pipelines live, or in replay.
- Controlling Pipeline Execution - describes mechanisms for controlling pipeline execution, such as replay descriptors, handling exceptions, and responding to pipline execution events.
- Advanced Topics - covers the pipeline clock and the effect of replay mode on message latencies.
There are two modes in which \psi pipelines are generally run: live or replay. In live mode, the pipeline typically contains one or more sensor components that capture and stream live, real-world data, such as a camera (streaming images) or a microphone (streaming sound). Some of these source data streams, as well as other streams flowing through the rest of the application, might be persisted to a store. In contrast, in replay mode, the pipeline is usually configured to use streams that have been persisted in a store as the source of data, and re-run a computation. Replay is therefore a very useful capability that enables a variety of testing and tuning scenarios (e.g. we can persist a video stream to a store, and then replay it many times while tuning parameters for a face detection component, etc.). We begin by illustrating below these two execution modes.
Typically, when running in live mode, the source streams of the pipeline are generated by a set of source components such as cameras, microphones, or other sensor components. In \psi, source components may be finite or infinite. Finite source components produce data for a predetermined length of time, or a fixed number of messages. In contrast, infinite source components may continue producing messages indefinitely for as long as the pipeline is running. Sensor components that capture perpetual streams of live data are generally infinite source components. For more details on how to specify whether a source component is finite or infinite, and on how to correctly author source components, see the Writing Components topic.
If a pipeline contains only infinite source components, then once execution has started, the pipeline will continue to run indefinitely, until it is explicitly stopped. Consider the following simple pipeline which captures images from a webcam and saves the image stream to a data store:
using (var p = Pipeline.Create())
{
// Create a webcam media source component
var webcam = new MediaCapture(p, 1920, 1080, 30);
// Encode the raw image stream to JPEG
var imageStream = webcam.Out.EncodeJpeg(90, DeliveryPolicy.LatestMessage);
// Create a store
var store = PsiStore.Create(pipeline, "demo", "c:\\recordings");
// Write the JPEG image stream to the store
imageStream.Write("Image", store);
// Run the pipeline asynchronously
p.RunAsync();
Console.WriteLine("Press any key to stop recording...");
Console.ReadKey();
}Since the MediaCapture class is an infinite source and it is the only source component, the pipeline will continue running indefinitely. Note that the example uses the asynchronous Pipeline.RunAsync() method to start the pipeline, then waits for console input to stop the pipeline by falling out of the using block and disposing the pipeline object, which causes pipeline execution to terminate gracefully. Had we instead used the Pipeline.Run() method which blocks for as long as the pipeline is running, we would have no way of stopping the pipeline, short of terminating the process. If the application is then forcefully terminated via the OS, it would result in a corrupted output store due to files not being properly flushed. Therefore, for live execution of a pipeline whose source components are all infinite (most sensors are), the recommended pattern is to run the pipeline asynchronously using the RunAsync() method, and terminate the execution by disposing the pipeline (this occurs implicitly in the preceding example when exiting the using block, but could also be done via an explicit call to p.Dispose()).
The following is another example showing how to start and stop a live pipeline via separate UI element event handlers:
// Store a reference to the pipeline
private Pipeline pipeline;
void StartButton_Click(object sender, RoutedEventArgs e)
{
// Create the pipeline and save a reference to it
this.pipeline = Pipeline.Create();
// Configure the pipeline here, wire components, etc...
// Run the pipeline
this.pipeline.RunAsync();
}
void StopButton_Click(object sender, RoutedEventArgs e)
{
if (this.pipeline != null)
{
// Dispose the pipeline to stop it
this.pipeline.Dispose();
this.pipeline = null;
}
}Here we create, configure and start the pipeline in the start button event handler, running it by calling the RunAsync() method so that the event handler returns once the pipeline has started executing. By keeping a reference to the running pipeline, we can then stop it by calling its Dispose() method as shown in the stop button event handler.
In data replay mode, we are generally playing back streams from an existing finite source, such as a store. In this case, the pipeline will contain one or more source components which generate a fixed amount of data. In the example below, we have previously recorded some data to a store, and want to replay this data in a pipeline for further processing:
using (var p = Pipeline.Create())
{
// Open the store
var store = PsiStore.Open(p, "demo", "c:\\recordings");
// Open the saved stream
var jpegImageStream = store.OpenStream<Shared<EncodedImage>>("Image");
// Decode the image
var imageStream = jpegImageStream.Decode();
// Resize the image
var resizedImageStream = imageStream.Resize(640, 480);
// Run the pipeline
p.Run();
}In this case, the store component is a finite source of type Importer that allows opening and playback of recorded streams. The data in these streams will have been previously written to the store by some other \psi application. Note the use of the Run() method, which blocks for as long as the pipeline is running. Since the store is a finite source component, it will stop producing messages once all the stream messages have been read from the store. As there are no other source components, once this happens the pipeline will terminate. It is also permissible to use the RunAsync() method to run the pipeline asynchronously. In this case, the pipeline will run to completion in the background and terminate once all store messages have been processed.
As we have seen above, the execution of a running pipeline can be stopped by explicitly calling the Dispose() method. In some cases however a pipeline may terminate automatically, by itself. When and whether a pipeline terminates automatically, is determined by the nature of the source components in the pipeline. Specifically, we have three cases:
-
If a pipeline contains only infinite source components (e.g. live sensors): In this case, as we have seen in the discussion from the first section, the pipeline will run indefinitely, and only terminate when the
Dispose()method is called. -
If a pipeline contains only finite source components (e.g. Importers reading from stores): In this case the pipeline will automatically terminate once all of its finite source components have finished posting their final messages. A finite source component notifies the pipeline that it will post no further messages beyond a certain originating time by calling the
notifyCompletionTimedelegate with the originating time of its final message. This may be done after the final message has been posted, or once the originating time of the final message is known (see more details on authoring source components in the Writing Components topic). -
If the pipeline contains both finite and infinite source components, it will shutdown once all finite sources have notified completion as described above, behaving like in case 2 above (the infinite source components will be notified to stop once all finite components have notified completion).
Once all finite source components have notified their completion times, the pipeline will initiate shutdown, allowing any remaining messages that may be in flight to drain from the pipeline while discarding any further messages with originating times that occur after the latest finite source component completion time. Note however that shutdown may be initiated at any time by disposing the pipeline.
Source components implement a Stop() method which is called when the pipeline is shutting down. This gives each source component (whether finite or infinite) a chance to post its final messages up to and including the finalOriginatingTime, after which it should call the notifyCompleted delegate (passed to its Stop() method) to notify the pipeline that it is done posting messages. Refer to the Writing Components topic for more details on implementing source components.
When doing data replay, pipeline execution may be further controlled using replay descriptors. A ReplayDescriptor object may be supplied as an argument to the Run() or RunAsync() methods.
The ReplayDescriptor.Interval property defines the time interval in which the pipeline is to be executed. This allows users to select only a subset of messages from a pre-recorded store when replaying data. For example, the following pipeline replays only messages that have originating timestamps within the [12:01 ~ 12:04] interval, ignoring all messages captured before 12:01 and after 12:04.
using (var p = Pipeline.Create())
{
// Open the store
var store = PsiStore.Open(p, "demo", "c:\\recordings");
// Open the saved stream
var jpegImageStream = store.OpenStream<Shared<EncodedImage>>("Image");
// Decode the image
var imageStream = jpegImageStream.Decode();
// Resize the image
var resizedImageStream = imageStream.Resize(640, 480);
// Create replay descriptor
var startTime = new DateTime(DateTime.Today.Year, DateTime.Today.Month, DateTime.Today.Day, 12, 01, 00);
var endTime = new DateTime(DateTime.Today.Year, DateTime.Today.Month, DateTime.Today.Day, 12, 04, 00);
var replay = new ReplayDescriptor(startTime, endTime);
// Run the pipeline
p.Run(replay);By default, if we call p.Run() without supplying a replay descriptor, all messages in the selected streams will be replayed. This is equivalent to supplying a null replay descriptor or a replay descriptor with a time interval of TimeInterval.Infinite.
For convenience, the Pipeline class also provides several overloads for the Run() and RunAsync() methods that take either a replayInterval argument, or a replayStartTime and replayEndTime. So the Run statement in the previous example could simply have been written as: Run(startTime, endTime).
The EnforceReplayClock parameter of the ReplayDescriptor controls whether or not the pipeline clock is to be enforced when replaying messages from a store or with generated originating times.
If set to true, source messages (generated or read from a store) will not be delivered to downstream components until the pipeline clock has advanced to the message originating time. This ensures that the source messages flow at approximately the same rate at which they were recorded. This mode of pipeline execution enables simulation of a live pipeline using recorded data by replacing live sensor components in the pipeline with corresponding streams imported from a previously recorded data store. This is the default behavior if a replay descriptor is not supplied.
// Runs the pipeline with replay clock enforcement
p.Run(new ReplayDescriptor(startTime, endTime, true));If EnforceReplayClock is set to false, messages are delivered as soon as possible irrespective of their originating times. This causes the pipeline to proceed as fast as possible, even though the originating source messages may span a longer time interval. This mode is typically used in re-processing pipelines that are not time-sensitive, i.e., where previously recorded data is used as input to a computational graph without the requirement that the data be injected based on their originating times.
Overloads for the Run() and RunAsync() methods that take an enforceReplayClock argument are also available.
Two predefined replay descriptors are provided as static members of the ReplayDescriptor class:
-
ReplayDescriptor.ReplayAll: Replays all messages as soon as they are available without enforcing the replay clock. Equivalent tonew ReplayDescriptor(TimeInterval.Infinite, false). -
ReplayDescriptor.ReplayAllRealTime: Replays all messages in real time by enforcing replay clock. Equivalent tonew ReplayDescriptor(TimeInterval.Infinite, true).
When no replay descriptor is supplied to the Run() or RunAsync(), the default ReplayDescriptor.ReplayAllRealTime is used.
The Pipeline class provides the following events which may be used to notify applications or components when pipeline execution begins and ends:
-
Pipeline.PipelineRun: Event that is raised when the pipeline starts running, but before any messages are posted. ThePipelineRunEventArgsclass provides the arguments of the event to the event handler. -
Pipeline.PipelineCompleted: Event that is raised upon pipeline completion, after all components have been stopped and messages are no longer being produced.
// Perform an action when the pipeline starts running
p.PipelineRun += (s, e) => Console.WriteLine($"Pipeline started at {e.StartTime}");
// Perform an action when the pipeline completes
p.PipelineCompleted += (s, e) => Console.WriteLine($"Pipeline execution completed at {e.CompletedOriginatingTime}");An optional IProgress<double> object may be supplied to the Run() and RunAsync() methods to enable progress reports (progress is reported in the range 0.0 to 1.0 where 1.0 represents pipeline completion). The progress reporting frequency may be changed by setting the Pipeline.ProgressReportInterval property prior to running the pipeline.
A running pipeline may encounter exceptions thrown by its components. The way such exceptions surface is different depending on whether the pipeline was run synchronously or asynchronously.
When the pipeline is started by calling one of its synchronous Run() methods, any exceptions thrown by its components' receiver methods will cause the pipeline to terminate immediately. The exceptions will be wrapped in an AggregateException, which will then be thrown by the Run() method and may be caught and handled in a try-catch block.
try
{
p.Run();
}
catch (AggregateException e)
{
// handle exception
}If the pipeline is started asynchronously by calling one of its RunAsync() methods, we cannot use a try-catch block to handle any exceptions thrown since the RunAsync() method returns immediately after the pipeline starts running in the background. Should an error occur in one of the pipeline components' receiver methods running in the background, the resulting exception could cause the application to terminate abruptly.
To address this, the Pipeline class provides the PipelineExceptionNotHandled event to which a handler may be attached to be notified of any exceptions which may be thrown during pipeline execution. While the pipeline will still terminate, this will suppress any exceptions at the time they are thrown and thus allow the pipeline to terminate gracefully. Note that this event may be raised multiple times if multiple exceptions are thrown.
// Attach exception handler to handle pipeline exceptions
p.PipelineExceptionNotHandled += (s, e) => Console.WriteLine(e.Exception);
// Run asynchronously - exception handler will be notified of any exceptions
p.RunAsync()It should also be noted that attaching a handler to the PipelineExceptionNotHandled event in this way will also suppress any AggregateException that would otherwise have been thrown if the pipeline was executed using the Pipeline.Run() method.
Below, we discuss in more depth a couple of more advanced topics regarding the pipeline clock and the effect of replay mode on message latencies.
Time is a fundamental construct in multimodal, streaming systems, and \psi pipelines implement their own internal clock and notion of time. The Pipeline class provides the GetCurrentTime() method that returns the current pipeline time in UTC while the pipeline is running. Depending on whether the pipeline is in live or replay mode, the pipeline clock may or may not correspond to the wall-clock time in the real world.
When running live, the pipeline's clock corresponds to the real-world clock. However, when running in replay the pipeline clock emulates the time when the source streams were collected. When streams are saved to a store in \psi, the message envelopes are serialized along with the data. When data is replayed from a store, the stream messages will bear the timestamps from when they were originally recorded. This affects the pipeline time when it is run in replay mode (or, more generally, whenever the pipeline contains one or more source components that generate data within a predefined time interval). In these situations, the pipeline's clock is initialized to the earliest originating time of any message that may be read from a store or generated by a component within the pipeline. The Pipeline.StartTime read-only property will reflect this time after the pipeline is started.
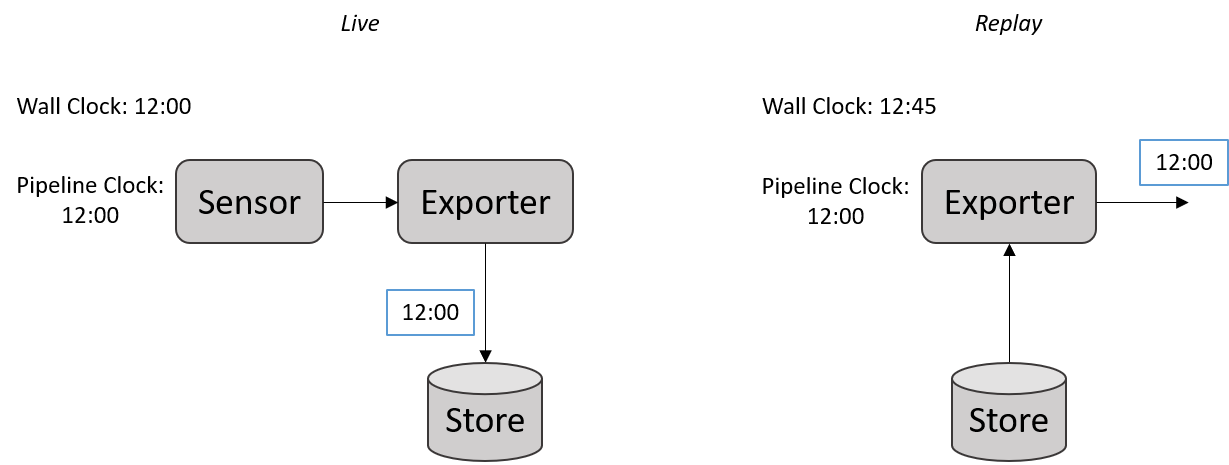
Because the pipeline's start time must be determined before the pipeline starts running and before messages begin to flow, source components may declare the time interval spanning the originating times of the data that they will produce by calling the Pipeline.ProposeReplayTime() method at creation time. If there are multiple such components within a pipeline, the final proposed pipeline replay interval will be the time span that covers all proposed replay times.
In live pipelines, we often infer message processing latencies by measuring the difference between the message envelope (creation) time and its originating time. Recall that the originating time of a message is the real-world time at which the event which produced the message occurred. This originating time is maintained and propagated downstream as the message flows through subsequent processing components in the pipeline. The message creation time (Envelope.CreationTime) on the other hand reflects the pipeline time at which the message was created and posted to the next downstream component. Since pipeline time progresses in real-time in a live pipeline, the difference between the message creation time and its originating time is the total time elapsed since the production of the original message and thus represents the cumulative processing delay of all interstitial processing components.

When replaying from a store with replay clock enforcement, the situation is essentially the same as in live mode. While messages may be read from a store (or generated) very quickly, the runtime will not deliver these messages until they are due based on their originating times. Hence, messages flow as though they were in a live pipeline and latencies may be inferred from the envelope times.
However in replay mode without clock enforcement, messages are posted as soon as they are read from a store (or generated). The time at which a message is posted will be the current time reflected by the pipeline clock, which may not have advanced by much since the start of execution. As such, one cannot infer processing latencies merely by comparing message envelope times with originating times. Indeed, it is quite common for message creation times to occur before their originating times, resulting in negative "latencies". Therefore it is not possible to measure latencies from the message envelopes when running in replay mode without clock enforcement.
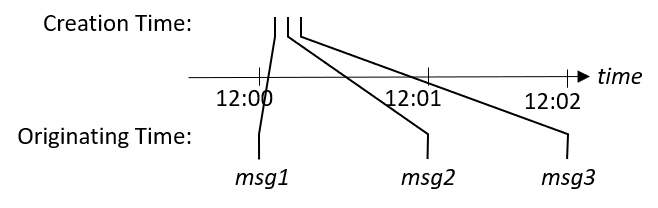
The exception to this are the messages read from the store by the Importer. Since envelopes are serialized when messages are written to the store, the original message envelope bearing both originating and creation times from when the message was originally written will be preserved.